 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime's Up! An Empirical Study of LLM Reasoning Ability Under Output Length Constraint
Apr 22, 2025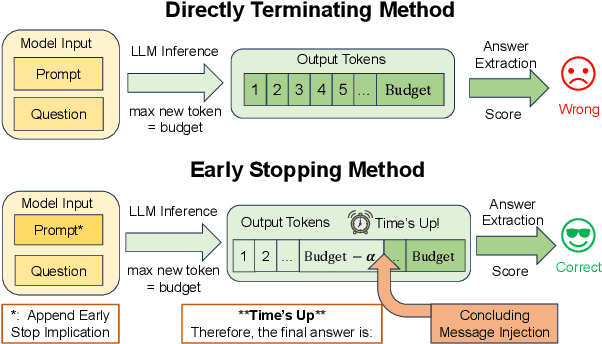
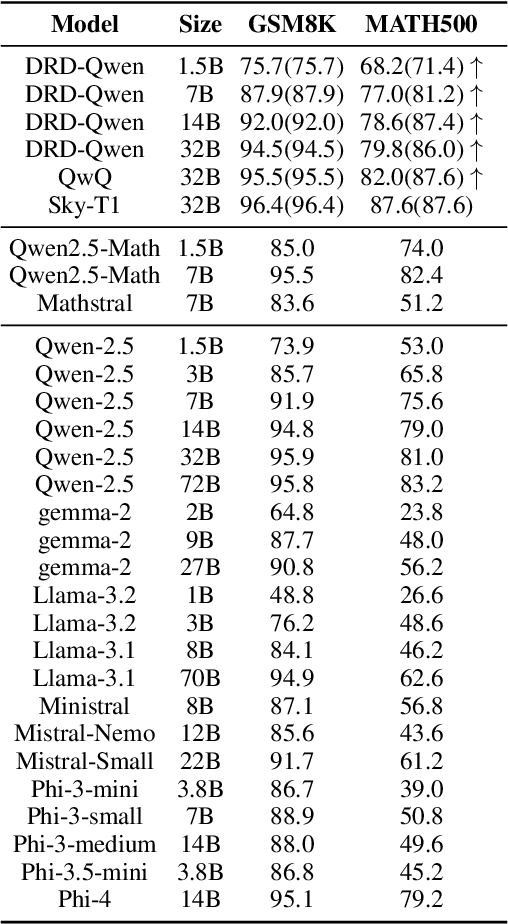
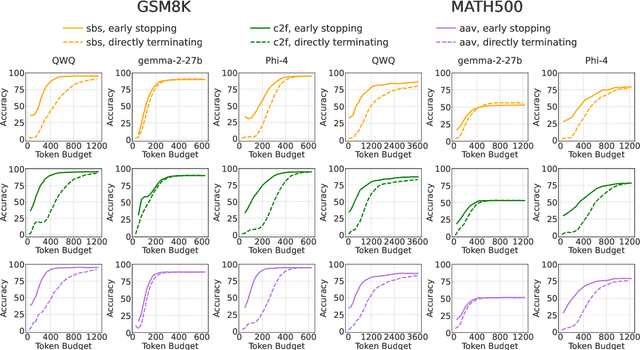
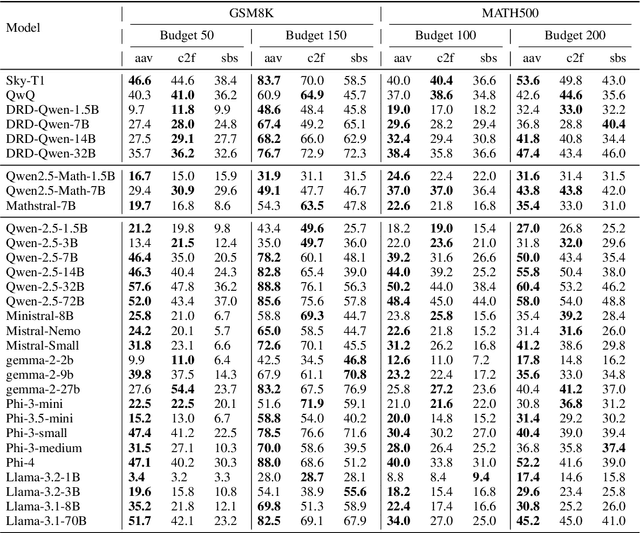
Recent work has demonstrated the remarkable potential of Large Language Models (LLMs) in test-time scaling. By making the models think before answering, they are able to achieve much higher accuracy with extra inference computation. However, in many real-world scenarios, models are used under time constraints, where an answer should be given to the user within a certain output length. It is unclear whether and how the reasoning abilities of LLMs remain effective under such constraints. We take a first look at this problem by conducting an in-depth empirical study. Specifically, we test more than 25 LLMs on common reasoning datasets under a wide range of output length budgets, and we analyze the correlation between the inference accuracy and various properties including model type, model size, prompt style, etc. We also consider the mappings between the token budgets and the actual on-device latency budgets. The results have demonstrated several interesting findings regarding the budget-aware LLM reasoning that differ from the unconstrained situation, e.g. the optimal choices of model sizes and prompts change under different budgets. These findings offer practical guidance for users to deploy LLMs under real-world latency constraints.
Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash
Apr 11, 2025Large language models (LLMs) are increasingly being deployed on mobile devices, but the limited DRAM capacity constrains the deployable model size. This paper introduces ActiveFlow, the first LLM inference framework that can achieve adaptive DRAM usage for modern LLMs (not ReLU-based), enabling the scaling up of deployable model sizes. The framework is based on the novel concept of active weight DRAM-flash swapping and incorporates three novel techniques: (1) Cross-layer active weights preloading. It uses the activations from the current layer to predict the active weights of several subsequent layers, enabling computation and data loading to overlap, as well as facilitating large I/O transfers. (2) Sparsity-aware self-distillation. It adjusts the active weights to align with the dense-model output distribution, compensating for approximations introduced by contextual sparsity. (3) Active weight DRAM-flash swapping pipeline. It orchestrates the DRAM space allocation among the hot weight cache, preloaded active weights, and computation-involved weights based on available memory. Results show ActiveFlow achieves the performance-cost Pareto frontier compared to existing efficiency optimization methods.
STRIDE: Automating Reward Design, Deep Reinforcement Learning Training and Feedback Optimization in Humanoid Robotics Locomotion
Feb 10, 2025



Humanoid robotics presents significant challenges in artificial intelligence, requiring precise coordination and control of high-degree-of-freedom systems. Designing effective reward functions for deep reinforcement learning (DRL) in this domain remains a critical bottleneck, demanding extensive manual effort, domain expertise, and iterative refinement. To overcome these challenges, we introduce STRIDE, a novel framework built on agentic engineering to automate reward design, DRL training, and feedback optimization for humanoid robot locomotion tasks. By combining the structured principles of agentic engineering with large language models (LLMs) for code-writing, zero-shot generation, and in-context optimization, STRIDE generates, evaluates, and iteratively refines reward functions without relying on task-specific prompts or templates. Across diverse environments featuring humanoid robot morphologies, STRIDE outperforms the state-of-the-art reward design framework EUREKA, achieving significant improvements in efficiency and task performance. Using STRIDE-generated rewards, simulated humanoid robots achieve sprint-level locomotion across complex terrains, highlighting its ability to advance DRL workflows and humanoid robotics research.
Data Center Cooling System Optimization Using Offline Reinforcement Learning
Jan 25, 2025



The recent advances in information technology and artificial intelligence have fueled a rapid expansion of the data center (DC) industry worldwide, accompanied by an immense appetite for electricity to power the DCs. In a typical DC, around 30~40% of the energy is spent on the cooling system rather than on computer servers, posing a pressing need for developing new energy-saving optimization technologies for DC cooling systems. However, optimizing such real-world industrial systems faces numerous challenges, including but not limited to a lack of reliable simulation environments, limited historical data, and stringent safety and control robustness requirements. In this work, we present a novel physics-informed offline reinforcement learning (RL) framework for energy efficiency optimization of DC cooling systems. The proposed framework models the complex dynamical patterns and physical dependencies inside a server room using a purposely designed graph neural network architecture that is compliant with the fundamental time-reversal symmetry. Because of its well-behaved and generalizable state-action representations, the model enables sample-efficient and robust latent space offline policy learning using limited real-world operational data. Our framework has been successfully deployed and verified in a large-scale production DC for closed-loop control of its air-cooling units (ACUs). We conducted a total of 2000 hours of short and long-term experiments in the production DC environment. The results show that our method achieves 14~21% energy savings in the DC cooling system, without any violation of the safety or operational constraints. Our results have demonstrated the significant potential of offline RL in solving a broad range of data-limited, safety-critical real-world industrial control problems.
Condor: Enhance LLM Alignment with Knowledge-Driven Data Synthesis and Refinement
Jan 21, 2025



The quality of Supervised Fine-Tuning (SFT) data plays a critical role in enhancing the conversational capabilities of Large Language Models (LLMs). However, as LLMs become more advanced, the availability of high-quality human-annotated SFT data has become a significant bottleneck, necessitating a greater reliance on synthetic training data. In this work, we introduce Condor, a novel two-stage synthetic data generation framework that incorporates World Knowledge Tree and Self-Reflection Refinement to produce high-quality SFT data at scale. Our experimental results demonstrate that a base model fine-tuned on only 20K Condor-generated samples achieves superior performance compared to counterparts. The additional refinement stage in Condor further enables iterative self-improvement for LLMs at various scales (up to 72B), validating the effectiveness of our approach. Furthermore, our investigation into the scaling for synthetic data in post-training reveals substantial unexplored potential for performance improvements, opening promising avenues for future research.
AutoDroid-V2: Boosting SLM-based GUI Agents via Code Generation
Dec 24, 2024



Large language models (LLMs) have brought exciting new advances to mobile UI agents, a long-standing research field that aims to complete arbitrary natural language tasks through mobile UI interactions. However, existing UI agents usually demand high reasoning capabilities of powerful large models that are difficult to be deployed locally on end-users' devices, which raises huge concerns about user privacy and centralized serving cost. One way to reduce the required model size is to customize a smaller domain-specific model with high-quality training data, e.g. large-scale human demonstrations of diverse types of apps and tasks, while such datasets are extremely difficult to obtain. Inspired by the remarkable coding abilities of recent small language models (SLMs), we propose to convert the UI task automation problem to a code generation problem, which can be effectively solved by an on-device SLM and efficiently executed with an on-device code interpreter. Unlike normal coding tasks that can be extensively pretrained with public datasets, generating UI automation code is challenging due to the diversity, complexity, and variability of target apps. Therefore, we adopt a document-centered approach that automatically builds fine-grained API documentation for each app and generates diverse task samples based on this documentation. By guiding the agent with the synthetic documents and task samples, it learns to generate precise and efficient scripts to complete unseen tasks. Based on detailed comparisons with state-of-the-art mobile UI agents, our approach effectively improves the mobile task automation with significantly higher success rates and lower latency/token consumption. Code will be open-sourced.
Threshold Neuron: A Brain-inspired Artificial Neuron for Efficient On-device Inference
Dec 18, 2024Enhancing the computational efficiency of on-device Deep Neural Networks (DNNs) remains a significant challengein mobile and edge computing. As we aim to execute increasingly complex tasks with constrained computational resources, much of the research has focused on compressing neural network structures and optimizing systems. Although many studies have focused on compressing neural network structures and parameters or optimizing underlying systems, there has been limited attention on optimizing the fundamental building blocks of neural networks: the neurons. In this study, we deliberate on a simple but important research question: Can we design artificial neurons that offer greater efficiency than the traditional neuron paradigm? Inspired by the threshold mechanisms and the excitation-inhibition balance observed in biological neurons, we propose a novel artificial neuron model, Threshold Neurons. Using Threshold Neurons, we can construct neural networks similar to those with traditional artificial neurons, while significantly reducing hardware implementation complexity. Our extensive experiments validate the effectiveness of neural networks utilizing Threshold Neurons, achieving substantial power savings of 7.51x to 8.19x and area savings of 3.89x to 4.33x at the kernel level, with minimal loss in precision. Furthermore, FPGA-based implementations of these networks demonstrate 2.52x power savings and 1.75x speed enhancements at the system level. The source code will be made available upon publication.
MobiFuse: A High-Precision On-device Depth Perception System with Multi-Data Fusion
Dec 18, 2024



We present MobiFuse, a high-precision depth perception system on mobile devices that combines dual RGB and Time-of-Flight (ToF) cameras. To achieve this, we leverage physical principles from various environmental factors to propose the Depth Error Indication (DEI) modality, characterizing the depth error of ToF and stereo-matching. Furthermore, we employ a progressive fusion strategy, merging geometric features from ToF and stereo depth maps with depth error features from the DEI modality to create precise depth maps. Additionally, we create a new ToF-Stereo depth dataset, RealToF, to train and validate our model. Our experiments demonstrate that MobiFuse excels over baselines by significantly reducing depth measurement errors by up to 77.7%. It also showcases strong generalization across diverse datasets and proves effectiveness in two downstream tasks: 3D reconstruction and 3D segmentation. The demo video of MobiFuse in real-life scenarios is available at the de-identified YouTube link(https://youtu.be/jy-Sp7T1LVs).
ChainStream: An LLM-based Framework for Unified Synthetic Sensing
Dec 13, 2024



Many applications demand context sensing to offer personalized and timely services. Yet, developing sensing programs can be challenging for developers and using them is privacy-concerning for end-users. In this paper, we propose to use natural language as the unified interface to process personal data and sense user context, which can effectively ease app development and make the data pipeline more transparent. Our work is inspired by large language models (LLMs) and other generative models, while directly applying them does not solve the problem - letting the model directly process the data cannot handle complex sensing requests and letting the model write the data processing program suffers error-prone code generation. We address the problem with 1) a unified data processing framework that makes context-sensing programs simpler and 2) a feedback-guided query optimizer that makes data query more informative. To evaluate the performance of natural language-based context sensing, we create a benchmark that contains 133 context sensing tasks. Extensive evaluation has shown that our approach is able to automatically solve the context-sensing tasks efficiently and precisely. The code is opensourced at https://github.com/MobileLLM/ChainStream.
V-LoRA: An Efficient and Flexible System Boosts Vision Applications with LoRA LMM
Nov 01, 2024



Large Multimodal Models (LMMs) have shown significant progress in various complex vision tasks with the solid linguistic and reasoning capacity inherited from large language models (LMMs). Low-rank adaptation (LoRA) offers a promising method to integrate external knowledge into LMMs, compensating for their limitations on domain-specific tasks. However, the existing LoRA model serving is excessively computationally expensive and causes extremely high latency. In this paper, we present an end-to-end solution that empowers diverse vision tasks and enriches vision applications with LoRA LMMs. Our system, VaLoRA, enables accurate and efficient vision tasks by 1) an accuracy-aware LoRA adapter generation approach that generates LoRA adapters rich in domain-specific knowledge to meet application-specific accuracy requirements, 2) an adaptive-tiling LoRA adapters batching operator that efficiently computes concurrent heterogeneous LoRA adapters, and 3) a flexible LoRA adapter orchestration mechanism that manages application requests and LoRA adapters to achieve the lowest average response latency. We prototype VaLoRA on five popular vision tasks on three LMMs. Experiment results reveal that VaLoRA improves 24-62% of the accuracy compared to the original LMMs and reduces 20-89% of the latency compared to the state-of-the-art LoRA model serving systems.