 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICA: Information-Aware Credit Assignment for Visually Grounded Long-Horizon Information-Seeking Agents
Feb 11, 2026Despite the strong performance achieved by reinforcement learning-trained information-seeking agents, learning in open-ended web environments remains severely constrained by low signal-to-noise feedback. Text-based parsers often discard layout semantics and introduce unstructured noise, while long-horizon training typically relies on sparse outcome rewards that obscure which retrieval actions actually matter. We propose a visual-native search framework that represents webpages as visual snapshots, allowing agents to leverage layout cues to quickly localize salient evidence and suppress distractors. To learn effectively from these high-dimensional observations, we introduce Information-Aware Credit Assignment (ICA), a post-hoc method that estimates each retrieved snapshot's contribution to the final outcome via posterior analysis and propagates dense learning signals back to key search turns. Integrated with a GRPO-based training pipeline, our approach consistently outperforms text-based baselines on diverse information-seeking benchmarks, providing evidence that visual snapshot grounding with information-level credit assignment alleviates the credit-assignment bottleneck in open-ended web environments. The code and datasets will be released in https://github.com/pc-inno/ICA_MM_deepsearch.git.
MMMG: a Comprehensive and Reliable Evaluation Suite for Multitask Multimodal Generation
May 23, 2025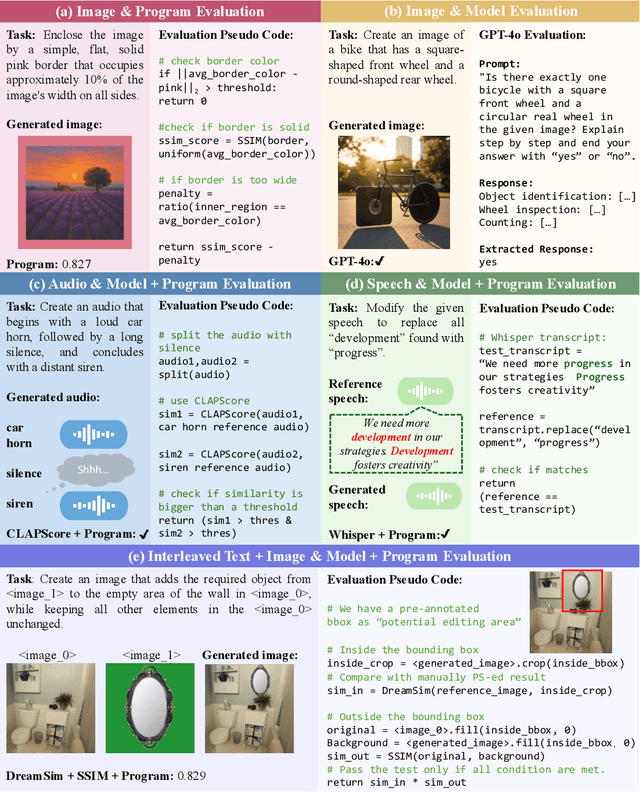
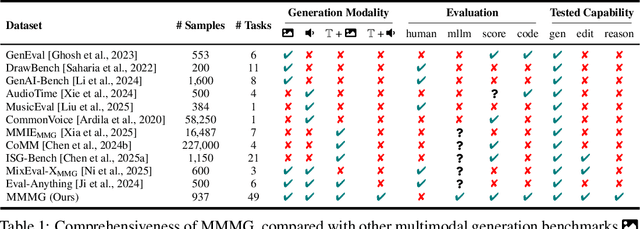
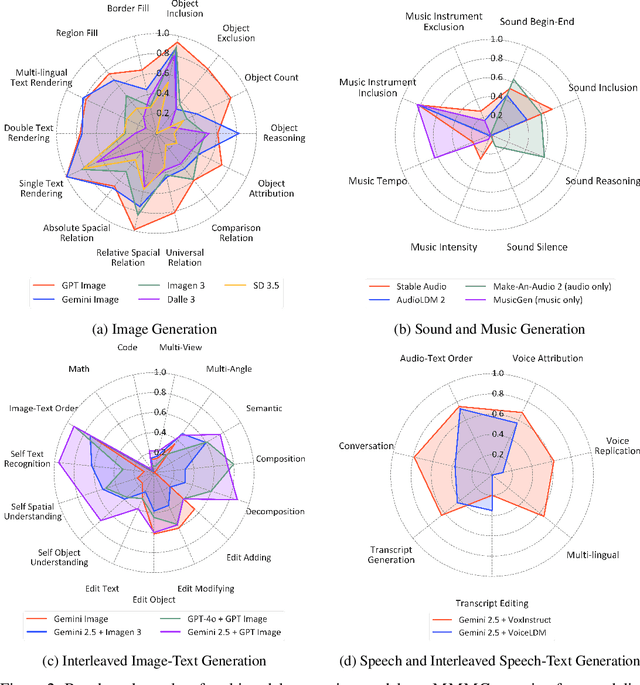
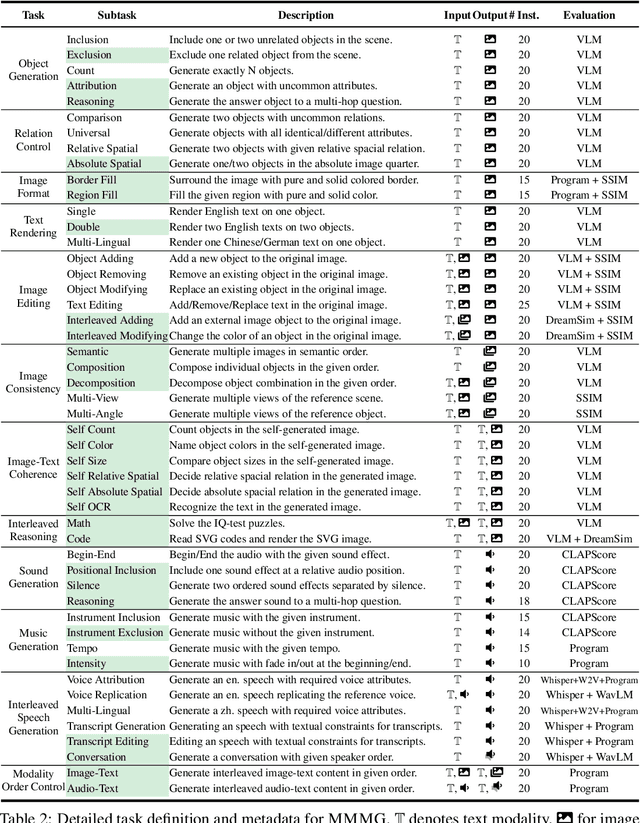
Automatically evaluating multimodal generation presents a significant challenge, as automated metrics often struggle to align reliably with human evaluation, especially for complex tasks that involve multiple modalities. To address this, we present MMMG, a comprehensive and human-aligned benchmark for multimodal generation across 4 modality combinations (image, audio, interleaved text and image, interleaved text and audio), with a focus on tasks that present significant challenges for generation models, while still enabling reliable automatic evaluation through a combination of models and programs. MMMG encompasses 49 tasks (including 29 newly developed ones), each with a carefully designed evaluation pipeline, and 937 instructions to systematically assess reasoning, controllability, and other key capabilities of multimodal generation models. Extensive validation demonstrates that MMMG is highly aligned with human evaluation, achieving an average agreement of 94.3%. Benchmarking results on 24 multimodal generation models reveal that even though the state-of-the-art model, GPT Image, achieves 78.3% accuracy for image generation, it falls short on multimodal reasoning and interleaved generation. Furthermore, results suggest considerable headroom for improvement in audio generation, highlighting an important direction for future research.