 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting GPT-3 To Be Reliable
Oct 17, 2022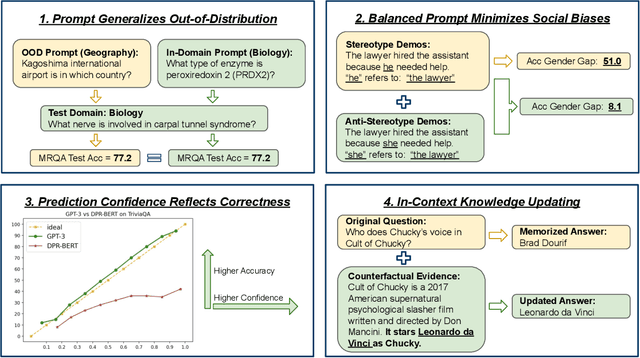

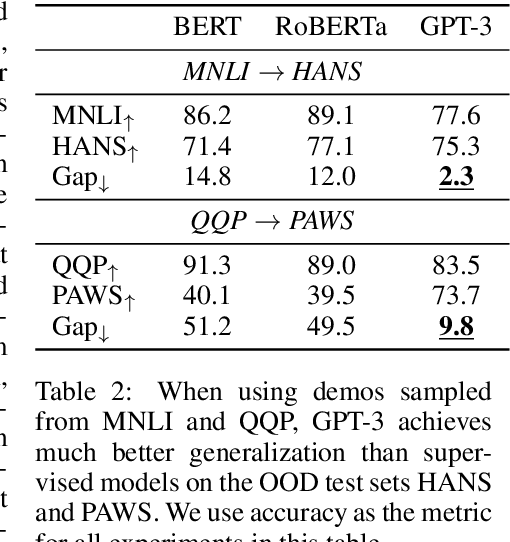

Large language models (LLMs) show impressive abilities via few-shot prompting. Commercialized APIs such as OpenAI GPT-3 further increase their use in real-world language applications. However, existing research focuses on models' accuracy on standard benchmarks and largely ignores their reliability, which is crucial for avoiding catastrophic real-world harms. While reliability is a broad and vaguely defined term, this work decomposes reliability into four facets: generalizability, fairness, calibration, and factuality. We establish simple and effective prompts to demonstrate GPT-3's reliability in these four aspects: 1) generalize out-of-domain, 2) balance demographic distribution to reduce social biases, 3) calibrate language model probabilities, and 4) update the LLM's knowledge. We find that by employing appropriate prompts, GPT-3 outperforms smaller-scale supervised models by large margins on all these facets. We release all processed datasets, evaluation scripts, and model predictions to facilitate future analysis. Our findings not only shed new insights on the reliability of prompting LLMs, but more importantly, our prompting strategies can help practitioners more reliably use large language models like GPT-3.
An Empirical Study of End-to-End Video-Language Transformers with Masked Visual Modeling
Sep 04, 2022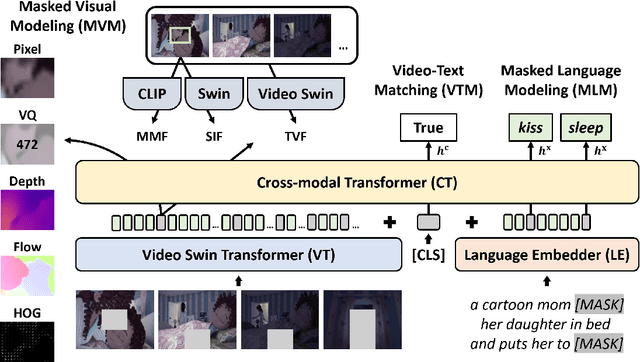
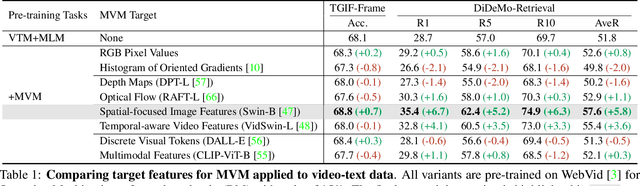
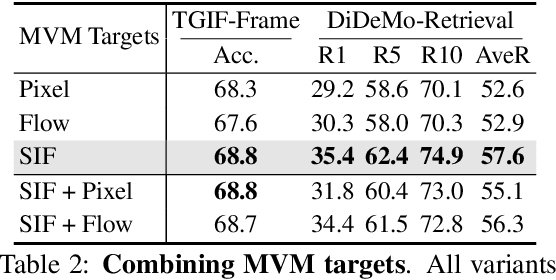

Masked visual modeling (MVM) has been recently proven effective for visual pre-training. While similar reconstructive objectives on video inputs (e.g., masked frame modeling) have been explored in video-language (VidL) pre-training, the pre-extracted video features in previous studies cannot be refined through MVM during pre-training, and thus leading to unsatisfactory downstream performance. In this work, we systematically examine the potential of MVM in the context of VidL learning. Specifically, we base our study on a fully end-to-end VIdeO-LanguagE Transformer (VIOLET), which mitigates the disconnection between fixed video representations and MVM training. In total, eight different reconstructive targets of MVM are explored, from low-level pixel values and oriented gradients to high-level depth maps, optical flow, discrete visual tokens and latent visual features. We conduct comprehensive experiments and provide insights on the factors leading to effective MVM training. Empirically, we show VIOLET pre-trained with MVM objective achieves notable improvements on 13 VidL benchmarks, ranging from video question answering, video captioning, to text-to-video retrieval.
NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis
Jul 20, 2022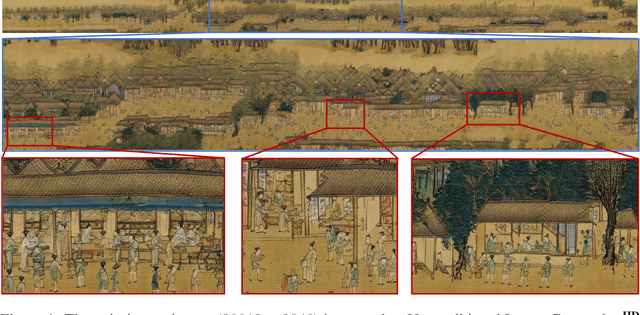
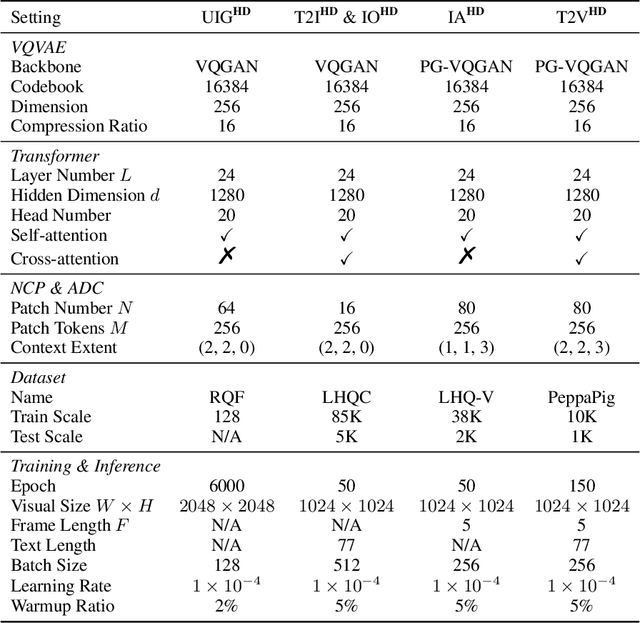


In this paper, we present NUWA-Infinity, a generative model for infinite visual synthesis, which is defined as the task of generating arbitrarily-sized high-resolution images or long-duration videos. An autoregressive over autoregressive generation mechanism is proposed to deal with this variable-size generation task, where a global patch-level autoregressive model considers the dependencies between patches, and a local token-level autoregressive model considers dependencies between visual tokens within each patch. A Nearby Context Pool (NCP) is introduced to cache-related patches already generated as the context for the current patch being generated, which can significantly save computation costs without sacrificing patch-level dependency modeling. An Arbitrary Direction Controller (ADC) is used to decide suitable generation orders for different visual synthesis tasks and learn order-aware positional embeddings. Compared to DALL-E, Imagen and Parti, NUWA-Infinity can generate high-resolution images with arbitrary sizes and support long-duration video generation additionally. Compared to NUWA, which also covers images and videos, NUWA-Infinity has superior visual synthesis capabilities in terms of resolution and variable-size generation. The GitHub link is https://github.com/microsoft/NUWA. The homepage link is https://nuwa-infinity.microsoft.com.
Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
Jun 15, 2022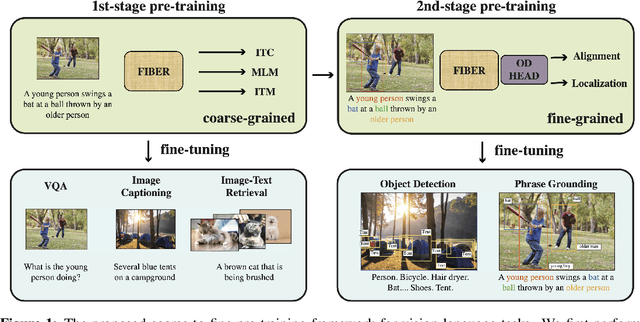

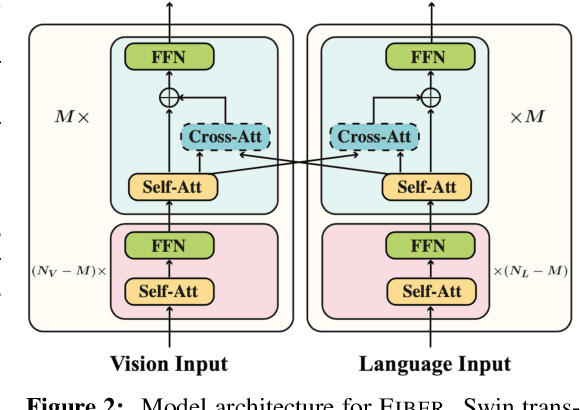
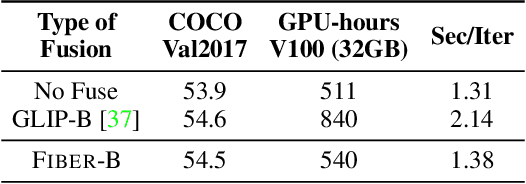
Vision-language (VL) pre-training has recently received considerable attention. However, most existing end-to-end pre-training approaches either only aim to tackle VL tasks such as image-text retrieval, visual question answering (VQA) and image captioning that test high-level understanding of images, or only target region-level understanding for tasks such as phrase grounding and object detection. We present FIBER (Fusion-In-the-Backbone-based transformER), a new VL model architecture that can seamlessly handle both these types of tasks. Instead of having dedicated transformer layers for fusion after the uni-modal backbones, FIBER pushes multimodal fusion deep into the model by inserting cross-attention into the image and text backbones, bringing gains in terms of memory and performance. In addition, unlike previous work that is either only pre-trained on image-text data or on fine-grained data with box-level annotations, we present a two-stage pre-training strategy that uses both these kinds of data efficiently: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data. We conduct comprehensive experiments on a wide range of VL tasks, ranging from VQA, image captioning, and retrieval, to phrase grounding, referring expression comprehension, and object detection. Using deep multimodal fusion coupled with the two-stage pre-training, FIBER provides consistent performance improvements over strong baselines across all tasks, often outperforming methods using magnitudes more data. Code is available at https://github.com/microsoft/FIBER.
LAVENDER: Unifying Video-Language Understanding as Masked Language Modeling
Jun 14, 2022
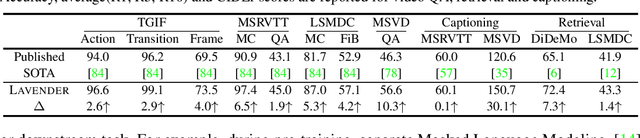
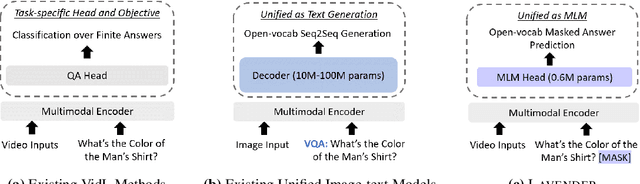
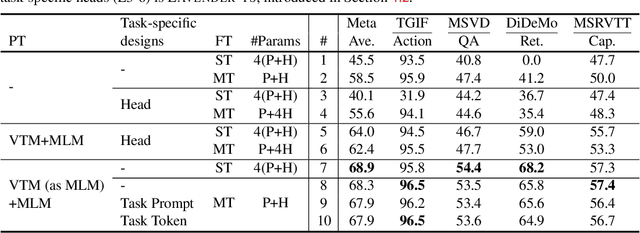
Unified vision-language frameworks have greatly advanced in recent years, most of which adopt an encoder-decoder architecture to unify image-text tasks as sequence-to-sequence generation. However, existing video-language (VidL) models still require task-specific designs in model architecture and training objectives for each task. In this work, we explore a unified VidL framework LAVENDER, where Masked Language Modeling (MLM) is used as the common interface for all pre-training and downstream tasks. Such unification leads to a simplified model architecture, where only a lightweight MLM head, instead of a decoder with much more parameters, is needed on top of the multimodal encoder. Surprisingly, experimental results show that this unified framework achieves competitive performance on 14 VidL benchmarks, covering video question answering, text-to-video retrieval and video captioning. Extensive analyses further demonstrate the advantage of LAVENDER over existing VidL methods in: (i) supporting all downstream tasks with just a single set of parameter values when multi-task finetuned; (ii) few-shot generalization on various downstream tasks; and (iii) enabling zero-shot evaluation on video question answering tasks. Code is available at https://github.com/microsoft/LAVENDER.
GIT: A Generative Image-to-text Transformer for Vision and Language
May 31, 2022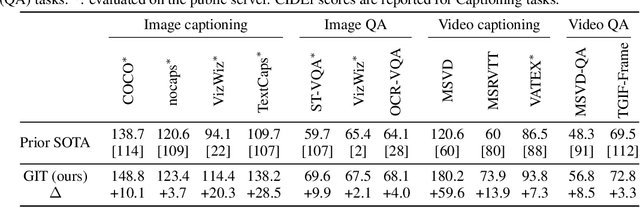

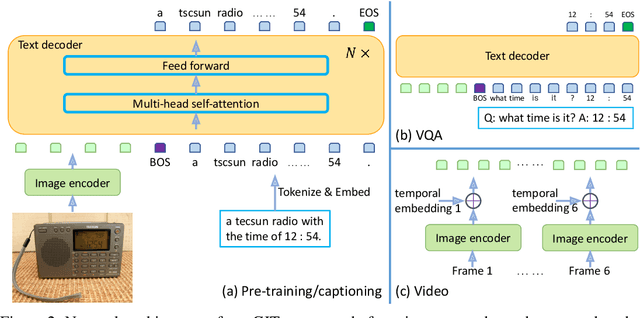
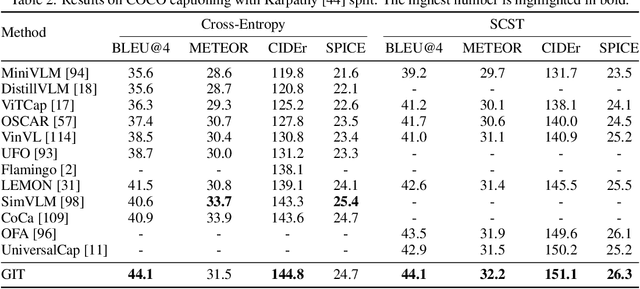
In this paper, we design and train a Generative Image-to-text Transformer, GIT, to unify vision-language tasks such as image/video captioning and question answering. While generative models provide a consistent network architecture between pre-training and fine-tuning, existing work typically contains complex structures (uni/multi-modal encoder/decoder) and depends on external modules such as object detectors/taggers and optical character recognition (OCR). In GIT, we simplify the architecture as one image encoder and one text decoder under a single language modeling task. We also scale up the pre-training data and the model size to boost the model performance. Without bells and whistles, our GIT establishes new state of the arts on 12 challenging benchmarks with a large margin. For instance, our model surpasses the human performance for the first time on TextCaps (138.2 vs. 125.5 in CIDEr). Furthermore, we present a new scheme of generation-based image classification and scene text recognition, achieving decent performance on standard benchmarks.
K-LITE: Learning Transferable Visual Models with External Knowledge
Apr 20, 2022
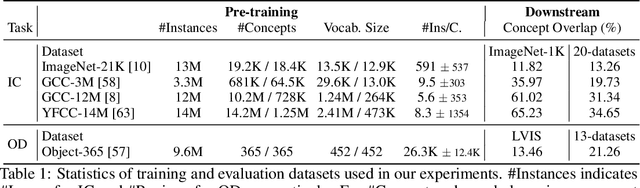
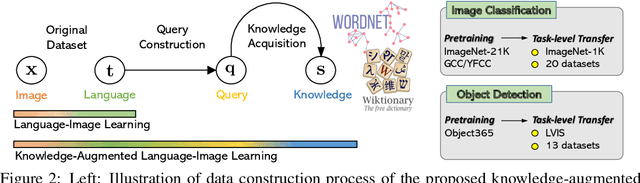
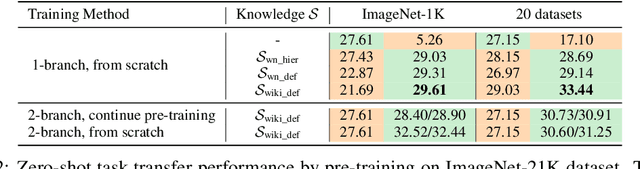
Recent state-of-the-art computer vision systems are trained from natural language supervision, ranging from simple object category names to descriptive captions. This free form of supervision ensures high generality and usability of the learned visual models, based on extensive heuristics on data collection to cover as many visual concepts as possible. Alternatively, learning with external knowledge about images is a promising way which leverages a much more structured source of supervision. In this paper, we propose K-LITE (Knowledge-augmented Language-Image Training and Evaluation), a simple strategy to leverage external knowledge to build transferable visual systems: In training, it enriches entities in natural language with WordNet and Wiktionary knowledge, leading to an efficient and scalable approach to learning image representations that can understand both visual concepts and their knowledge; In evaluation, the natural language is also augmented with external knowledge and then used to reference learned visual concepts (or describe new ones) to enable zero-shot and few-shot transfer of the pre-trained models. We study the performance of K-LITE on two important computer vision problems, image classification and object detection, benchmarking on 20 and 13 different existing datasets, respectively. The proposed knowledge-augmented models show significant improvement in transfer learning performance over existing methods.
Injecting Semantic Concepts into End-to-End Image Captioning
Dec 09, 2021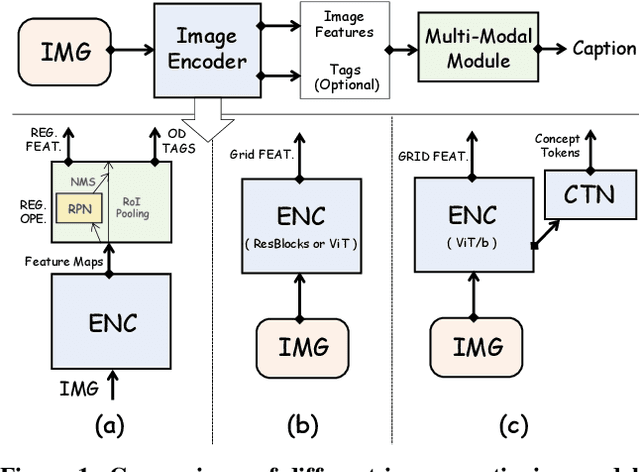
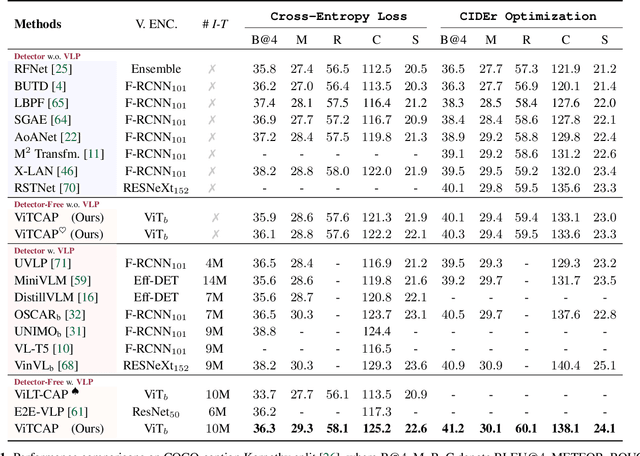
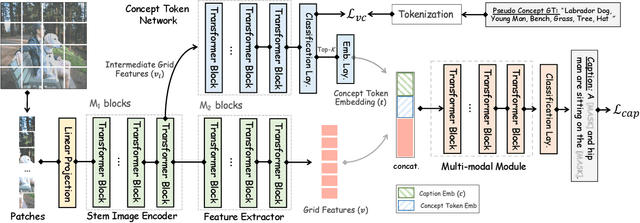
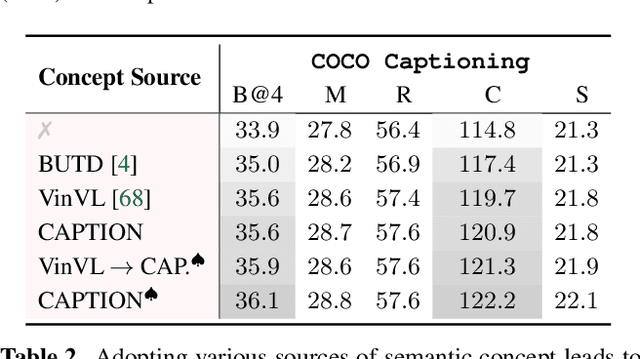
Tremendous progress has been made in recent years in developing better image captioning models, yet most of them rely on a separate object detector to extract regional features. Recent vision-language studies are shifting towards the detector-free trend by leveraging grid representations for more flexible model training and faster inference speed. However, such development is primarily focused on image understanding tasks, and remains less investigated for the caption generation task. In this paper, we are concerned with a better-performing detector-free image captioning model, and propose a pure vision transformer-based image captioning model, dubbed as ViTCAP, in which grid representations are used without extracting the regional features. For improved performance, we introduce a novel Concept Token Network (CTN) to predict the semantic concepts and then incorporate them into the end-to-end captioning. In particular, the CTN is built on the basis of a vision transformer and is designed to predict the concept tokens through a classification task, from which the rich semantic information contained greatly benefits the captioning task. Compared with the previous detector-based models, ViTCAP drastically simplifies the architectures and at the same time achieves competitive performance on various challenging image captioning datasets. In particular, ViTCAP reaches 138.1 CIDEr scores on COCO-caption Karpathy-split, 93.8 and 108.6 CIDEr scores on nocaps, and Google-CC captioning datasets, respectively.
MLP Architectures for Vision-and-Language Modeling: An Empirical Study
Dec 08, 2021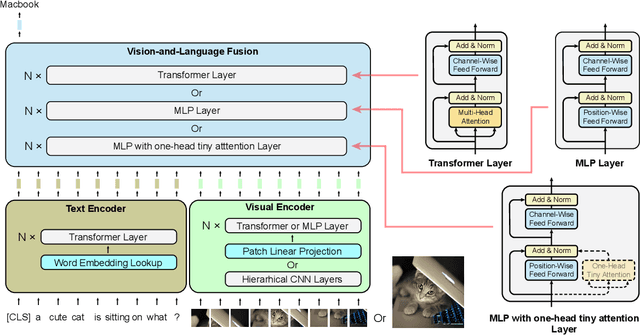
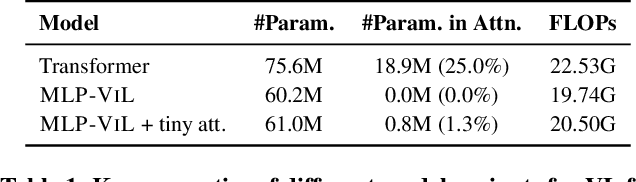
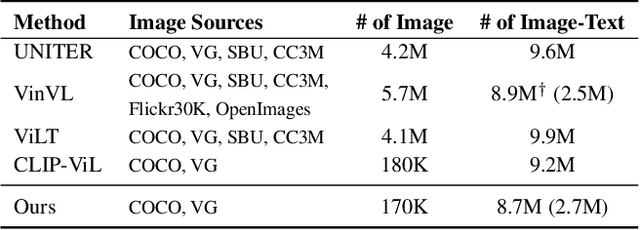
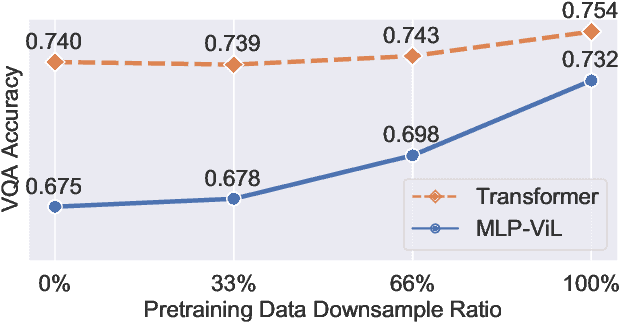
We initiate the first empirical study on the use of MLP architectures for vision-and-language (VL) fusion. Through extensive experiments on 5 VL tasks and 5 robust VQA benchmarks, we find that: (i) Without pre-training, using MLPs for multimodal fusion has a noticeable performance gap compared to transformers; (ii) However, VL pre-training can help close the performance gap; (iii) Instead of heavy multi-head attention, adding tiny one-head attention to MLPs is sufficient to achieve comparable performance to transformers. Moreover, we also find that the performance gap between MLPs and transformers is not widened when being evaluated on the harder robust VQA benchmarks, suggesting using MLPs for VL fusion can generalize roughly to a similar degree as using transformers. These results hint that MLPs can effectively learn to align vision and text features extracted from lower-level encoders without heavy reliance on self-attention. Based on this, we ask an even bolder question: can we have an all-MLP architecture for VL modeling, where both VL fusion and the vision encoder are replaced with MLPs? Our result shows that an all-MLP VL model is sub-optimal compared to state-of-the-art full-featured VL models when both of them get pre-trained. However, pre-training an all-MLP can surprisingly achieve a better average score than full-featured transformer models without pre-training. This indicates the potential of large-scale pre-training of MLP-like architectures for VL modeling and inspires the future research direction on simplifying well-established VL modeling with less inductive design bias. Our code is publicly available at: https://github.com/easonnie/mlp-vil
SwinBERT: End-to-End Transformers with Sparse Attention for Video Captioning
Nov 25, 2021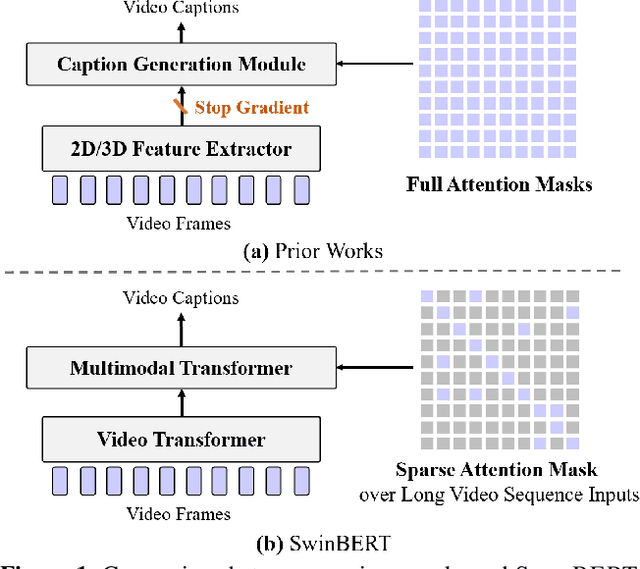

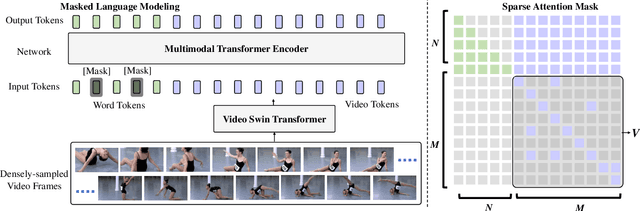
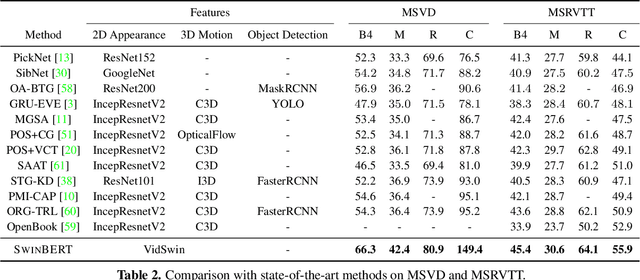
The canonical approach to video captioning dictates a caption generation model to learn from offline-extracted dense video features. These feature extractors usually operate on video frames sampled at a fixed frame rate and are often trained on image/video understanding tasks, without adaption to video captioning data. In this work, we present SwinBERT, an end-to-end transformer-based model for video captioning, which takes video frame patches directly as inputs, and outputs a natural language description. Instead of leveraging multiple 2D/3D feature extractors, our method adopts a video transformer to encode spatial-temporal representations that can adapt to variable lengths of video input without dedicated design for different frame rates. Based on this model architecture, we show that video captioning can benefit significantly from more densely sampled video frames as opposed to previous successes with sparsely sampled video frames for video-and-language understanding tasks (e.g., video question answering). Moreover, to avoid the inherent redundancy in consecutive video frames, we propose adaptively learning a sparse attention mask and optimizing it for task-specific performance improvement through better long-range video sequence modeling. Through extensive experiments on 5 video captioning datasets, we show that SwinBERT achieves across-the-board performance improvements over previous methods, often by a large margin. The learned sparse attention masks in addition push the limit to new state of the arts, and can be transferred between different video lengths and between different datasets.