 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActProbe: Action-Space Probe for Early Failure Detection of Generative Robot Policies
Jun 07, 2026Generative robot policies fail unpredictably at deployment: they hesitate at critical moments, drift off-task, or commit to unrecoverable actions. Existing online failure detectors either require white-box access to policy internals or add runtime overhead through resampling and observation-side signals. Our empirical analysis shows that emitted action chunks themselves already carry strong predictive signal for impending failures in generative robot policies. Motivated by this observation, we introduce ActProbe, a lightweight, pure action-space detector that uses two compact signals available from a single forward pass: Temporal Consistency Error (TCE) between consecutive action chunks and Action Chunk Magnitude (ACM) of the current chunk. ActProbe maps these signals to per-step failure probabilities with a task-conditioned LSTM-MLP architecture. Across a diverse suite of generative robot policies and benchmarks, ActProbe raises alerts before failures become visually recognizable, improving the accuracy (F1)-timeliness Pareto frontier of failure detection by an average hypervolume gain of +12.7% over both internal- and external-feature baselines, with a +9.0% early-detection ROC-AUC lead on unseen tasks. ActProbe further transfers to deployment, predicting failures on unseen real-robot pick tasks and accelerating RL fine-tuning (PPO) with 2.9x fewer environment interactions.
GRIP-VLM: Group-Relative Importance Pruning for Efficient Vision-Language Models
May 13, 2026In Vision-Language Models (VLMs), processing a massive number of visual tokens incurs prohibitive computational overhead. While recent training-aware pruning methods attempt to selectively discard redundant tokens, they largely rely on continuous-gradient relaxations. However, visual token pruning is inherently a discrete, non-convex combinatorial problem; consequently, these continuous approximations frequently trap the optimization in sub-optimal local minima, especially under aggressive compression budgets. To overcome this fundamental bottleneck, we propose GRIP-VLM, a Group-Relative Importance Pruning framework driven by Reinforcement Learning. Rather than relying on smooth-gradient assumptions, GRIP-VLM formulates pruning as a Markov Decision Process, employing a Group Relative Policy Optimization (GRPO) paradigm anchored by supervised warm-up to directly explore the discrete selection space. Integrated with a budget-aware scorer, our lightweight agent dynamically evaluates per-token importance and adapts to arbitrary compression ratios without retraining. Extensive experiments across diverse multimodal benchmarks demonstrate that GRIP-VLM consistently outperforms heuristic and supervised-learning baselines, achieving a superior Pareto frontier and delivering up to a 15\% inference speedup at equal accuracy.
V-LoRA: An Efficient and Flexible System Boosts Vision Applications with LoRA LMM
Nov 01, 2024



Large Multimodal Models (LMMs) have shown significant progress in various complex vision tasks with the solid linguistic and reasoning capacity inherited from large language models (LMMs). Low-rank adaptation (LoRA) offers a promising method to integrate external knowledge into LMMs, compensating for their limitations on domain-specific tasks. However, the existing LoRA model serving is excessively computationally expensive and causes extremely high latency. In this paper, we present an end-to-end solution that empowers diverse vision tasks and enriches vision applications with LoRA LMMs. Our system, VaLoRA, enables accurate and efficient vision tasks by 1) an accuracy-aware LoRA adapter generation approach that generates LoRA adapters rich in domain-specific knowledge to meet application-specific accuracy requirements, 2) an adaptive-tiling LoRA adapters batching operator that efficiently computes concurrent heterogeneous LoRA adapters, and 3) a flexible LoRA adapter orchestration mechanism that manages application requests and LoRA adapters to achieve the lowest average response latency. We prototype VaLoRA on five popular vision tasks on three LMMs. Experiment results reveal that VaLoRA improves 24-62% of the accuracy compared to the original LMMs and reduces 20-89% of the latency compared to the state-of-the-art LoRA model serving systems.
BiSwift: Bandwidth Orchestrator for Multi-Stream Video Analytics on Edge
Dec 25, 2023



High-definition (HD) cameras for surveillance and road traffic have experienced tremendous growth, demanding intensive computation resources for real-time analytics. Recently, offloading frames from the front-end device to the back-end edge server has shown great promise. In multi-stream competitive environments, efficient bandwidth management and proper scheduling are crucial to ensure both high inference accuracy and high throughput. To achieve this goal, we propose BiSwift, a bi-level framework that scales the concurrent real-time video analytics by a novel adaptive hybrid codec integrated with multi-level pipelines, and a global bandwidth controller for multiple video streams. The lower-level front-back-end collaborative mechanism (called adaptive hybrid codec) locally optimizes the accuracy and accelerates end-to-end video analytics for a single stream. The upper-level scheduler aims to accuracy fairness among multiple streams via the global bandwidth controller. The evaluation of BiSwift shows that BiSwift is able to real-time object detection on 9 streams with an edge device only equipped with an NVIDIA RTX3070 (8G) GPU. BiSwift improves 10%$\sim$21% accuracy and presents 1.2$\sim$9$\times$ throughput compared with the state-of-the-art video analytics pipelines.
AccDecoder: Accelerated Decoding for Neural-enhanced Video Analytics
Jan 24, 2023The quality of the video stream is key to neural network-based video analytics. However, low-quality video is inevitably collected by existing surveillance systems because of poor quality cameras or over-compressed/pruned video streaming protocols, e.g., as a result of upstream bandwidth limit. To address this issue, existing studies use quality enhancers (e.g., neural super-resolution) to improve the quality of videos (e.g., resolution) and eventually ensure inference accuracy. Nevertheless, directly applying quality enhancers does not work in practice because it will introduce unacceptable latency. In this paper, we present AccDecoder, a novel accelerated decoder for real-time and neural-enhanced video analytics. AccDecoder can select a few frames adaptively via Deep Reinforcement Learning (DRL) to enhance the quality by neural super-resolution and then up-scale the unselected frames that reference them, which leads to 6-21% accuracy improvement. AccDecoder provides efficient inference capability via filtering important frames using DRL for DNN-based inference and reusing the results for the other frames via extracting the reference relationship among frames and blocks, which results in a latency reduction of 20-80% than baselines.
Multi-Marginal Optimal Transport Defines a Generalized Metric
Feb 26, 2020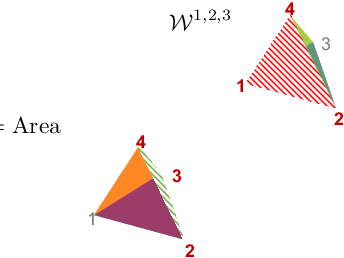
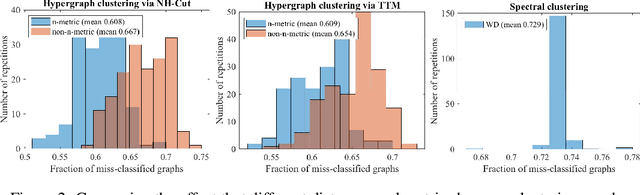
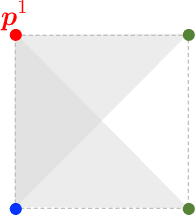
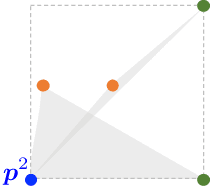
We prove that the multi-marginal optimal transport (MMOT) problem defines a generalized metric. In addition, we prove that the distance induced by MMOT satisfies a generalized triangle inequality that, to leading order, cannot be improved.
Variational Wasserstein Barycenters for Geometric Clustering
Feb 24, 2020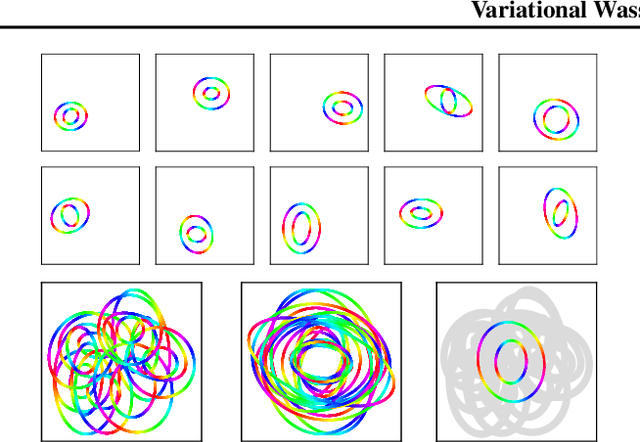
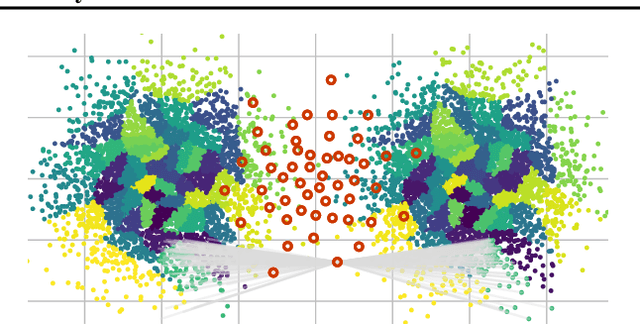
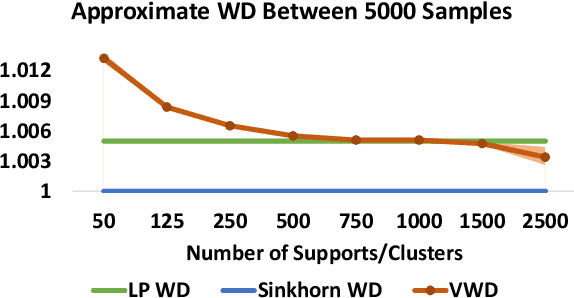
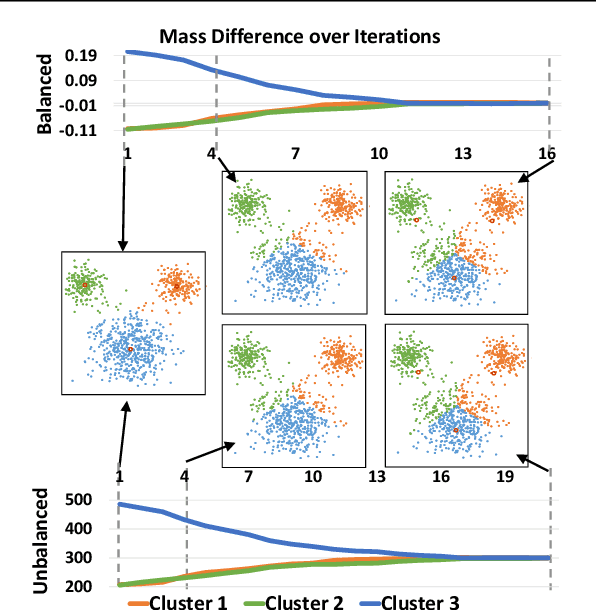
We propose to compute Wasserstein barycenters (WBs) by solving for Monge maps with variational principle. We discuss the metric properties of WBs and explore their connections, especially the connections of Monge WBs, to K-means clustering and co-clustering. We also discuss the feasibility of Monge WBs on unbalanced measures and spherical domains. We propose two new problems -- regularized K-means and Wasserstein barycenter compression. We demonstrate the use of VWBs in solving these clustering-related problems.
Regularized Wasserstein Means Based on Variational Transportation
Dec 02, 2018
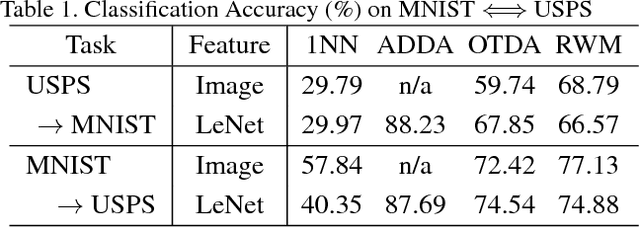
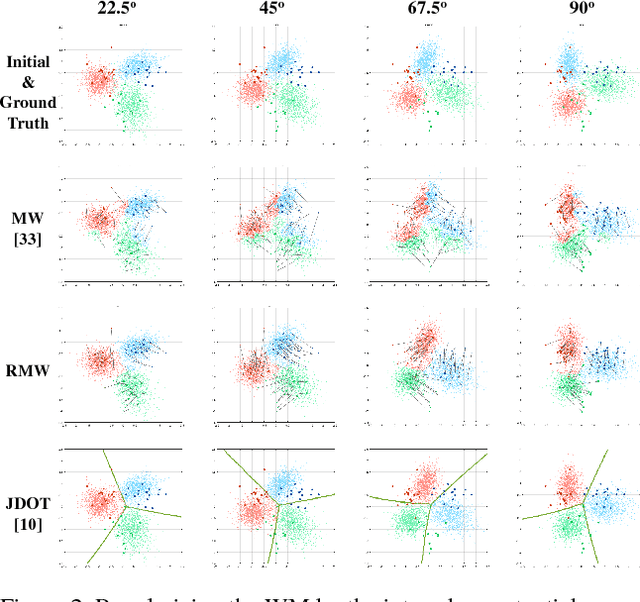
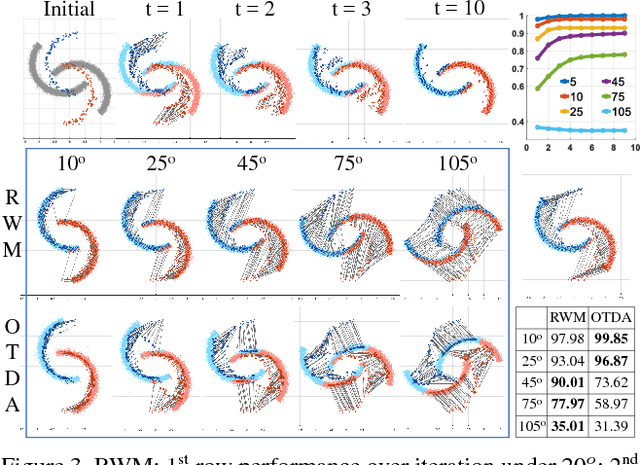
We raise the problem of regularizing Wasserstein means and propose several terms tailored to tackle different problems. Our formulation is based on variational transportation to distribute a sparse discrete measure into the target domain without mass splitting. The resulting sparse representation well captures the desired property of the domain while maintaining a small reconstruction error. We demonstrate the scalability and robustness of our method with examples of domain adaptation and skeleton layout.
Variational Wasserstein Clustering
Jul 26, 2018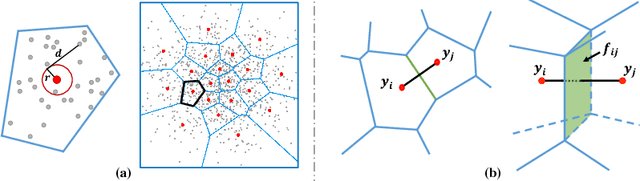

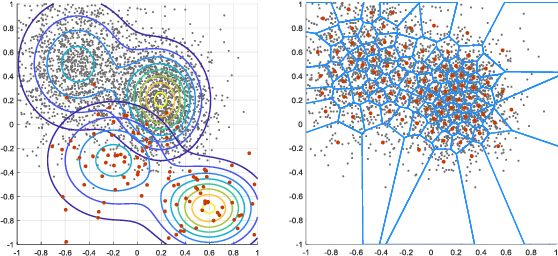
We propose a new clustering method based on optimal transportation. We solve optimal transportation with variational principles, and investigate the use of power diagrams as transportation plans for aggregating arbitrary domains into a fixed number of clusters. We iteratively drive centroids through target domains while maintaining the minimum clustering energy by adjusting the power diagrams. Thus, we simultaneously pursue clustering and the Wasserstein distances between the centroids and the target domains, resulting in a measure-preserving mapping. We demonstrate the use of our method in domain adaptation, remeshing, and representation learning on synthetic and real data.