 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit Where You Mean: Region-Aware Adapter Injection for Mask-Free Local Image Editing
Apr 26, 2026Large diffusion transformers (DiTs) follow global editing instructions well but consistently leak local edits into unrelated regions, because joint-attention architectures offer no explicit channel telling the network where to apply the edit. We introduce REDEdit, a co-trained, instruction- and region-aware adapter framework that retrofits a frozen DiT into a precise local editor without modifying its backbone weights. A lightweight Block Adapter at every transformer block injects a structured condition stream that factorizes what to edit (instruction semantics) from where to edit (spatial mask); a learned SpatialGate routes the adapter signal selectively into the edit region while keeping the rest of the image near-identical to the source; and a Region-Aware Loss focuses the training objective on the changing pixels. Because these components make the backbone's internal representation mask-aware end-to-end, a thin MaskPredictor head trained jointly with the editor can ground the edit region directly from the instruction and source image eliminating any user-mask requirement at deployment. We evaluate on two complementary benchmarks: MagicBrush (paired ground-truth targets) to measure pixel-level preservation and edit accuracy, and Emu-Edit Test (no ground-truth images, 9 diverse edit categories) to stress-test instruction following and generalization across edit types. On both, REDEdit achieves state-of-the-art results, simultaneously outperforming mask-free and oracle-mask baselines. A seven-variant ablation cleanly isolates the contribution of each component.
EditCaption: Human-Aligned Instruction Synthesis for Image Editing via Supervised Fine-Tuning and Direct Preference Optimization
Apr 09, 2026High-quality training triplets (source-target image pairs with precise editing instructions) are a critical bottleneck for scaling instruction-guided image editing models. Vision-language models (VLMs) are widely used for automated instruction synthesis, but we identify three systematic failure modes in image-pair settings: orientation inconsistency (e.g., left/right confusion), viewpoint ambiguity, and insufficient fine-grained attribute description. Human evaluation shows that over 47% of instructions from strong baseline VLMs contain critical errors unusable for downstream training. We propose EditCaption, a scalable two-stage post-training pipeline for VLM-based instruction synthesis. Stage 1 builds a 100K supervised fine-tuning (SFT) dataset by combining GLM automatic annotation, EditScore-based filtering, and human refinement for spatial, directional, and attribute-level accuracy. Stage 2 collects 10K human preference pairs targeting the three failure modes and applies direct preference optimization (DPO) for alignment beyond SFT alone. On Eval-400, ByteMorph-Bench, and HQ-Edit, fine-tuned Qwen3-VL models outperform open-source baselines; the 235B model reaches 4.712 on Eval-400 (vs. Gemini-3-Pro 4.706, GPT-4.1 4.220, Kimi-K2.5 4.111) and 4.588 on ByteMorph-Bench (vs. Gemini-3-Pro 4.522, GPT-4.1 3.412). Human evaluation shows critical errors falling from 47.75% to 23% and correctness rising from 41.75% to 66%. The work offers a practical path to scalable, human-aligned instruction synthesis for image editing data.
PROMO: Promptable Outfitting for Efficient High-Fidelity Virtual Try-On
Mar 12, 2026Virtual Try-on (VTON) has become a core capability for online retail, where realistic try-on results provide reliable fit guidance, reduce returns, and benefit both consumers and merchants. Diffusion-based VTON methods achieve photorealistic synthesis, yet often rely on intricate architectures such as auxiliary reference networks and suffer from slow sampling, making the trade-off between fidelity and efficiency a persistent challenge. We approach VTON as a structured image editing problem that demands strong conditional generation under three key requirements: subject preservation, faithful texture transfer, and seamless harmonization. Under this perspective, our training framework is generic and transfers to broader image editing tasks. Moreover, the paired data produced by VTON constitutes a rich supervisory resource for training general-purpose editors. We present PROMO, a promptable virtual try-on framework built upon a Flow Matching DiT backbone with latent multi-modal conditional concatenation. By leveraging conditioning efficiency and self-reference mechanisms, our approach substantially reduces inference overhead. On standard benchmarks, PROMO surpasses both prior VTON methods and general image editing models in visual fidelity while delivering a competitive balance between quality and speed. These results demonstrate that flow-matching transformers, coupled with latent multi-modal conditioning and self-reference acceleration, offer an effective and training-efficient solution for high-quality virtual try-on.
FireRed-OCR Technical Report
Mar 02, 2026We present FireRed-OCR, a systematic framework to specialize general VLMs into high-performance OCR models. Large Vision-Language Models (VLMs) have demonstrated impressive general capabilities but frequently suffer from ``structural hallucination'' when processing complex documents, limiting their utility in industrial OCR applications. In this paper, we introduce FireRed-OCR, a novel framework designed to transform general-purpose VLMs (based on Qwen3-VL) into pixel-precise structural document parsing experts. To address the scarcity of high-quality structured data, we construct a ``Geometry + Semantics'' Data Factory. Unlike traditional random sampling, our pipeline leverages geometric feature clustering and multi-dimensional tagging to synthesize and curate a highly balanced dataset, effectively handling long-tail layouts and rare document types. Furthermore, we propose a Three-Stage Progressive Training strategy that guides the model from pixel-level perception to logical structure generation. This curriculum includes: (1) Multi-task Pre-alignment to ground the model's understanding of document structure; (2) Specialized SFT for standardizing full-image Markdown output; and (3) Format-Constrained Group Relative Policy Optimization (GRPO), which utilizes reinforcement learning to enforce strict syntactic validity and structural integrity (e.g., table closure, formula syntax). Extensive evaluations on OmniDocBench v1.5 demonstrate that FireRed-OCR achieves state-of-the-art performance with an overall score of 92.94\%, significantly outperforming strong baselines such as DeepSeek-OCR 2 and OCRVerse across text, formula, table, and reading order metrics. We open-source our code and model weights to facilitate the ``General VLM to Specialized Structural Expert'' paradigm.
IdGlow: Dynamic Identity Modulation for Multi-Subject Generation
Feb 28, 2026Multi-subject image generation requires seamlessly harmonizing multiple reference identities within a coherent scene. However, existing methods relying on rigid spatial masks or localized attention often struggle with the "stability-plasticity dilemma," particularly failing in tasks that require complex structural deformations, such as identity-preserving age transformation. To address this, we present IdGlow, a mask-free, progressive two-stage framework built upon Flow Matching diffusion models. In the supervised fine-tuning (SFT) stage, we introduce task-adaptive timestep scheduling aligned with diffusion generative dynamics: a linear decay schedule that progressively relaxes constraints for natural group composition, and a temporal gating mechanism that concentrates identity injection within a critical semantic window, successfully preserving adult facial semantics without overriding child-like anatomical structures. To resolve attribute leakage and semantic ambiguity without explicit layout inputs, we further integrate a badcase-driven Vision-Language Model (VLM) for precise, context-aware prompt synthesis. In the second stage, we design a Fine-Grained Group-Level Direct Preference Optimization (DPO) with a weighted margin formulation to simultaneously eliminate multi-subject artifacts, elevate texture harmony, and recalibrate identity fidelity towards real-world distributions. Extensive experiments on two challenging benchmarks -- direct multi-person fusion and age-transformed group generation -- demonstrate that IdGlow fundamentally mitigates the stability-plasticity conflict, achieving a superior Pareto balance between state-of-the-art facial fidelity and commercial-grade aesthetic quality.
FireRed-Image-Edit-1.0 Techinical Report
Feb 12, 2026We present FireRed-Image-Edit, a diffusion transformer for instruction-based image editing that achieves state-of-the-art performance through systematic optimization of data curation, training methodology, and evaluation design. We construct a 1.6B-sample training corpus, comprising 900M text-to-image and 700M image editing pairs from diverse sources. After rigorous cleaning, stratification, auto-labeling, and two-stage filtering, we retain over 100M high-quality samples balanced between generation and editing, ensuring strong semantic coverage and instruction alignment. Our multi-stage training pipeline progressively builds editing capability via pre-training, supervised fine-tuning, and reinforcement learning. To improve data efficiency, we introduce a Multi-Condition Aware Bucket Sampler for variable-resolution batching and Stochastic Instruction Alignment with dynamic prompt re-indexing. To stabilize optimization and enhance controllability, we propose Asymmetric Gradient Optimization for DPO, DiffusionNFT with layout-aware OCR rewards for text editing, and a differentiable Consistency Loss for identity preservation. We further establish REDEdit-Bench, a comprehensive benchmark spanning 15 editing categories, including newly introduced beautification and low-level enhancement tasks. Extensive experiments on REDEdit-Bench and public benchmarks (ImgEdit and GEdit) demonstrate competitive or superior performance against both open-source and proprietary systems. We release code, models, and the benchmark suite to support future research.
IVC-Prune: Revealing the Implicit Visual Coordinates in LVLMs for Vision Token Pruning
Feb 03, 2026Large Vision-Language Models (LVLMs) achieve impressive performance across multiple tasks. A significant challenge, however, is their prohibitive inference cost when processing high-resolution visual inputs. While visual token pruning has emerged as a promising solution, existing methods that primarily focus on semantic relevance often discard tokens that are crucial for spatial reasoning. We address this gap through a novel insight into \emph{how LVLMs process spatial reasoning}. Specifically, we reveal that LVLMs implicitly establish visual coordinate systems through Rotary Position Embeddings (RoPE), where specific token positions serve as \textbf{implicit visual coordinates} (IVC tokens) that are essential for spatial reasoning. Based on this insight, we propose \textbf{IVC-Prune}, a training-free, prompt-aware pruning strategy that retains both IVC tokens and semantically relevant foreground tokens. IVC tokens are identified by theoretically analyzing the mathematical properties of RoPE, targeting positions at which its rotation matrices approximate identity matrix or the $90^\circ$ rotation matrix. Foreground tokens are identified through a robust two-stage process: semantic seed discovery followed by contextual refinement via value-vector similarity. Extensive evaluations across four representative LVLMs and twenty diverse benchmarks show that IVC-Prune reduces visual tokens by approximately 50\% while maintaining $\geq$ 99\% of the original performance and even achieving improvements on several benchmarks. Source codes are available at https://github.com/FireRedTeam/IVC-Prune.
Toward Super Agent System with Hybrid AI Routers
Apr 11, 2025AI Agents powered by Large Language Models are transforming the world through enormous applications. A super agent has the potential to fulfill diverse user needs, such as summarization, coding, and research, by accurately understanding user intent and leveraging the appropriate tools to solve tasks. However, to make such an agent viable for real-world deployment and accessible at scale, significant optimizations are required to ensure high efficiency and low cost. This paper presents a design of the Super Agent System. Upon receiving a user prompt, the system first detects the intent of the user, then routes the request to specialized task agents with the necessary tools or automatically generates agentic workflows. In practice, most applications directly serve as AI assistants on edge devices such as phones and robots. As different language models vary in capability and cloud-based models often entail high computational costs, latency, and privacy concerns, we then explore the hybrid mode where the router dynamically selects between local and cloud models based on task complexity. Finally, we introduce the blueprint of an on-device super agent enhanced with cloud. With advances in multi-modality models and edge hardware, we envision that most computations can be handled locally, with cloud collaboration only as needed. Such architecture paves the way for super agents to be seamlessly integrated into everyday life in the near future.
BeadSight: An Inexpensive Tactile Sensor Using Hydro-Gel Beads
May 21, 2024



In robotic manipulation, tactile sensors are indispensable, especially when dealing with soft objects, objects of varying dimensions, or those out of the robot's direct line of sight. Traditional tactile sensors often grapple with challenges related to cost and durability. To address these issues, our study introduces a novel approach to visuo-tactile sensing with an emphasis on economy and replacablity. Our proposed sensor, BeadSight, uses hydro-gel beads encased in a vinyl bag as an economical, easily replaceable sensing medium. When the sensor makes contact with a surface, the deformation of the hydrogel beads is observed using a rear camera. This observation is then passed through a U-net Neural Network to predict the forces acting on the surface of the bead bag, in the form of a pressure map. Our results show that the sensor can accurately predict these pressure maps, detecting the location and magnitude of forces applied to the surface. These abilities make BeadSight an effective, inexpensive, and easily replaceable tactile sensor, ideal for many robotics applications.
GraphPAS: Parallel Architecture Search for Graph Neural Networks
Dec 07, 2021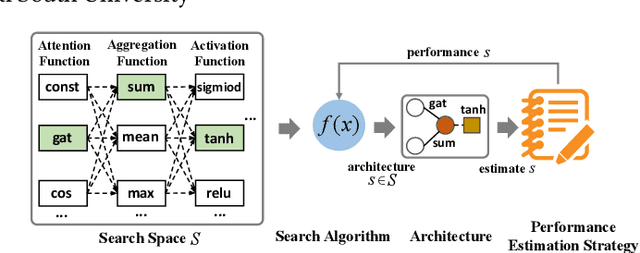

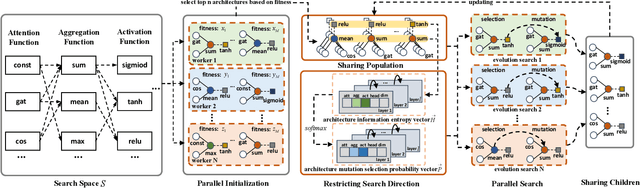
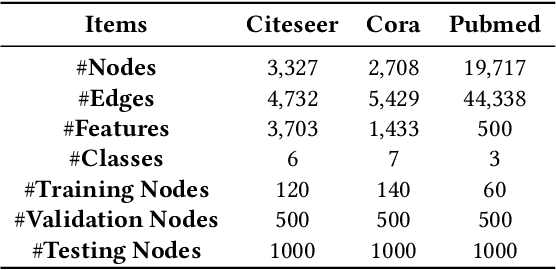
Graph neural architecture search has received a lot of attention as Graph Neural Networks (GNNs) has been successfully applied on the non-Euclidean data recently. However, exploring all possible GNNs architectures in the huge search space is too time-consuming or impossible for big graph data. In this paper, we propose a parallel graph architecture search (GraphPAS) framework for graph neural networks. In GraphPAS, we explore the search space in parallel by designing a sharing-based evolution learning, which can improve the search efficiency without losing the accuracy. Additionally, architecture information entropy is adopted dynamically for mutation selection probability, which can reduce space exploration. The experimental result shows that GraphPAS outperforms state-of-art models with efficiency and accuracy simultaneously.