 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyMoE: Dynamic Expert Orchestration with Mixed-Precision Quantization for Efficient MoE Inference on Edge
Mar 19, 2026Despite the computational efficiency of MoE models, the excessive memory footprint and I/O overhead inherent in multi-expert architectures pose formidable challenges for real-time inference on resource-constrained edge platforms. While existing static methods struggle with a rigid latency-accuracy trade-off, we observe that expert importance is highly skewed and depth-dependent. Motivated by these insights, we propose DyMoE, a dynamic mixed-precision quantization framework designed for high-performance edge inference. Leveraging insights into expert importance skewness and depth-dependent sensitivity, DyMoE introduces: (1) importance-aware prioritization to dynamically quantize experts at runtime; (2) depth-adaptive scheduling to preserve semantic integrity in critical layers; and (3) look-ahead prefetching to overlap I/O stalls. Experimental results on commercial edge hardware show that DyMoE reduces Time-to-First-Token (TTFT) by 3.44x-22.7x and up to a 14.58x speedup in Time-Per-Output-Token (TPOT) compared to state-of-the-art offloading baselines, enabling real-time, accuracy-preserving MoE inference on resource-constrained edge devices.
FSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
Accurate Expert Predictions in MoE Inference via Cross-Layer Gate
Feb 17, 2025



Large Language Models (LLMs) have demonstrated impressive performance across various tasks, and their application in edge scenarios has attracted significant attention. However, sparse-activated Mixture-of-Experts (MoE) models, which are well suited for edge scenarios, have received relatively little attention due to their high memory demands. Offload-based methods have been proposed to address this challenge, but they face difficulties with expert prediction. Inaccurate expert predictions can result in prolonged inference delays. To promote the application of MoE models in edge scenarios, we propose Fate, an offloading system designed for MoE models to enable efficient inference in resource-constrained environments. The key insight behind Fate is that gate inputs from adjacent layers can be effectively used for expert prefetching, achieving high prediction accuracy without additional GPU overhead. Furthermore, Fate employs a shallow-favoring expert caching strategy that increases the expert hit rate to 99\%. Additionally, Fate integrates tailored quantization strategies for cache optimization and IO efficiency. Experimental results show that, compared to Load on Demand and Expert Activation Path-based method, Fate achieves up to 4.5x and 1.9x speedups in prefill speed and up to 4.1x and 2.2x speedups in decoding speed, respectively, while maintaining inference quality. Moreover, Fate's performance improvements are scalable across different memory budgets.
Klotski: Efficient Mixture-of-Expert Inference via Expert-Aware Multi-Batch Pipeline
Feb 09, 2025



Mixture of Experts (MoE), with its distinctive sparse structure, enables the scaling of language models up to trillions of parameters without significantly increasing computational costs. However, the substantial parameter size presents a challenge for inference, as the expansion in GPU memory cannot keep pace with the growth in parameters. Although offloading techniques utilise memory from the CPU and disk and parallelise the I/O and computation for efficiency, the computation for each expert in MoE models is often less than the I/O, resulting in numerous bubbles in the pipeline. Therefore, we propose Klotski, an efficient MoE inference engine that significantly reduces pipeline bubbles through a novel expert-aware multi-batch pipeline paradigm. The proposed paradigm uses batch processing to extend the computation time of the current layer to overlap with the loading time of the next layer. Although this idea has been effectively applied to dense models, more batches may activate more experts in the MoE, leading to longer loading times and more bubbles. Thus, unlike traditional approaches, we balance computation and I/O time and minimise bubbles by orchestrating their inference orders based on their heterogeneous computation and I/O requirements and activation patterns under different batch numbers. Moreover, to adapt to different hardware environments and models, we design a constraint-sensitive I/O-compute planner and a correlation-aware expert prefetcher for a schedule that minimises pipeline bubbles. Experimental results demonstrate that Klotski achieves a superior throughput-latency trade-off compared to state-of-the-art techniques, with throughput improvements of up to 85.12x.
Skews in the Phenomenon Space Hinder Generalization in Text-to-Image Generation
Mar 25, 2024



The literature on text-to-image generation is plagued by issues of faithfully composing entities with relations. But there lacks a formal understanding of how entity-relation compositions can be effectively learned. Moreover, the underlying phenomenon space that meaningfully reflects the problem structure is not well-defined, leading to an arms race for larger quantities of data in the hope that generalization emerges out of large-scale pretraining. We hypothesize that the underlying phenomenological coverage has not been proportionally scaled up, leading to a skew of the presented phenomenon which harms generalization. We introduce statistical metrics that quantify both the linguistic and visual skew of a dataset for relational learning, and show that generalization failures of text-to-image generation are a direct result of incomplete or unbalanced phenomenological coverage. We first perform experiments in a synthetic domain and demonstrate that systematically controlled metrics are strongly predictive of generalization performance. Then we move to natural images and show that simple distribution perturbations in light of our theories boost generalization without enlarging the absolute data size. This work informs an important direction towards quality-enhancing the data diversity or balance orthogonal to scaling up the absolute size. Our discussions point out important open questions on 1) Evaluation of generated entity-relation compositions, and 2) Better models for reasoning with abstract relations.
End-to-end Knowledge Retrieval with Multi-modal Queries
Jun 01, 2023



We investigate knowledge retrieval with multi-modal queries, i.e. queries containing information split across image and text inputs, a challenging task that differs from previous work on cross-modal retrieval. We curate a new dataset called ReMuQ for benchmarking progress on this task. ReMuQ requires a system to retrieve knowledge from a large corpus by integrating contents from both text and image queries. We introduce a retriever model ``ReViz'' that can directly process input text and images to retrieve relevant knowledge in an end-to-end fashion without being dependent on intermediate modules such as object detectors or caption generators. We introduce a new pretraining task that is effective for learning knowledge retrieval with multimodal queries and also improves performance on downstream tasks. We demonstrate superior performance in retrieval on two datasets (ReMuQ and OK-VQA) under zero-shot settings as well as further improvements when finetuned on these datasets.
Mining Unseen Classes via Regional Objectness: A Simple Baseline for Incremental Segmentation
Nov 15, 2022



Incremental or continual learning has been extensively studied for image classification tasks to alleviate catastrophic forgetting, a phenomenon that earlier learned knowledge is forgotten when learning new concepts. For class incremental semantic segmentation, such a phenomenon often becomes much worse due to the background shift, i.e., some concepts learned at previous stages are assigned to the background class at the current training stage, therefore, significantly reducing the performance of these old concepts. To address this issue, we propose a simple yet effective method in this paper, named Mining unseen Classes via Regional Objectness for Segmentation (MicroSeg). Our MicroSeg is based on the assumption that background regions with strong objectness possibly belong to those concepts in the historical or future stages. Therefore, to avoid forgetting old knowledge at the current training stage, our MicroSeg first splits the given image into hundreds of segment proposals with a proposal generator. Those segment proposals with strong objectness from the background are then clustered and assigned newly-defined labels during the optimization. In this way, the distribution characterizes of old concepts in the feature space could be better perceived, relieving the catastrophic forgetting caused by the background shift accordingly. Extensive experiments on Pascal VOC and ADE20K datasets show competitive results with state-of-the-art, well validating the effectiveness of the proposed MicroSeg.
Tragedy Plus Time: Capturing Unintended Human Activities from Weakly-labeled Videos
Apr 28, 2022
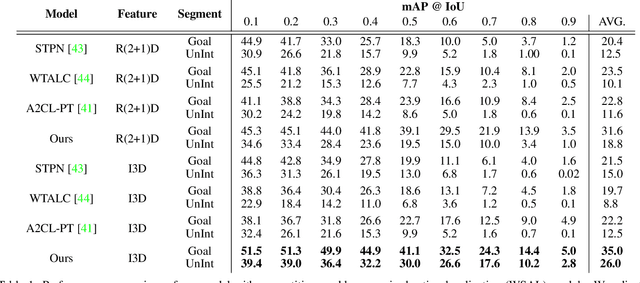
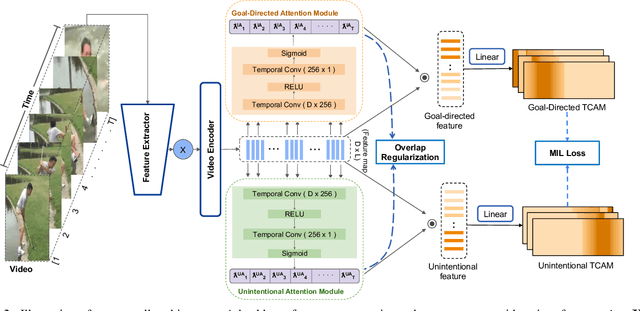
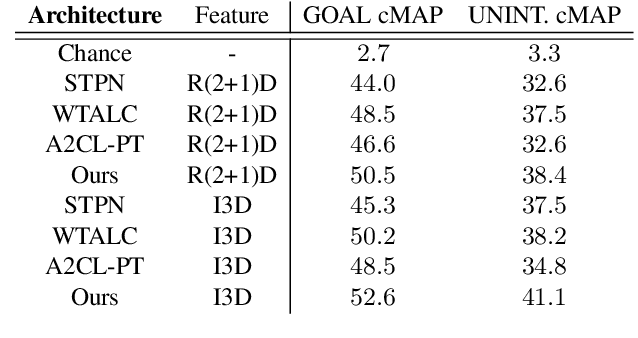
In videos that contain actions performed unintentionally, agents do not achieve their desired goals. In such videos, it is challenging for computer vision systems to understand high-level concepts such as goal-directed behavior, an ability present in humans from a very early age. Inculcating this ability in artificially intelligent agents would make them better social learners by allowing them to evaluate human action under a teleological lens. To validate the ability of deep learning models to perform this task, we curate the W-Oops dataset, built upon the Oops dataset [15]. W-Oops consists of 2,100 unintentional human action videos, with 44 goal-directed and 30 unintentional video-level activity labels collected through human annotations. Due to the expensive segment annotation procedure, we propose a weakly supervised algorithm for localizing the goal-directed as well as unintentional temporal regions in the video leveraging solely video-level labels. In particular, we employ an attention mechanism-based strategy that predicts the temporal regions which contribute the most to a classification task. Meanwhile, our designed overlap regularization allows the model to focus on distinct portions of the video for inferring the goal-directed and unintentional activity while guaranteeing their temporal ordering. Extensive quantitative experiments verify the validity of our localization method. We further conduct a video captioning experiment which demonstrates that the proposed localization module does indeed assist teleological action understanding.
Injecting Semantic Concepts into End-to-End Image Captioning
Dec 09, 2021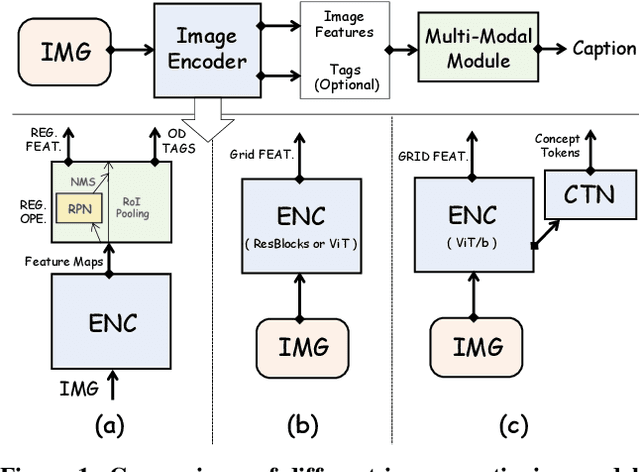
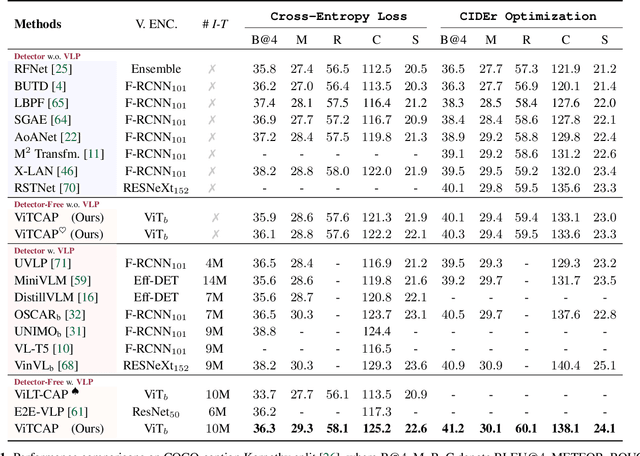
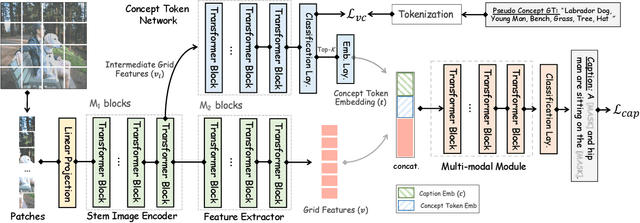
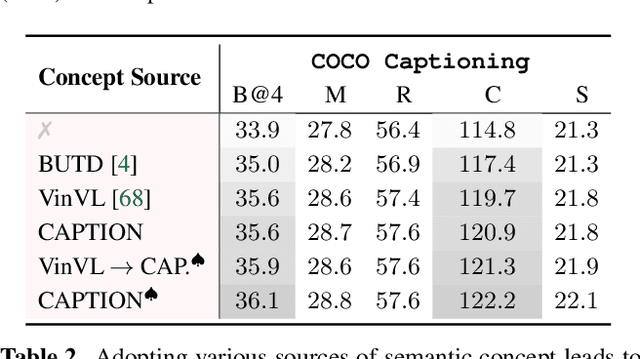
Tremendous progress has been made in recent years in developing better image captioning models, yet most of them rely on a separate object detector to extract regional features. Recent vision-language studies are shifting towards the detector-free trend by leveraging grid representations for more flexible model training and faster inference speed. However, such development is primarily focused on image understanding tasks, and remains less investigated for the caption generation task. In this paper, we are concerned with a better-performing detector-free image captioning model, and propose a pure vision transformer-based image captioning model, dubbed as ViTCAP, in which grid representations are used without extracting the regional features. For improved performance, we introduce a novel Concept Token Network (CTN) to predict the semantic concepts and then incorporate them into the end-to-end captioning. In particular, the CTN is built on the basis of a vision transformer and is designed to predict the concept tokens through a classification task, from which the rich semantic information contained greatly benefits the captioning task. Compared with the previous detector-based models, ViTCAP drastically simplifies the architectures and at the same time achieves competitive performance on various challenging image captioning datasets. In particular, ViTCAP reaches 138.1 CIDEr scores on COCO-caption Karpathy-split, 93.8 and 108.6 CIDEr scores on nocaps, and Google-CC captioning datasets, respectively.
Compressing Visual-linguistic Model via Knowledge Distillation
Apr 05, 2021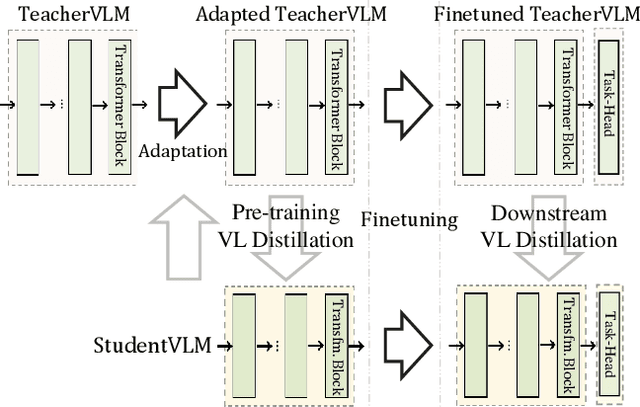
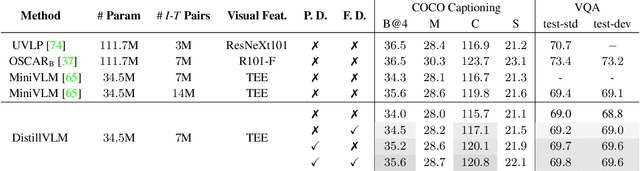
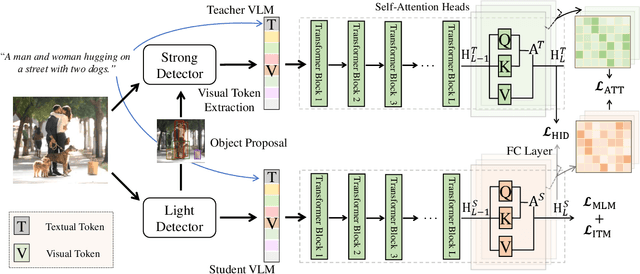
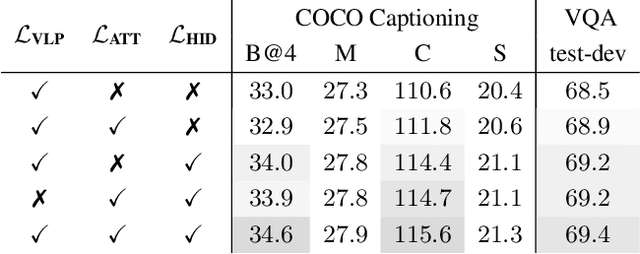
Despite exciting progress in pre-training for visual-linguistic (VL) representations, very few aspire to a small VL model. In this paper, we study knowledge distillation (KD) to effectively compress a transformer-based large VL model into a small VL model. The major challenge arises from the inconsistent regional visual tokens extracted from different detectors of Teacher and Student, resulting in the misalignment of hidden representations and attention distributions. To address the problem, we retrain and adapt the Teacher by using the same region proposals from Student's detector while the features are from Teacher's own object detector. With aligned network inputs, the adapted Teacher is capable of transferring the knowledge through the intermediate representations. Specifically, we use the mean square error loss to mimic the attention distribution inside the transformer block and present a token-wise noise contrastive loss to align the hidden state by contrasting with negative representations stored in a sample queue. To this end, we show that our proposed distillation significantly improves the performance of small VL models on image captioning and visual question answering tasks. It reaches 120.8 in CIDEr score on COCO captioning, an improvement of 5.1 over its non-distilled counterpart; and an accuracy of 69.8 on VQA 2.0, a 0.8 gain from the baseline. Our extensive experiments and ablations confirm the effectiveness of VL distillation in both pre-training and fine-tuning stages.