 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOG-Layout: Hierarchical 3D Scene Generation, Optimization and Editing via Vision-Language Models
Apr 12, 20263D layout generation and editing play a crucial role in Embodied AI and immersive VR interaction. However, manual creation requires tedious labor, while data-driven generation often lacks diversity. The emergence of large models introduces new possibilities for 3D scene synthesis. We present HOG-Layout that enables text-driven hierarchical scene generation, optimization and real-time scene editing with large language models (LLMs) and vision-language models (VLMs). HOG-Layout improves scene semantic consistency and plausibility through retrieval-augmented generation (RAG) technology, incorporates an optimization module to enhance physical consistency, and adopts a hierarchical representation to enhance inference and optimization, achieving real-time editing. Experimental results demonstrate that HOG-Layout produces more reasonable environments compared with existing baselines, while supporting fast and intuitive scene editing.
Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash
Apr 11, 2025Large language models (LLMs) are increasingly being deployed on mobile devices, but the limited DRAM capacity constrains the deployable model size. This paper introduces ActiveFlow, the first LLM inference framework that can achieve adaptive DRAM usage for modern LLMs (not ReLU-based), enabling the scaling up of deployable model sizes. The framework is based on the novel concept of active weight DRAM-flash swapping and incorporates three novel techniques: (1) Cross-layer active weights preloading. It uses the activations from the current layer to predict the active weights of several subsequent layers, enabling computation and data loading to overlap, as well as facilitating large I/O transfers. (2) Sparsity-aware self-distillation. It adjusts the active weights to align with the dense-model output distribution, compensating for approximations introduced by contextual sparsity. (3) Active weight DRAM-flash swapping pipeline. It orchestrates the DRAM space allocation among the hot weight cache, preloaded active weights, and computation-involved weights based on available memory. Results show ActiveFlow achieves the performance-cost Pareto frontier compared to existing efficiency optimization methods.
KVShare: Semantic-Aware Key-Value Cache Sharing for Efficient Large Language Model Inference
Mar 17, 2025



This paper presents KVShare, a multi-user Key-Value (KV) Cache sharing technology based on semantic similarity, designed to enhance the inference efficiency of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs). Addressing the limitations of existing prefix caching (strict text prefix matching) and semantic caching (loss of response diversity), KVShare achieves fine-grained KV cache reuse through semantic alignment algorithms and differential editing operations. Experiments on real-world user conversation datasets demonstrate that KVShare improves KV cache hit rates by over 60%, while maintaining output quality comparable to full computation (no significant degradation in BLEU and Rouge-L metrics). This approach effectively reduces GPU resource consumption and is applicable to scenarios with repetitive queries, such as healthcare and education.
MobiFuse: A High-Precision On-device Depth Perception System with Multi-Data Fusion
Dec 18, 2024



We present MobiFuse, a high-precision depth perception system on mobile devices that combines dual RGB and Time-of-Flight (ToF) cameras. To achieve this, we leverage physical principles from various environmental factors to propose the Depth Error Indication (DEI) modality, characterizing the depth error of ToF and stereo-matching. Furthermore, we employ a progressive fusion strategy, merging geometric features from ToF and stereo depth maps with depth error features from the DEI modality to create precise depth maps. Additionally, we create a new ToF-Stereo depth dataset, RealToF, to train and validate our model. Our experiments demonstrate that MobiFuse excels over baselines by significantly reducing depth measurement errors by up to 77.7%. It also showcases strong generalization across diverse datasets and proves effectiveness in two downstream tasks: 3D reconstruction and 3D segmentation. The demo video of MobiFuse in real-life scenarios is available at the de-identified YouTube link(https://youtu.be/jy-Sp7T1LVs).
EdgeOAR: Real-time Online Action Recognition On Edge Devices
Dec 02, 2024



This paper addresses the challenges of Online Action Recognition (OAR), a framework that involves instantaneous analysis and classification of behaviors in video streams. OAR must operate under stringent latency constraints, making it an indispensable component for real-time feedback for edge computing. Existing methods, which typically rely on the processing of entire video clips, fall short in scenarios requiring immediate recognition. To address this, we designed EdgeOAR, a novel framework specifically designed for OAR on edge devices. EdgeOAR includes the Early Exit-oriented Task-specific Feature Enhancement Module (TFEM), which comprises lightweight submodules to optimize features in both temporal and spatial dimensions. We design an iterative training method to enable TFEM learning features from the beginning of the video. Additionally, EdgeOAR includes an Inverse Information Entropy (IIE) and Modality Consistency (MC)-driven fusion module to fuse features and make better exit decisions. This design overcomes the two main challenges: robust modeling of spatio-temporal action representations with limited initial frames in online video streams and balancing accuracy and efficiency on resource-constrained edge devices. Experiments show that on the UCF-101 dataset, our method EdgeOAR reduces latency by 99.23% and energy consumption by 99.28% compared to state-of-the-art (SOTA) method. And achieves an adequate accuracy on edge devices.
MultiCounter: Multiple Action Agnostic Repetition Counting in Untrimmed Videos
Sep 06, 2024



Multi-instance Repetitive Action Counting (MRAC) aims to estimate the number of repetitive actions performed by multiple instances in untrimmed videos, commonly found in human-centric domains like sports and exercise. In this paper, we propose MultiCounter, a fully end-to-end deep learning framework that enables simultaneous detection, tracking, and counting of repetitive actions of multiple human instances. Specifically, MultiCounter incorporates two novel modules: 1) mixed spatiotemporal interaction for efficient context correlation across consecutive frames, and 2) task-specific heads for accurate perception of periodic boundaries and generalization for action-agnostic human instances. We train MultiCounter on a synthetic dataset called MultiRep generated from annotated real-world videos. Experiments on the MultiRep dataset validate the fundamental challenge of MRAC tasks and showcase the superiority of our proposed model. Compared to ByteTrack+RepNet, a solution that combines an advanced tracker with a single repetition counter, MultiCounter substantially improves Period-mAP by 41.0%, reduces AvgMAE by 58.6%, and increases AvgOBO 1.48 times. This sets a new benchmark in the field of MRAC. Moreover, MultiCounter runs in real-time on a commodity GPU server and is insensitive to the number of human instances in a video.
A First Look At Efficient And Secure On-Device LLM Inference Against KV Leakage
Sep 06, 2024



Running LLMs on end devices has garnered significant attention recently due to their advantages in privacy preservation. With the advent of lightweight LLM models and specially designed GPUs, on-device LLM inference has achieved the necessary accuracy and performance metrics. However, we have identified that LLM inference on GPUs can leak privacy-sensitive intermediate information, specifically the KV pairs. An attacker could exploit these KV pairs to reconstruct the entire user conversation, leading to significant vulnerabilities. Existing solutions, such as Fully Homomorphic Encryption (FHE) and Trusted Execution Environments (TEE), are either too computation-intensive or resource-limited. To address these issues, we designed KV-Shield, which operates in two phases. In the initialization phase, it permutes the weight matrices so that all KV pairs are correspondingly permuted. During the runtime phase, the attention vector is inversely permuted to ensure the correctness of the layer output. All permutation-related operations are executed within the TEE, ensuring that insecure GPUs cannot access the original KV pairs, thus preventing conversation reconstruction. Finally, we theoretically analyze the correctness of KV-Shield, along with its advantages and overhead.
Accelerating In-Browser Deep Learning Inference on Diverse Edge Clients through Just-in-Time Kernel Optimizations
Sep 16, 2023



Web applications are increasingly becoming the primary platform for AI service delivery, making in-browser deep learning (DL) inference more prominent. However, current in-browser inference systems fail to effectively utilize advanced web programming techniques and customize kernels for various client devices, leading to suboptimal performance. To address the issues, this paper presents the first in-browser inference system, nn-JIT.web, which enables just-in-time (JIT) auto-generation of optimized kernels for both CPUs and GPUs during inference. The system achieves this by using two novel web programming techniques that can significantly reduce kernel generation time, compared to other tensor compilers such as TVM, while maintaining or even improving performance. The first technique, Tensor-Web Compiling Co-Design, lowers compiling costs by unifying tensor and web compiling and eliminating redundant and ineffective compiling passes. The second technique, Web-Specific Lite Kernel Optimization Space Design, reduces kernel tuning costs by focusing on web programming requirements and efficient hardware resource utilization, limiting the optimization space to only dozens. nn-JIT.web is evaluated for modern transformer models on a range of client devices, including the mainstream CPUs and GPUs from ARM, Intel, AMD and Nvidia. Results show that nn-JIT.web can achieve up to 8.2x faster within 30 seconds compared to the baselines across various models.
Efficient Federated Meta-Learning over Multi-Access Wireless Networks
Sep 01, 2021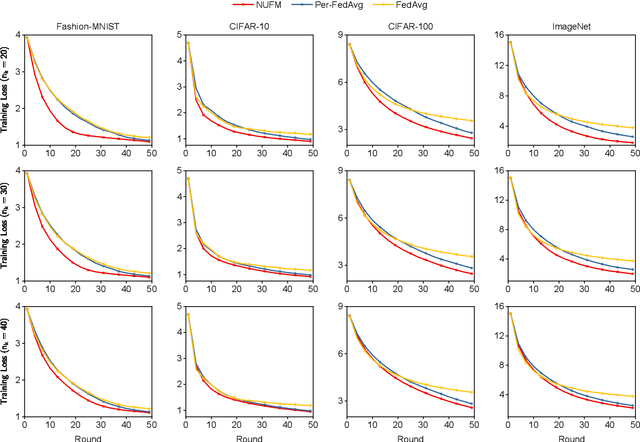
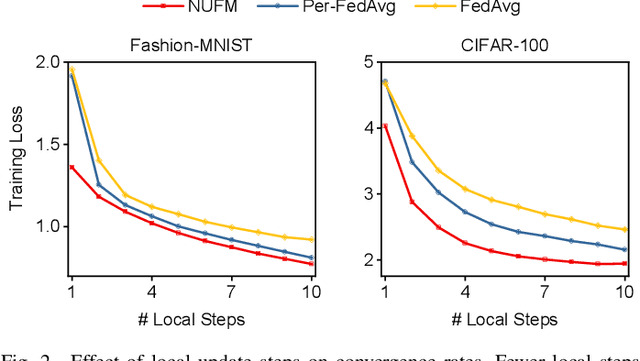
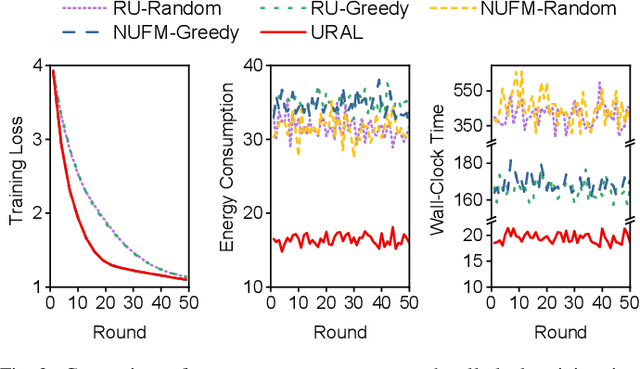
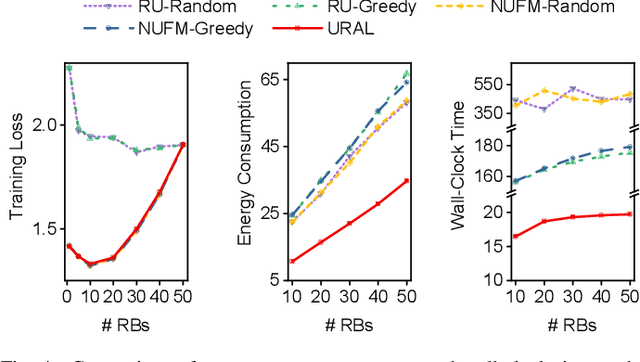
Federated meta-learning (FML) has emerged as a promising paradigm to cope with the data limitation and heterogeneity challenges in today's edge learning arena. However, its performance is often limited by slow convergence and corresponding low communication efficiency. In addition, since the available radio spectrum and IoT devices' energy capacity are usually insufficient, it is crucial to control the resource allocation and energy consumption when deploying FML in practical wireless networks. To overcome the challenges, in this paper, we rigorously analyze each device's contribution to the global loss reduction in each round and develop an FML algorithm (called NUFM) with a non-uniform device selection scheme to accelerate the convergence. After that, we formulate a resource allocation problem integrating NUFM in multi-access wireless systems to jointly improve the convergence rate and minimize the wall-clock time along with energy cost. By deconstructing the original problem step by step, we devise a joint device selection and resource allocation strategy to solve the problem with theoretical guarantees. Further, we show that the computational complexity of NUFM can be reduced from $O(d^2)$ to $O(d)$ (with the model dimension $d$) via combining two first-order approximation techniques. Extensive simulation results demonstrate the effectiveness and superiority of the proposed methods in comparison with existing baselines.