 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
Covariance-Aware Demapping on Fourier-Curve Constellations
Apr 27, 2026Injecting artificial noise (AN) along the tangent space of a curved constellation makes each transmitted symbol induce a Gaussian observation with a symbol-dependent rank-one covariance, so the matched maximum-likelihood (ML) decoder differs from the Euclidean nearest-neighbor decoder by a single rank-one correction per candidate. We develop a baseband-demapper realization of this correction for the Fourier-curve constellation and instantiate a regular $(3,6)$ low-density parity-check (LDPC)-coded link at $(k,M){=}(20,64)$. Against four baselines (Euclidean-mismatched, flat-constellation isotropic-AN, no-AN, and same-spectral-efficiency narrowband), the matched decoder extends the BLER${=}10^{-1}$ operating range by approximately $5$\,dB over the Euclidean-mismatched counterpart on the same tangent-AN transmitter, at a cost of $2kM$ additional multiply-accumulate operations per symbol ($+50\%/+100\%$ under residual/template-correlation accounting) and a $20$\,KB constellation--tangent lookup table ($10$\,KB incremental over a Euclidean template-only LUT). A bit-interleaved coded-modulation achievable-rate (BICM-AIR) computation supports the same matched-metric advantage at the tested labeling and max-log demapper, indicating that the BLER gain is not merely an artifact of this particular LDPC simulation, and a Woodbury extension generalizes the rank-one correction to per-tone Ricean fading. In the tested Monte-Carlo runs, a design-aware bounded-search eavesdropper without the phase-key shows no successful LDPC decoding at any tested $k\in\{2,8,20\}$ within a $B{=}10^{3}$ non-code-aided search budget; code-aided, multi-frame, and known-preamble attacks are left to follow-up work. LUT quantization down to $6$ bits yields no measurable coded-BLER degradation at the tested operating points.
Matched and Euclidean-Mismatched Decoding on Fourier-Curve Constellations with Tangent Noise
Apr 16, 2026We study matched and Euclidean-mismatched decoding on finite Fourier-curve constellations with tangent-space artificial noise. Each hypothesis induces a Gaussian law with symbol-dependent rank-one covariance. We derive exact Euclidean pairwise errors for arbitrary pairs and an exact Gaussian-expectation representation for matched decoding on bilaterally tangent-orthogonal pairs. For uniform even constellations, the Euclidean side yields explicit distance spectra and symbol-error bounds across all offset classes; the matched side is exact on antipodal pairs and benchmarked numerically at the full-codebook level via Monte Carlo. By isolating the detection-theoretic consequence of tangent-space artificial noise, these results clarify analytically how noise fraction and constellation density enter the mismatch behavior; secrecy-rate implications require additional channel and adversary modeling.
The Price of Ignorance: Information-Free Quotation for Data Retention in Machine Unlearning
Apr 13, 2026When users exercise data deletion rights under the General Data Protection Regulation (GDPR) and similar regulations, mobile network operators face a tradeoff: excessive machine unlearning degrades model accuracy and incurs retraining costs, yet existing pricing mechanisms for data retention require the server to know every user's private privacy and accuracy preferences, which is infeasible under the very regulations that motivate unlearning. We ask: what is the welfare cost of operating without this private information? We design an information-free ascending quotation mechanism where the server broadcasts progressively higher prices and users self-select their data supply, requiring no knowledge of users' parameters. Under complete information, the protocol admits a unique subgame-perfect Nash equilibrium characterized by single-period selling. We formalize the Price of Ignorance -- the welfare gap between optimal personalized pricing (which knows everything) and our information-free quotation (which knows nothing) -- and prove a three-regime efficiency ordering. Numerical evaluation across seven mechanisms and 5000 Monte Carlo runs shows that this price is near zero: the information-free mechanism achieves >=99% of the welfare of its information-intensive benchmarks, while providing noise-robust guarantees and comparable fairness.
Quality-Aware Denoising of Ultra-Short TDoA Measurements for 5G-NR UAV Localization
Apr 09, 2026Reliable positioning is essential for Uncrewed Aerial Vehicles (UAVs) in safety-critical urban operations, yet achieving sub-meter accuracy under stringent latency constraints remains challenging. While 3rd Generation Partnership Project (3GPP) specifies repeated Positioning Reference Signals (PRS) transmissions for accurate Time Difference of Arrival (TDoA) measurements, denoising techniques specifically tailored for extremely limited measurement sequences within 3GPP frameworks remain underexplored. We propose Adaptive Gain Exponential Smoother (AGES), a lightweight filter combining exponentially weighted averaging with adaptive gains informed by 3GPP measurement quality reports. Simulations demonstrate AGES achieves 30-40% reduction in positioning error with only 3-5 repeated measurements while maintaining Fifth Generation New Radio (5G-NR) infrastructure compatibility.
Balancing Functionality and GDPR-Driven Privacy in ISAC Trajectory Sharing
Apr 09, 2026Integrated Sensing and Communications (ISAC) enables trajectory sharing that enhances beamforming, resource allocation, and cooperative perception, yet raises fundamental privacy concerns under the General Data Protection Regulation (GDPR) data minimisation principle. This paper proposes a Fisher Information Density (FID)-constrained trajectory sharing framework that enforces a local lower bound on estimation uncertainty, providing hard, quantifiable privacy guarantees by construction. Unlike fixed-noise approaches, the proposed method bounds the Privacy Leak Ratio (PLR) regardless of sensing power or adversarial post-processing, ensuring that no trajectory segment can be reconstructed beyond a prescribed accuracy threshold. Simulations on the OpenTraj dataset demonstrate that the framework keeps the average PLR below 20-25% and the maximum leakage segment duration under 2-2.5 s, while preserving data utility for downstream tasks such as movement prediction. The resulting criterion is interpretable, model-agnostic, and compatible with GDPR-compliant ISAC system design.
Generative Semantic HARQ: Latent-Space Text Retransmission and Combining
Mar 16, 2026Semantic communication conveys meaning rather than raw bits, but reliability at the semantic level remains an open challenge. We propose a semantic-level hybrid automatic repeat request (HARQ) framework for text communication, in which a Transformer-variational autoencoder (VAE) codec operates as a lightweight overlay on the conventional protocol stack. The stochastic encoder inherently generates diverse latent representations across retransmissions-providing incremental knowledge (IK) from a single model without dedicated protocol design. On the receiver side, a soft quality estimator triggers retransmissions and a quality-aware combiner merges the received latent vectors within a consistent latent space. We systematically benchmark six semantic quality metrics and four soft combining strategies under hybrid semantic distortion that mixes systematic bias with additive noise. The results suggest combining Weighted-Average or MRC-Inspired combining with self-consistency-based HARQ triggering for the best performance.
Can LLMs Truly Embody Human Personality? Analyzing AI and Human Behavior Alignment in Dispute Resolution
Feb 07, 2026Large language models (LLMs) are increasingly used to simulate human behavior in social settings such as legal mediation, negotiation, and dispute resolution. However, it remains unclear whether these simulations reproduce the personality-behavior patterns observed in humans. Human personality, for instance, shapes how individuals navigate social interactions, including strategic choices and behaviors in emotionally charged interactions. This raises the question: Can LLMs, when prompted with personality traits, reproduce personality-driven differences in human conflict behavior? To explore this, we introduce an evaluation framework that enables direct comparison of human-human and LLM-LLM behaviors in dispute resolution dialogues with respect to Big Five Inventory (BFI) personality traits. This framework provides a set of interpretable metrics related to strategic behavior and conflict outcomes. We additionally contribute a novel dataset creation methodology for LLM dispute resolution dialogues with matched scenarios and personality traits with respect to human conversations. Finally, we demonstrate the use of our evaluation framework with three contemporary closed-source LLMs and show significant divergences in how personality manifests in conflict across different LLMs compared to human data, challenging the assumption that personality-prompted agents can serve as reliable behavioral proxies in socially impactful applications. Our work highlights the need for psychological grounding and validation in AI simulations before real-world use.
Personality Expression Across Contexts: Linguistic and Behavioral Variation in LLM Agents
Feb 01, 2026Large Language Models (LLMs) can be conditioned with explicit personality prompts, yet their behavioral realization often varies depending on context. This study examines how identical personality prompts lead to distinct linguistic, behavioral, and emotional outcomes across four conversational settings: ice-breaking, negotiation, group decision, and empathy tasks. Results show that contextual cues systematically influence both personality expression and emotional tone, suggesting that the same traits are expressed differently depending on social and affective demands. This raises an important question for LLM-based dialogue agents: whether such variations reflect inconsistency or context-sensitive adaptation akin to human behavior. Viewed through the lens of Whole Trait Theory, these findings highlight that LLMs exhibit context-sensitive rather than fixed personality expression, adapting flexibly to social interaction goals and affective conditions.
Knowledge vs. Experience: Asymptotic Limits of Impatience in Edge Tenants
Nov 14, 2025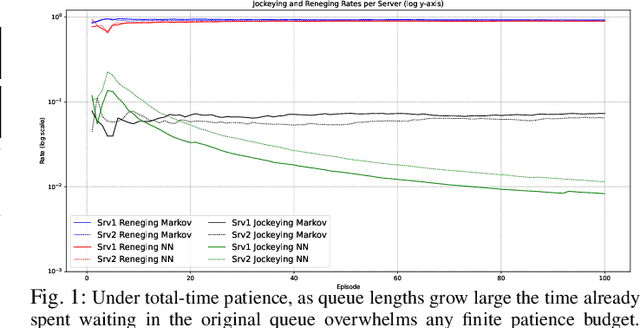
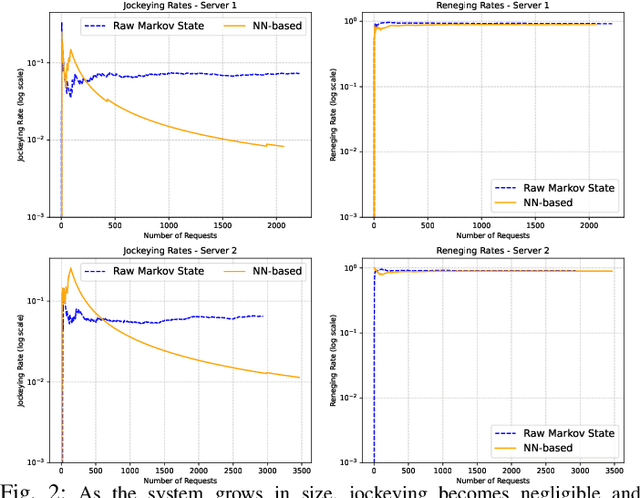
We study how two information feeds, a closed-form Markov estimator of residual sojourn and an online trained actor-critic, affect reneging and jockeying in a dual M/M/1 system. Analytically, for unequal service rates and total-time patience, we show that total wait grows linearly so abandonment is inevitable and the probability of a successful jockey vanishes as the backlog approaches towards infinity. Furthermore, under a mild sub-linear error condition both information models yield the same asymptotic limits (robustness). We empirically validate these limits and quantify finite backlog differences. Our findings show that learned and analytic feeds produce different delays, reneging rates and transient jockeying behavior at practical sizes, but converge to the same asymptotic outcome implied by our theory. The results characterize when value-of-information matters (finite regimes) and when it does not (asymptotics), informing lightweight telemetry and decision-logic design for low-cost, jockeying-aware systems.