 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMDR: A Model Agnostic Learning Method for Multi-Domain Recommendation
Mar 22, 2022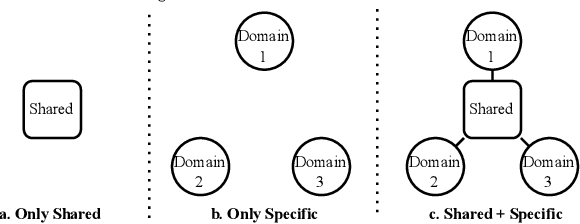
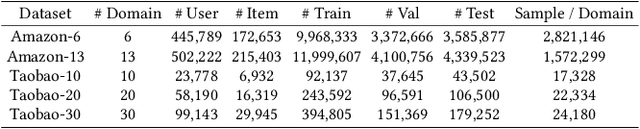
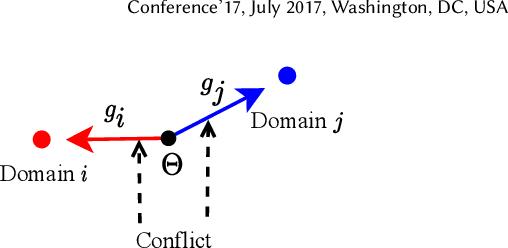
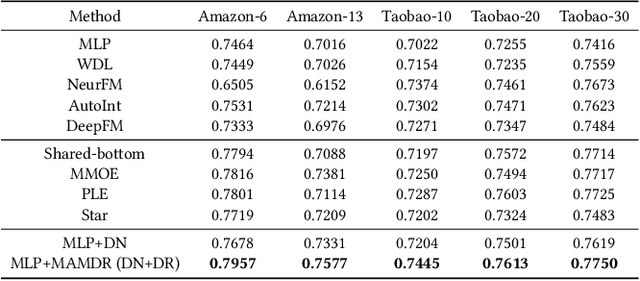
Large-scale e-commercial platforms in the real-world usually contain various recommendation scenarios (domains) to meet demands of diverse customer groups. Multi-Domain Recommendation (MDR), which aims to jointly improve recommendations on all domains, has attracted increasing attention from practitioners and researchers. Existing MDR methods often employ a shared structure to leverage reusable features for all domains and several specific parts to capture domain-specific information. However, data from different domains may conflict with each other and cause shared parameters to stay at a compromised position on the optimization landscape. This could deteriorate the overall performance. Despite the specific parameters are separately learned for each domain, they can easily overfit on data sparsity domains. Furthermore, data distribution differs across domains, making it challenging to develop a general model that can be applied to all circumstances. To address these problems, we propose a novel model agnostic learning method, namely MAMDR, for the multi-domain recommendation. Specifically, we first propose a Domain Negotiation (DN) strategy to alleviate the conflict between domains and learn better shared parameters. Then, we develop a Domain Regularization (DR) scheme to improve the generalization ability of specific parameters by learning from other domains. Finally, we integrate these components into a unified framework and present MAMDR which can be applied to any model structure to perform multi-domain recommendation. Extensive experiments on various real-world datasets and online applications demonstrate both the effectiveness and generalizability of MAMDR.
Community Trend Prediction on Heterogeneous Graph in E-commerce
Feb 24, 2022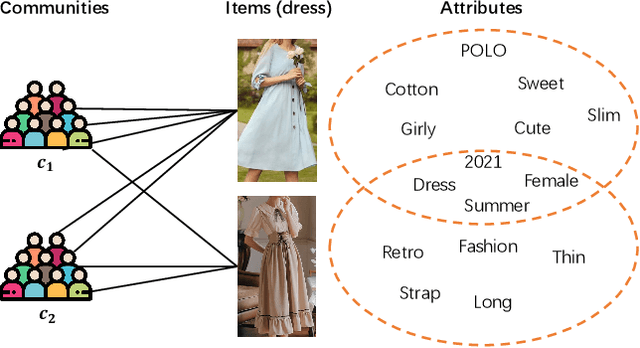
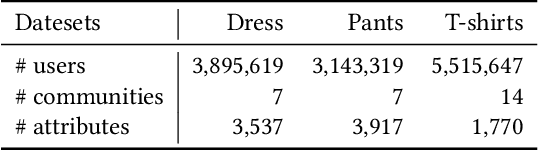
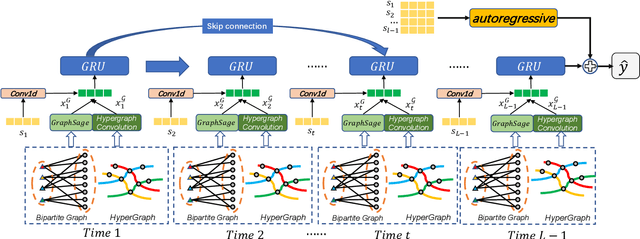
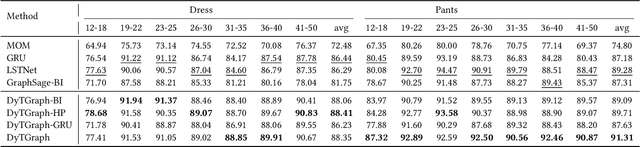
In online shopping, ever-changing fashion trends make merchants need to prepare more differentiated products to meet the diversified demands, and e-commerce platforms need to capture the market trend with a prophetic vision. For the trend prediction, the attribute tags, as the essential description of items, can genuinely reflect the decision basis of consumers. However, few existing works explore the attribute trend in the specific community for e-commerce. In this paper, we focus on the community trend prediction on the item attribute and propose a unified framework that combines the dynamic evolution of two graph patterns to predict the attribute trend in a specific community. Specifically, we first design a communityattribute bipartite graph at each time step to learn the collaboration of different communities. Next, we transform the bipartite graph into a hypergraph to exploit the associations of different attribute tags in one community. Lastly, we introduce a dynamic evolution component based on the recurrent neural networks to capture the fashion trend of attribute tags. Extensive experiments on three real-world datasets in a large e-commerce platform show the superiority of the proposed approach over several strong alternatives and demonstrate the ability to discover the community trend in advance.
GIFT: Graph-guIded Feature Transfer for Cold-Start Video Click-Through Rate Prediction
Feb 21, 2022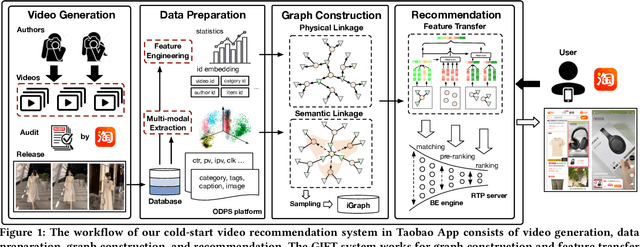
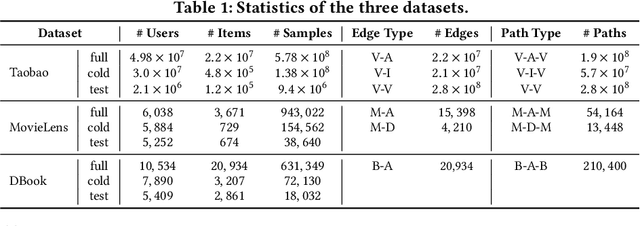
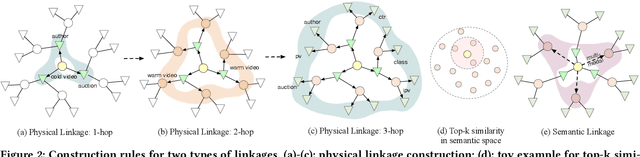
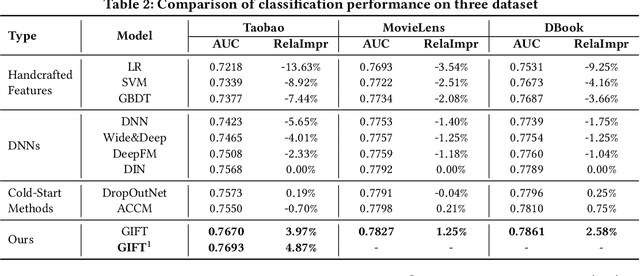
Short video has witnessed rapid growth in China and shows a promising market for promoting the sales of products in e-commerce platforms like Taobao. To ensure the freshness of the content, the platform needs to release a large number of new videos every day, which makes the conventional click-through rate (CTR) prediction model suffer from the severe item cold-start problem. In this paper, we propose GIFT, an efficient Graph-guIded Feature Transfer system, to fully take advantages of the rich information of warmed-up videos that related to the cold-start video. More specifically, we conduct feature transfer from warmed-up videos to those cold-start ones by involving the physical and semantic linkages into a heterogeneous graph. The former linkages consist of those explicit relationships (e.g., sharing the same category, under the same authorship etc.), while the latter measure the proximity of multimodal representations of two videos. In practice, the style, content, and even the recommendation pattern are pretty similar among those physically or semantically related videos. Besides, in order to provide the robust id representations and historical statistics obtained from warmed-up neighbors that cold-start videos covet most, we elaborately design the transfer function to make aware of different transferred features from different types of nodes and edges along the metapath on the graph. Extensive experiments on a large real-world dataset show that our GIFT system outperforms SOTA methods significantly and brings a 6.82% lift on click-through rate (CTR) in the homepage of Taobao App.
DBC-Forest: Deep forest with binning confidence screening
Dec 25, 2021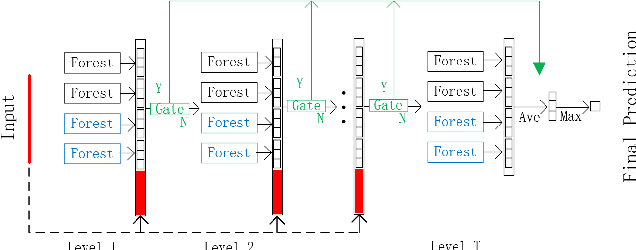
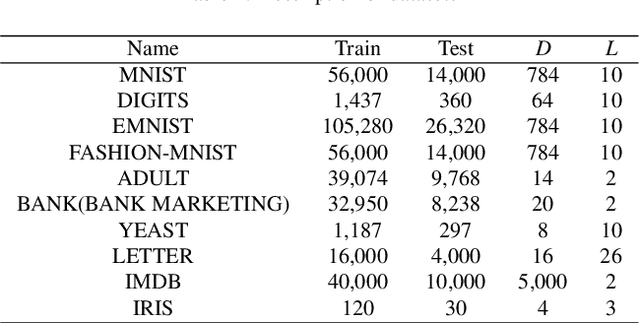
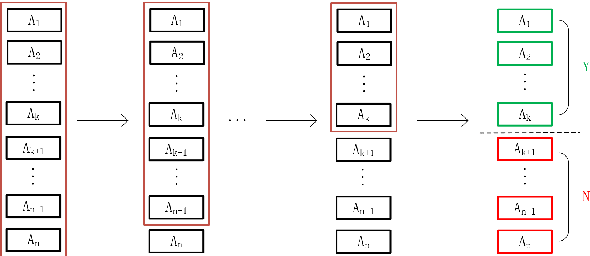
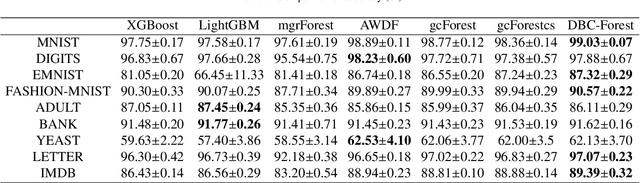
As a deep learning model, deep confidence screening forest (gcForestcs) has achieved great success in various applications. Compared with the traditional deep forest approach, gcForestcs effectively reduces the high time cost by passing some instances in the high-confidence region directly to the final stage. However, there is a group of instances with low accuracy in the high-confidence region, which are called mis-partitioned instances. To find these mis-partitioned instances, this paper proposes a deep binning confidence screening forest (DBC-Forest) model, which packs all instances into bins based on their confidences. In this way, more accurate instances can be passed to the final stage, and the performance is improved. Experimental results show that DBC-Forest achieves highly accurate predictions for the same hyperparameters and is faster than other similar models to achieve the same accuracy.
GraphPAS: Parallel Architecture Search for Graph Neural Networks
Dec 07, 2021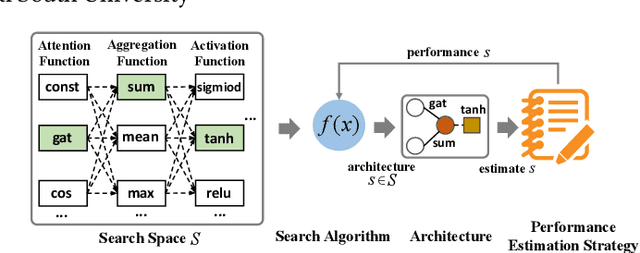

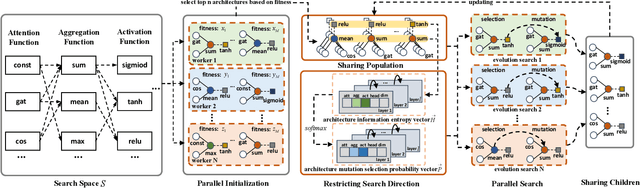
Graph neural architecture search has received a lot of attention as Graph Neural Networks (GNNs) has been successfully applied on the non-Euclidean data recently. However, exploring all possible GNNs architectures in the huge search space is too time-consuming or impossible for big graph data. In this paper, we propose a parallel graph architecture search (GraphPAS) framework for graph neural networks. In GraphPAS, we explore the search space in parallel by designing a sharing-based evolution learning, which can improve the search efficiency without losing the accuracy. Additionally, architecture information entropy is adopted dynamically for mutation selection probability, which can reduce space exploration. The experimental result shows that GraphPAS outperforms state-of-art models with efficiency and accuracy simultaneously.
Towards Graph Self-Supervised Learning with Contrastive Adjusted Zooming
Nov 20, 2021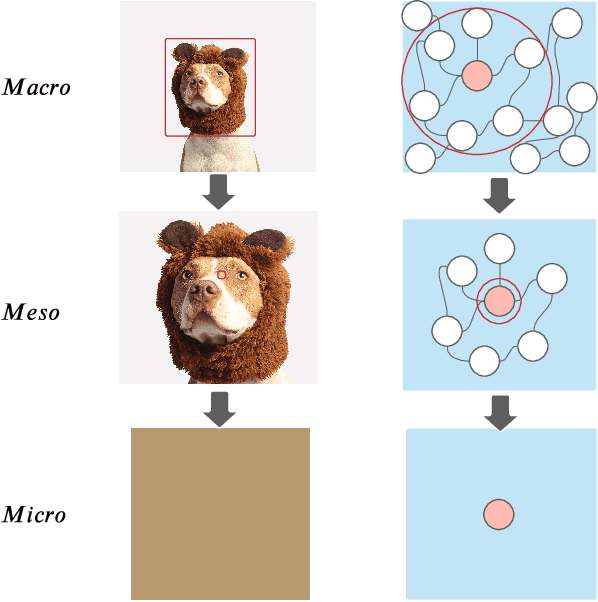
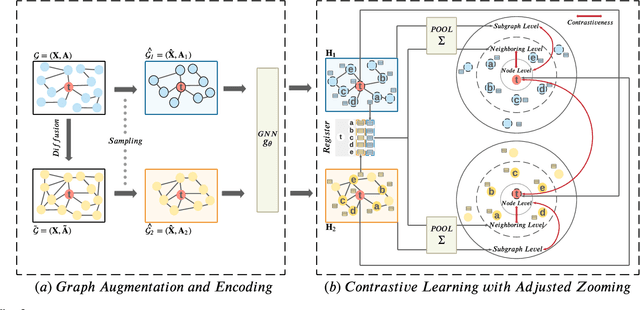
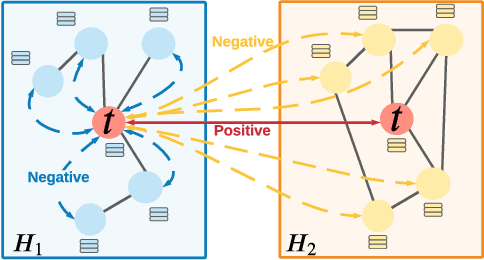
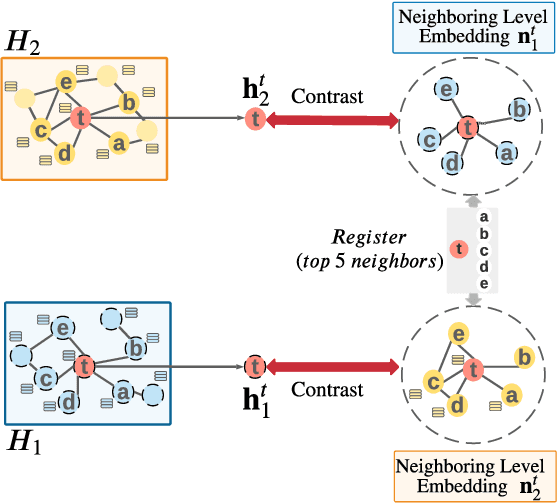
Graph representation learning (GRL) is critical for graph-structured data analysis. However, most of the existing graph neural networks (GNNs) heavily rely on labeling information, which is normally expensive to obtain in the real world. Existing unsupervised GRL methods suffer from certain limitations, such as the heavy reliance on monotone contrastiveness and limited scalability. To overcome the aforementioned problems, in light of the recent advancements in graph contrastive learning, we introduce a novel self-supervised graph representation learning algorithm via Graph Contrastive Adjusted Zooming, namely G-Zoom, to learn node representations by leveraging the proposed adjusted zooming scheme. Specifically, this mechanism enables G-Zoom to explore and extract self-supervision signals from a graph from multiple scales: micro (i.e., node-level), meso (i.e., neighbourhood-level), and macro (i.e., subgraph-level). Firstly, we generate two augmented views of the input graph via two different graph augmentations. Then, we establish three different contrastiveness on the above three scales progressively, from node, neighbouring, to subgraph level, where we maximize the agreement between graph representations across scales. While we can extract valuable clues from a given graph on the micro and macro perspectives, the neighbourhood-level contrastiveness offers G-Zoom the capability of a customizable option based on our adjusted zooming scheme to manually choose an optimal viewpoint that lies between the micro and macro perspectives to better understand the graph data. Additionally, to make our model scalable to large graphs, we employ a parallel graph diffusion approach to decouple model training from the graph size. We have conducted extensive experiments on real-world datasets, and the results demonstrate that our proposed model outperforms state-of-the-art methods consistently.
Adaptive Multi-receptive Field Spatial-Temporal Graph Convolutional Network for Traffic Forecasting
Nov 01, 2021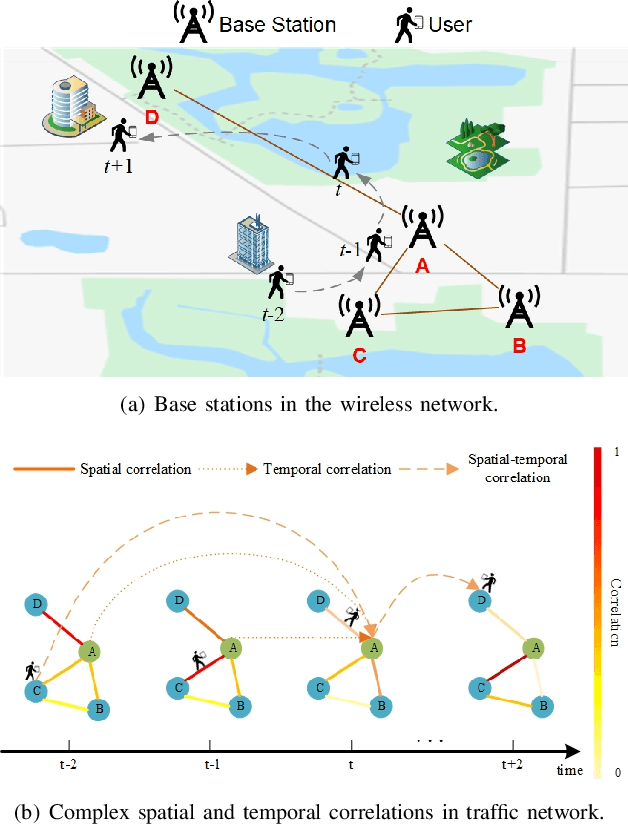
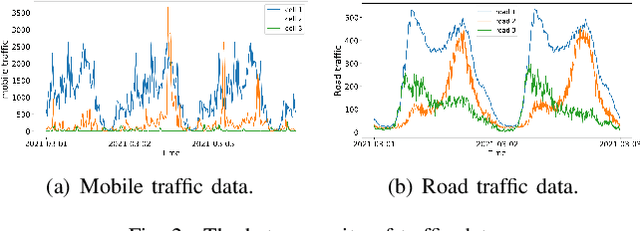
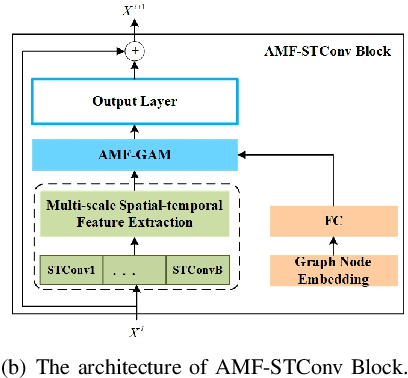
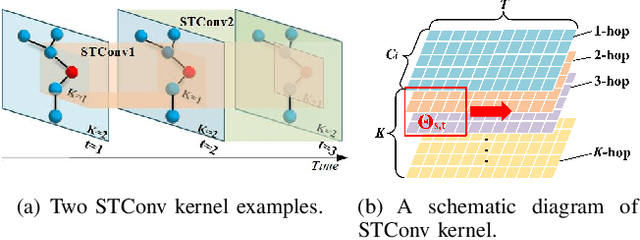
Mobile network traffic forecasting is one of the key functions in daily network operation. A commercial mobile network is large, heterogeneous, complex and dynamic. These intrinsic features make mobile network traffic forecasting far from being solved even with recent advanced algorithms such as graph convolutional network-based prediction approaches and various attention mechanisms, which have been proved successful in vehicle traffic forecasting. In this paper, we cast the problem as a spatial-temporal sequence prediction task. We propose a novel deep learning network architecture, Adaptive Multi-receptive Field Spatial-Temporal Graph Convolutional Networks (AMF-STGCN), to model the traffic dynamics of mobile base stations. AMF-STGCN extends GCN by (1) jointly modeling the complex spatial-temporal dependencies in mobile networks, (2) applying attention mechanisms to capture various Receptive Fields of heterogeneous base stations, and (3) introducing an extra decoder based on a fully connected deep network to conquer the error propagation challenge with multi-step forecasting. Experiments on four real-world datasets from two different domains consistently show AMF-STGCN outperforms the state-of-the-art methods.
Pre-trained Language Models in Biomedical Domain: A Systematic Survey
Oct 12, 2021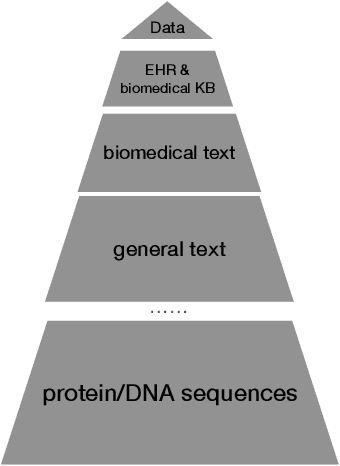

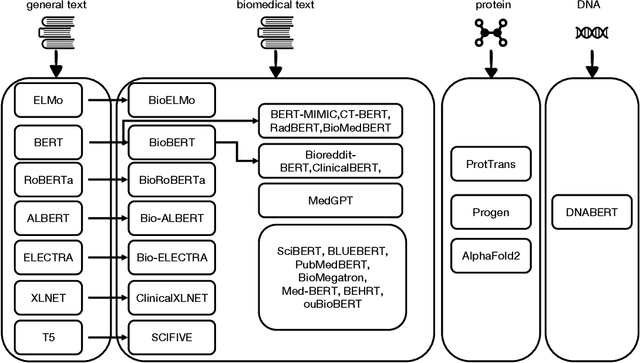

Pre-trained language models (PLMs) have been the de facto paradigm for most natural language processing (NLP) tasks. This also benefits biomedical domain: researchers from informatics, medicine, and computer science (CS) communities propose various PLMs trained on biomedical datasets, e.g., biomedical text, electronic health records, protein, and DNA sequences for various biomedical tasks. However, the cross-discipline characteristics of biomedical PLMs hinder their spreading among communities; some existing works are isolated from each other without comprehensive comparison and discussions. It expects a survey that not only systematically reviews recent advances of biomedical PLMs and their applications but also standardizes terminology and benchmarks. In this paper, we summarize the recent progress of pre-trained language models in the biomedical domain and their applications in biomedical downstream tasks. Particularly, we discuss the motivations and propose a taxonomy of existing biomedical PLMs. Their applications in biomedical downstream tasks are exhaustively discussed. At last, we illustrate various limitations and future trends, which we hope can provide inspiration for the future research of the research community.
Thompson Sampling for Unimodal Bandits
Jun 16, 2021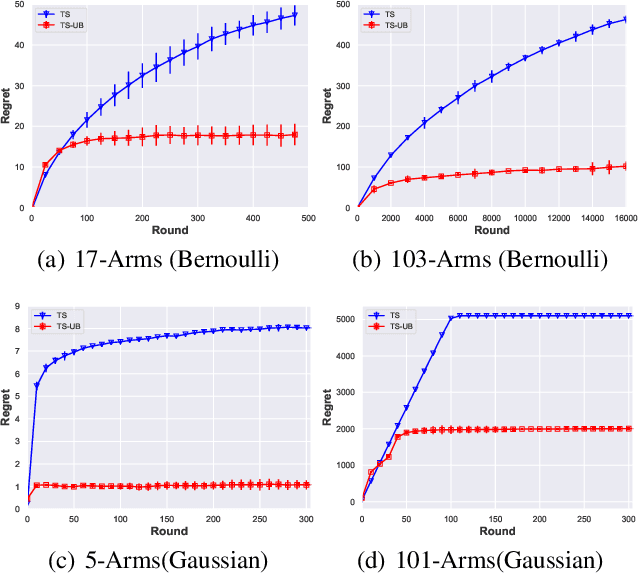
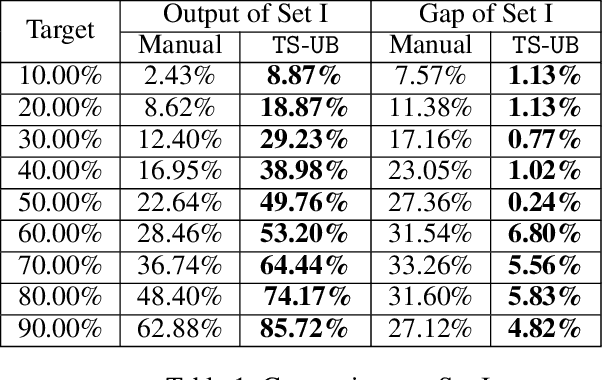
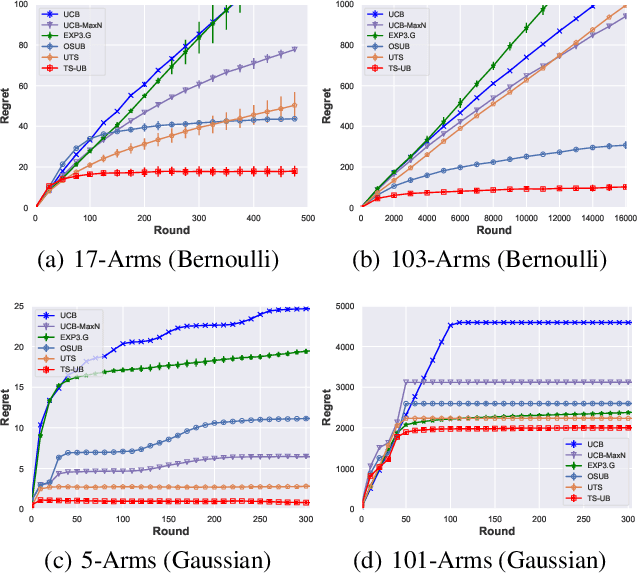
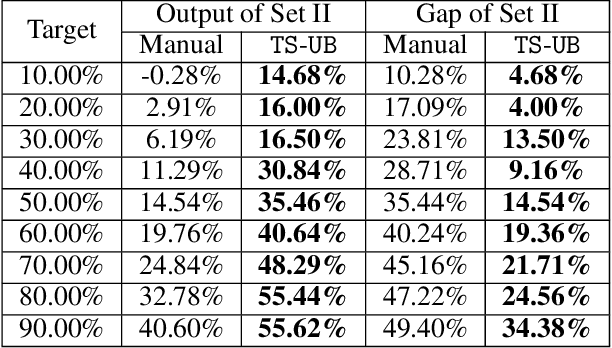
In this paper, we propose a Thompson Sampling algorithm for \emph{unimodal} bandits, where the expected reward is unimodal over the partially ordered arms. To exploit the unimodal structure better, at each step, instead of exploration from the entire decision space, our algorithm makes decision according to posterior distribution only in the neighborhood of the arm that has the highest empirical mean estimate. We theoretically prove that, for Bernoulli rewards, the regret of our algorithm reaches the lower bound of unimodal bandits, thus it is asymptotically optimal. For Gaussian rewards, the regret of our algorithm is $\mathcal{O}(\log T)$, which is far better than standard Thompson Sampling algorithms. Extensive experiments demonstrate the effectiveness of the proposed algorithm on both synthetic data sets and the real-world applications.
Physical Artificial Intelligence: The Concept Expansion of Next-Generation Artificial Intelligence
May 17, 2021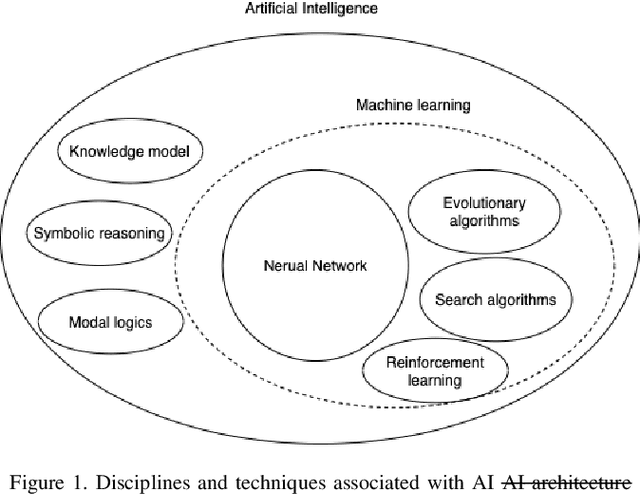

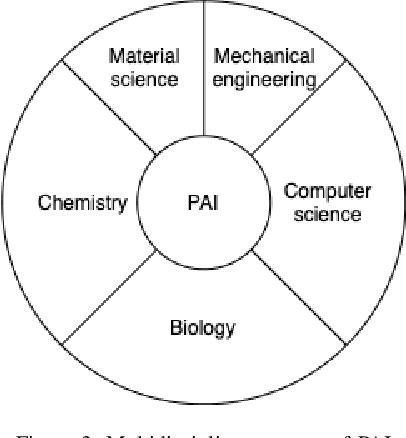
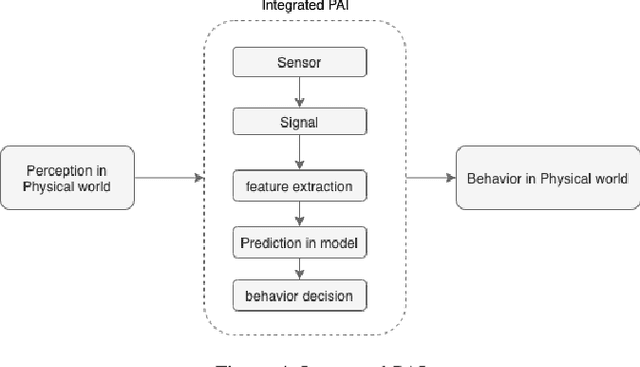
Artificial Intelligence has been a growth catalyst to our society and is cosidered across all idustries as a fundamental technology. However, its development has been limited to the signal processing domain that relies on the generated and collected data from other sensors. In recent research, concepts of Digital Artificial Intelligence and Physicial Artifical Intelligence have emerged and this can be considered a big step in the theoretical development of Artifical Intelligence. In this paper we explore the concept of Physicial Artifical Intelligence and propose two subdomains: Integrated Physicial Artifical Intelligence and Distributed Physicial Artifical Intelligence. The paper will also examine the trend and governance of Physicial Artifical Intelligence.