 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
Deep reinforcement learning for tracking a moving target in jellyfish-like swimming
Sep 13, 2024



We develop a deep reinforcement learning method for training a jellyfish-like swimmer to effectively track a moving target in a two-dimensional flow. This swimmer is a flexible object equipped with a muscle model based on torsional springs. We employ a deep Q-network (DQN) that takes the swimmer's geometry and dynamic parameters as inputs, and outputs actions which are the forces applied to the swimmer. In particular, we introduce an action regulation to mitigate the interference from complex fluid-structure interactions. The goal of these actions is to navigate the swimmer to a target point in the shortest possible time. In the DQN training, the data on the swimmer's motions are obtained from simulations conducted using the immersed boundary method. During tracking a moving target, there is an inherent delay between the application of forces and the corresponding response of the swimmer's body due to hydrodynamic interactions between the shedding vortices and the swimmer's own locomotion. Our tests demonstrate that the swimmer, with the DQN agent and action regulation, is able to dynamically adjust its course based on its instantaneous state. This work extends the application scope of machine learning in controlling flexible objects within fluid environments.
RoomDiffusion: A Specialized Diffusion Model in the Interior Design Industry
Sep 05, 2024



Recent advancements in text-to-image diffusion models have significantly transformed visual content generation, yet their application in specialized fields such as interior design remains underexplored. In this paper, we present RoomDiffusion, a pioneering diffusion model meticulously tailored for the interior design industry. To begin with, we build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. Subsequently, techniques such as multiaspect training, multi-stage fine-tune and model fusion are applied to enhance both the visual appeal and precision of the generated results. Lastly, leveraging the latent consistency Distillation method, we distill and expedite the model for optimal efficiency. Unlike existing models optimized for general scenarios, RoomDiffusion addresses specific challenges in interior design, such as lack of fashion, high furniture duplication rate, and inaccurate style. Through our holistic human evaluation protocol with more than 20 professional human evaluators, RoomDiffusion demonstrates industry-leading performance in terms of aesthetics, accuracy, and efficiency, surpassing all existing open source models such as stable diffusion and SDXL.
Optimizing Automated Picking Systems in Warehouse Robots Using Machine Learning
Aug 29, 2024



With the rapid growth of global e-commerce, the demand for automation in the logistics industry is increasing. This study focuses on automated picking systems in warehouses, utilizing deep learning and reinforcement learning technologies to enhance picking efficiency and accuracy while reducing system failure rates. Through empirical analysis, we demonstrate the effectiveness of these technologies in improving robot picking performance and adaptability to complex environments. The results show that the integrated machine learning model significantly outperforms traditional methods, effectively addressing the challenges of peak order processing, reducing operational errors, and improving overall logistics efficiency. Additionally, by analyzing environmental factors, this study further optimizes system design to ensure efficient and stable operation under variable conditions. This research not only provides innovative solutions for logistics automation but also offers a theoretical and empirical foundation for future technological development and application.
Unlocking the Potential: Benchmarking Large Language Models in Water Engineering and Research
Jul 22, 2024



Recent advancements in Large Language Models (LLMs) have sparked interest in their potential applications across various fields. This paper embarked on a pivotal inquiry: Can existing LLMs effectively serve as "water expert models" for water engineering and research tasks? This study was the first to evaluate LLMs' contributions across various water engineering and research tasks by establishing a domain-specific benchmark suite, namely, WaterER. Herein, we prepared 983 tasks related to water engineering and research, categorized into "wastewater treatment", "environmental restoration", "drinking water treatment and distribution", "sanitation", "anaerobic digestion" and "contaminants assessment". We evaluated the performance of seven LLMs (i.e., GPT-4, GPT-3.5, Gemini, GLM-4, ERNIE, QWEN and Llama3) on these tasks. We highlighted the strengths of GPT-4 in handling diverse and complex tasks of water engineering and water research, the specialized capabilities of Gemini in academic contexts, Llama3's strongest capacity to answer Chinese water engineering questions and the competitive performance of Chinese-oriented models like GLM-4, ERNIE and QWEN in some water engineering tasks. More specifically, current LLMs excelled particularly in generating precise research gaps for papers on "contaminants and related water quality monitoring and assessment". Additionally, they were more adept at creating appropriate titles for research papers on "treatment processes for wastewaters", "environmental restoration", and "drinking water treatment". Overall, this study pioneered evaluating LLMs in water engineering and research by introducing the WaterER benchmark to assess the trustworthiness of their predictions. This standardized evaluation framework would also drive future advancements in LLM technology by using targeting datasets, propelling these models towards becoming true "water expert".
Data Adaptive Traceback for Vision-Language Foundation Models in Image Classification
Jul 11, 2024Vision-language foundation models have been incredibly successful in a wide range of downstream computer vision tasks using adaptation methods. However, due to the high cost of obtaining pre-training datasets, pairs with weak image-text correlation in the data exist in large numbers. We call them weak-paired samples. Due to the limitations of these weak-paired samples, the pre-training model are unable to mine all the knowledge from pre-training data. The existing adaptation methods do not consider the missing knowledge, which may lead to crucial task-related knowledge for the downstream tasks being ignored. To address this issue, we propose a new adaptation framework called Data Adaptive Traceback (DAT). Specifically, we utilize a zero-shot-based method to extract the most downstream task-related subset of the pre-training data to enable the downstream tasks. Furthermore, we adopt a pseudo-label-based semi-supervised technique to reuse the pre-training images and a vision-language contrastive learning method to address the confirmation bias issue in semi-supervised learning. We conduct extensive experiments that show our proposed DAT approach meaningfully improves various benchmark datasets performance over traditional adaptation methods by simply.
BACON: Supercharge Your VLM with Bag-of-Concept Graph to Mitigate Hallucinations
Jul 03, 2024



This paper presents Bag-of-Concept Graph (BACON) to gift models with limited linguistic abilities to taste the privilege of Vision Language Models (VLMs) and boost downstream tasks such as detection, visual question answering (VQA), and image generation. Since the visual scenes in physical worlds are structured with complex relations between objects, BACON breaks down annotations into basic minimum elements and presents them in a graph structure. Element-wise style enables easy understanding, and structural composition liberates difficult locating. Careful prompt design births the BACON captions with the help of public-available VLMs and segmentation methods. In this way, we gather a dataset with 100K annotated images, which endow VLMs with remarkable capabilities, such as accurately generating BACON, transforming prompts into BACON format, envisioning scenarios in the style of BACONr, and dynamically modifying elements within BACON through interactive dialogue and more. Wide representative experiments, including detection, VQA, and image generation tasks, tell BACON as a lifeline to achieve previous out-of-reach tasks or excel in their current cutting-edge solutions.
Generative prediction of flow field based on the diffusion model
Jun 30, 2024



We propose a geometry-to-flow diffusion model that utilizes the input of obstacle shape to predict a flow field past the obstacle. The model is based on a learnable Markov transition kernel to recover the data distribution from the Gaussian distribution. The Markov process is conditioned on the obstacle geometry, estimating the noise to be removed at each step, implemented via a U-Net. A cross-attention mechanism incorporates the geometry as a prompt. We train the geometry-to-flow diffusion model using a dataset of flows past simple obstacles, including the circle, ellipse, rectangle, and triangle. For comparison, the CNN model is trained using the same dataset. Tests are carried out on flows past obstacles with simple and complex geometries, representing interpolation and extrapolation on the geometry condition, respectively. In the test set, challenging scenarios include a cross and characters `PKU'. Generated flow fields show that the geometry-to-flow diffusion model is superior to the CNN model in predicting instantaneous flow fields and handling complex geometries. Quantitative analysis of the model accuracy and divergence in the fields demonstrate the high robustness of the diffusion model, indicating that the diffusion model learns physical laws implicitly.
PhyBench: A Physical Commonsense Benchmark for Evaluating Text-to-Image Models
Jun 17, 2024
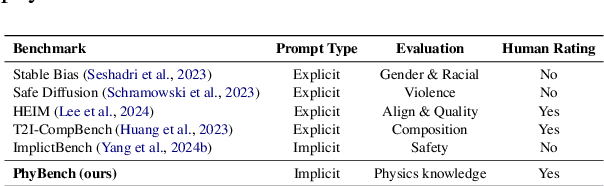

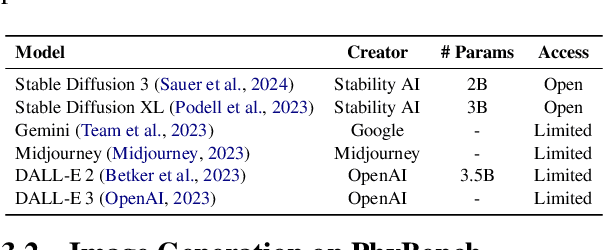
Text-to-image (T2I) models have made substantial progress in generating images from textual prompts. However, they frequently fail to produce images consistent with physical commonsense, a vital capability for applications in world simulation and everyday tasks. Current T2I evaluation benchmarks focus on metrics such as accuracy, bias, and safety, neglecting the evaluation of models' internal knowledge, particularly physical commonsense. To address this issue, we introduce PhyBench, a comprehensive T2I evaluation dataset comprising 700 prompts across 4 primary categories: mechanics, optics, thermodynamics, and material properties, encompassing 31 distinct physical scenarios. We assess 6 prominent T2I models, including proprietary models DALLE3 and Gemini, and demonstrate that incorporating physical principles into prompts enhances the models' ability to generate physically accurate images. Our findings reveal that: (1) even advanced models frequently err in various physical scenarios, except for optics; (2) GPT-4o, with item-specific scoring instructions, effectively evaluates the models' understanding of physical commonsense, closely aligning with human assessments; and (3) current T2I models are primarily focused on text-to-image translation, lacking profound reasoning regarding physical commonsense. We advocate for increased attention to the inherent knowledge within T2I models, beyond their utility as mere image generation tools. The code and data are available at https://github.com/OpenGVLab/PhyBench.
Rethinking Human Evaluation Protocol for Text-to-Video Models: Enhancing Reliability,Reproducibility, and Practicality
Jun 13, 2024



Recent text-to-video (T2V) technology advancements, as demonstrated by models such as Gen2, Pika, and Sora, have significantly broadened its applicability and popularity. Despite these strides, evaluating these models poses substantial challenges. Primarily, due to the limitations inherent in automatic metrics, manual evaluation is often considered a superior method for assessing T2V generation. However, existing manual evaluation protocols face reproducibility, reliability, and practicality issues. To address these challenges, this paper introduces the Text-to-Video Human Evaluation (T2VHE) protocol, a comprehensive and standardized protocol for T2V models. The T2VHE protocol includes well-defined metrics, thorough annotator training, and an effective dynamic evaluation module. Experimental results demonstrate that this protocol not only ensures high-quality annotations but can also reduce evaluation costs by nearly 50%. We will open-source the entire setup of the T2VHE protocol, including the complete protocol workflow, the dynamic evaluation component details, and the annotation interface code. This will help communities establish more sophisticated human assessment protocols.