 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Visual State Tracking in Multimodal Video Understanding
Jun 02, 2026Understanding a video requires more than recognizing isolated moments, as humans continuously track entities, states, and events over time. This capacity for visual state tracking is fundamental to video understanding, yet remains underexplored in current evaluations of Multimodal Large Language Models (MLLMs). We introduce Visual STAte Tracking benchmark (VSTAT), a video-based benchmark designed to diagnose visual state tracking in MLLMs. VSTAT consists of 834 clips drawn from both synthetic and real-world videos, paired with 1,500 questions that cannot be answered from any single frame or short segment, requiring continuous perception and integration of events across the entire video stream. Despite their strong performance on existing video benchmarks, we find that state-of-the-art MLLMs perform far below humans and only modestly above answer-prior baselines. To analyze this gap, we compare MLLMs' thinking traces with the underlying video stream to understand why and when MLLMs fail on VSTAT. We find that MLLMs reason and track correctly in text, but fail at visually perceiving the events they need to track. Finally, our preliminary evaluation suggests that recent agentic approaches, including MLLM-based video agents and coding agents, do not readily resolve these failures, still falling short on VSTAT.
Solaris: Building a Multiplayer Video World Model in Minecraft
Feb 26, 2026Existing action-conditioned video generation models (video world models) are limited to single-agent perspectives, failing to capture the multi-agent interactions of real-world environments. We introduce Solaris, a multiplayer video world model that simulates consistent multi-view observations. To enable this, we develop a multiplayer data system designed for robust, continuous, and automated data collection on video games such as Minecraft. Unlike prior platforms built for single-player settings, our system supports coordinated multi-agent interaction and synchronized videos + actions capture. Using this system, we collect 12.64 million multiplayer frames and propose an evaluation framework for multiplayer movement, memory, grounding, building, and view consistency. We train Solaris using a staged pipeline that progressively transitions from single-player to multiplayer modeling, combining bidirectional, causal, and Self Forcing training. In the final stage, we introduce Checkpointed Self Forcing, a memory-efficient Self Forcing variant that enables a longer-horizon teacher. Results show our architecture and training design outperform existing baselines. Through open-sourcing our system and models, we hope to lay the groundwork for a new generation of multi-agent world models.
Eval3D: Interpretable and Fine-grained Evaluation for 3D Generation
Apr 25, 2025Despite the unprecedented progress in the field of 3D generation, current systems still often fail to produce high-quality 3D assets that are visually appealing and geometrically and semantically consistent across multiple viewpoints. To effectively assess the quality of the generated 3D data, there is a need for a reliable 3D evaluation tool. Unfortunately, existing 3D evaluation metrics often overlook the geometric quality of generated assets or merely rely on black-box multimodal large language models for coarse assessment. In this paper, we introduce Eval3D, a fine-grained, interpretable evaluation tool that can faithfully evaluate the quality of generated 3D assets based on various distinct yet complementary criteria. Our key observation is that many desired properties of 3D generation, such as semantic and geometric consistency, can be effectively captured by measuring the consistency among various foundation models and tools. We thus leverage a diverse set of models and tools as probes to evaluate the inconsistency of generated 3D assets across different aspects. Compared to prior work, Eval3D provides pixel-wise measurement, enables accurate 3D spatial feedback, and aligns more closely with human judgments. We comprehensively evaluate existing 3D generation models using Eval3D and highlight the limitations and challenges of current models.
PISA Experiments: Exploring Physics Post-Training for Video Diffusion Models by Watching Stuff Drop
Mar 12, 2025



Large-scale pre-trained video generation models excel in content creation but are not reliable as physically accurate world simulators out of the box. This work studies the process of post-training these models for accurate world modeling through the lens of the simple, yet fundamental, physics task of modeling object freefall. We show state-of-the-art video generation models struggle with this basic task, despite their visually impressive outputs. To remedy this problem, we find that fine-tuning on a relatively small amount of simulated videos is effective in inducing the dropping behavior in the model, and we can further improve results through a novel reward modeling procedure we introduce. Our study also reveals key limitations of post-training in generalization and distribution modeling. Additionally, we release a benchmark for this task that may serve as a useful diagnostic tool for tracking physical accuracy in large-scale video generative model development.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
Task Me Anything
Jun 17, 2024



Benchmarks for large multimodal language models (MLMs) now serve to simultaneously assess the general capabilities of models instead of evaluating for a specific capability. As a result, when a developer wants to identify which models to use for their application, they are overwhelmed by the number of benchmarks and remain uncertain about which benchmark's results are most reflective of their specific use case. This paper introduces Task-Me-Anything, a benchmark generation engine which produces a benchmark tailored to a user's needs. Task-Me-Anything maintains an extendable taxonomy of visual assets and can programmatically generate a vast number of task instances. Additionally, it algorithmically addresses user queries regarding MLM performance efficiently within a computational budget. It contains 113K images, 10K videos, 2K 3D object assets, over 365 object categories, 655 attributes, and 335 relationships. It can generate 750M image/video question-answering pairs, which focus on evaluating MLM perceptual capabilities. Task-Me-Anything reveals critical insights: open-source MLMs excel in object and attribute recognition but lack spatial and temporal understanding; each model exhibits unique strengths and weaknesses; larger models generally perform better, though exceptions exist; and GPT4o demonstrates challenges in recognizing rotating/moving objects and distinguishing colors.
OBJECT 3DIT: Language-guided 3D-aware Image Editing
Jul 20, 2023



Existing image editing tools, while powerful, typically disregard the underlying 3D geometry from which the image is projected. As a result, edits made using these tools may become detached from the geometry and lighting conditions that are at the foundation of the image formation process. In this work, we formulate the newt ask of language-guided 3D-aware editing, where objects in an image should be edited according to a language instruction in context of the underlying 3D scene. To promote progress towards this goal, we release OBJECT: a dataset consisting of 400K editing examples created from procedurally generated 3D scenes. Each example consists of an input image, editing instruction in language, and the edited image. We also introduce 3DIT : single and multi-task models for four editing tasks. Our models show impressive abilities to understand the 3D composition of entire scenes, factoring in surrounding objects, surfaces, lighting conditions, shadows, and physically-plausible object configurations. Surprisingly, training on only synthetic scenes from OBJECT, editing capabilities of 3DIT generalize to real-world images.
Objaverse-XL: A Universe of 10M+ 3D Objects
Jul 11, 2023Natural language processing and 2D vision models have attained remarkable proficiency on many tasks primarily by escalating the scale of training data. However, 3D vision tasks have not seen the same progress, in part due to the challenges of acquiring high-quality 3D data. In this work, we present Objaverse-XL, a dataset of over 10 million 3D objects. Our dataset comprises deduplicated 3D objects from a diverse set of sources, including manually designed objects, photogrammetry scans of landmarks and everyday items, and professional scans of historic and antique artifacts. Representing the largest scale and diversity in the realm of 3D datasets, Objaverse-XL enables significant new possibilities for 3D vision. Our experiments demonstrate the improvements enabled with the scale provided by Objaverse-XL. We show that by training Zero123 on novel view synthesis, utilizing over 100 million multi-view rendered images, we achieve strong zero-shot generalization abilities. We hope that releasing Objaverse-XL will enable further innovations in the field of 3D vision at scale.
Objaverse: A Universe of Annotated 3D Objects
Dec 15, 2022Massive data corpora like WebText, Wikipedia, Conceptual Captions, WebImageText, and LAION have propelled recent dramatic progress in AI. Large neural models trained on such datasets produce impressive results and top many of today's benchmarks. A notable omission within this family of large-scale datasets is 3D data. Despite considerable interest and potential applications in 3D vision, datasets of high-fidelity 3D models continue to be mid-sized with limited diversity of object categories. Addressing this gap, we present Objaverse 1.0, a large dataset of objects with 800K+ (and growing) 3D models with descriptive captions, tags, and animations. Objaverse improves upon present day 3D repositories in terms of scale, number of categories, and in the visual diversity of instances within a category. We demonstrate the large potential of Objaverse via four diverse applications: training generative 3D models, improving tail category segmentation on the LVIS benchmark, training open-vocabulary object-navigation models for Embodied AI, and creating a new benchmark for robustness analysis of vision models. Objaverse can open new directions for research and enable new applications across the field of AI.
Text2Mesh: Text-Driven Neural Stylization for Meshes
Dec 06, 2021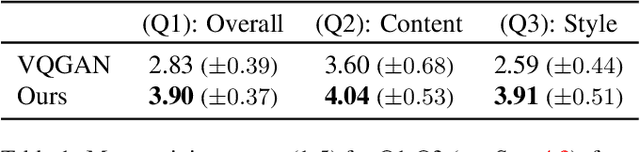


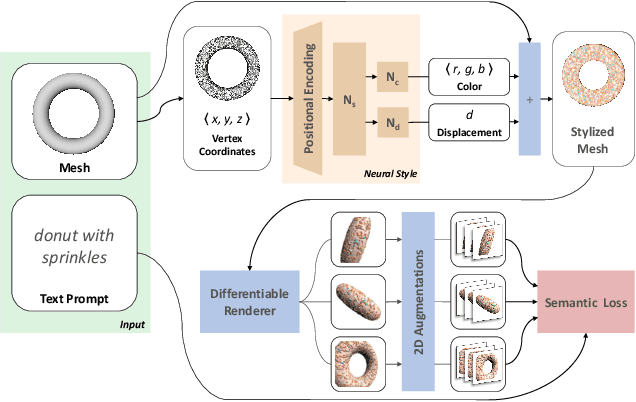
In this work, we develop intuitive controls for editing the style of 3D objects. Our framework, Text2Mesh, stylizes a 3D mesh by predicting color and local geometric details which conform to a target text prompt. We consider a disentangled representation of a 3D object using a fixed mesh input (content) coupled with a learned neural network, which we term neural style field network. In order to modify style, we obtain a similarity score between a text prompt (describing style) and a stylized mesh by harnessing the representational power of CLIP. Text2Mesh requires neither a pre-trained generative model nor a specialized 3D mesh dataset. It can handle low-quality meshes (non-manifold, boundaries, etc.) with arbitrary genus, and does not require UV parameterization. We demonstrate the ability of our technique to synthesize a myriad of styles over a wide variety of 3D meshes.