 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Generalist: Self-Improving Vision-Language-Action Models for Crafting 3D Worlds
Jul 09, 2025Despite large-scale pretraining endowing models with language and vision reasoning capabilities, improving their spatial reasoning capability remains challenging due to the lack of data grounded in the 3D world. While it is possible for humans to manually create immersive and interactive worlds through 3D graphics, as seen in applications such as VR, gaming, and robotics, this process remains highly labor-intensive. In this paper, we propose a scalable method for generating high-quality 3D environments that can serve as training data for foundation models. We recast 3D environment building as a sequential decision-making problem, employing Vision-Language-Models (VLMs) as policies that output actions to jointly craft a 3D environment's layout, materials, lighting, and assets. Our proposed framework, 3D-Generalist, trains VLMs to generate more prompt-aligned 3D environments via self-improvement fine-tuning. We demonstrate the effectiveness of 3D-Generalist and the proposed training strategy in generating simulation-ready 3D environments. Furthermore, we demonstrate its quality and scalability in synthetic data generation by pretraining a vision foundation model on the generated data. After fine-tuning the pre-trained model on downstream tasks, we show that it surpasses models pre-trained on meticulously human-crafted synthetic data and approaches results achieved with real data orders of magnitude larger.
Symmetrical Visual Contrastive Optimization: Aligning Vision-Language Models with Minimal Contrastive Images
Feb 19, 2025Recent studies have shown that Large Vision-Language Models (VLMs) tend to neglect image content and over-rely on language-model priors, resulting in errors in visually grounded tasks and hallucinations. We hypothesize that this issue arises because existing VLMs are not explicitly trained to generate texts that are accurately grounded in fine-grained image details. To enhance visual feedback during VLM training, we propose S-VCO (Symmetrical Visual Contrastive Optimization), a novel finetuning objective that steers the model toward capturing important visual details and aligning them with corresponding text tokens. To further facilitate this detailed alignment, we introduce MVC, a paired image-text dataset built by automatically filtering and augmenting visual counterfactual data to challenge the model with hard contrastive cases involving Minimal Visual Contrasts. Experiments show that our method consistently improves VLM performance across diverse benchmarks covering various abilities and domains, achieving up to a 22% reduction in hallucinations, and significant gains in vision-centric and general tasks. Notably, these improvements become increasingly pronounced in benchmarks with higher visual dependency. In short, S-VCO offers a significant enhancement of VLM's visually-dependent task performance while retaining or even improving the model's general abilities. We opensource our code at https://s-vco.github.io/
LayoutVLM: Differentiable Optimization of 3D Layout via Vision-Language Models
Dec 03, 2024



Open-universe 3D layout generation arranges unlabeled 3D assets conditioned on language instruction. Large language models (LLMs) struggle with generating physically plausible 3D scenes and adherence to input instructions, particularly in cluttered scenes. We introduce LayoutVLM, a framework and scene layout representation that exploits the semantic knowledge of Vision-Language Models (VLMs) and supports differentiable optimization to ensure physical plausibility. LayoutVLM employs VLMs to generate two mutually reinforcing representations from visually marked images, and a self-consistent decoding process to improve VLMs spatial planning. Our experiments show that LayoutVLM addresses the limitations of existing LLM and constraint-based approaches, producing physically plausible 3D layouts better aligned with the semantic intent of input language instructions. We also demonstrate that fine-tuning VLMs with the proposed scene layout representation extracted from existing scene datasets can improve performance.
GRS: Generating Robotic Simulation Tasks from Real-World Images
Oct 20, 2024



We introduce GRS (Generating Robotic Simulation tasks), a novel system to address the challenge of real-to-sim in robotics, computer vision, and AR/VR. GRS enables the creation of digital twin simulations from single real-world RGB-D observations, complete with diverse, solvable tasks for virtual agent training. We use state-of-the-art vision-language models (VLMs) to achieve a comprehensive real-to-sim pipeline. GRS operates in three stages: 1) scene comprehension using SAM2 for object segmentation and VLMs for object description, 2) matching identified objects with simulation-ready assets, and 3) generating contextually appropriate robotic tasks. Our approach ensures simulations align with task specifications by generating test suites designed to verify adherence to the task specification. We introduce a router that iteratively refines the simulation and test code to ensure the simulation is solvable by a robot policy while remaining aligned to the task specification. Our experiments demonstrate the system's efficacy in accurately identifying object correspondence, which allows us to generate task environments that closely match input environments, and enhance automated simulation task generation through our novel router mechanism.
FactorSim: Generative Simulation via Factorized Representation
Sep 26, 2024Generating simulations to train intelligent agents in game-playing and robotics from natural language input, from user input or task documentation, remains an open-ended challenge. Existing approaches focus on parts of this challenge, such as generating reward functions or task hyperparameters. Unlike previous work, we introduce FACTORSIM that generates full simulations in code from language input that can be used to train agents. Exploiting the structural modularity specific to coded simulations, we propose to use a factored partially observable Markov decision process representation that allows us to reduce context dependence during each step of the generation. For evaluation, we introduce a generative simulation benchmark that assesses the generated simulation code's accuracy and effectiveness in facilitating zero-shot transfers in reinforcement learning settings. We show that FACTORSIM outperforms existing methods in generating simulations regarding prompt alignment (e.g., accuracy), zero-shot transfer abilities, and human evaluation. We also demonstrate its effectiveness in generating robotic tasks.
Holodeck: Language Guided Generation of 3D Embodied AI Environments
Dec 14, 20233D simulated environments play a critical role in Embodied AI, but their creation requires expertise and extensive manual effort, restricting their diversity and scope. To mitigate this limitation, we present Holodeck, a system that generates 3D environments to match a user-supplied prompt fully automatedly. Holodeck can generate diverse scenes, e.g., arcades, spas, and museums, adjust the designs for styles, and can capture the semantics of complex queries such as "apartment for a researcher with a cat" and "office of a professor who is a fan of Star Wars". Holodeck leverages a large language model (GPT-4) for common sense knowledge about what the scene might look like and uses a large collection of 3D assets from Objaverse to populate the scene with diverse objects. To address the challenge of positioning objects correctly, we prompt GPT-4 to generate spatial relational constraints between objects and then optimize the layout to satisfy those constraints. Our large-scale human evaluation shows that annotators prefer Holodeck over manually designed procedural baselines in residential scenes and that Holodeck can produce high-quality outputs for diverse scene types. We also demonstrate an exciting application of Holodeck in Embodied AI, training agents to navigate in novel scenes like music rooms and daycares without human-constructed data, which is a significant step forward in developing general-purpose embodied agents.
Partial-View Object View Synthesis via Filtered Inversion
Apr 03, 2023



We propose Filtering Inversion (FINV), a learning framework and optimization process that predicts a renderable 3D object representation from one or few partial views. FINV addresses the challenge of synthesizing novel views of objects from partial observations, spanning cases where the object is not entirely in view, is partially occluded, or is only observed from similar views. To achieve this, FINV learns shape priors by training a 3D generative model. At inference, given one or more views of a novel real-world object, FINV first finds a set of latent codes for the object by inverting the generative model from multiple initial seeds. Maintaining the set of latent codes, FINV filters and resamples them after receiving each new observation, akin to particle filtering. The generator is then finetuned for each latent code on the available views in order to adapt to novel objects. We show that FINV successfully synthesizes novel views of real-world objects (e.g., chairs, tables, and cars), even if the generative prior is trained only on synthetic objects. The ability to address the sim-to-real problem allows FINV to be used for object categories without real-world datasets. FINV achieves state-of-the-art performance on multiple real-world datasets, recovers object shape and texture from partial and sparse views, is robust to occlusion, and is able to incrementally improve its representation with more observations.
Interaction Modeling with Multiplex Attention
Aug 23, 2022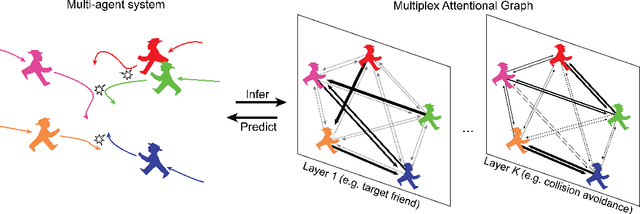
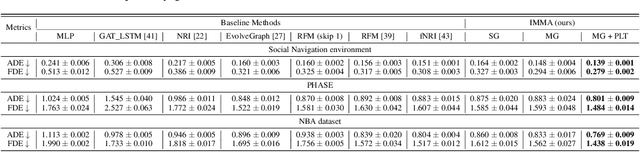
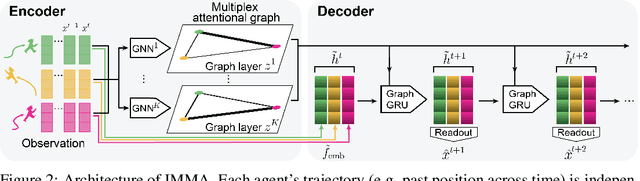
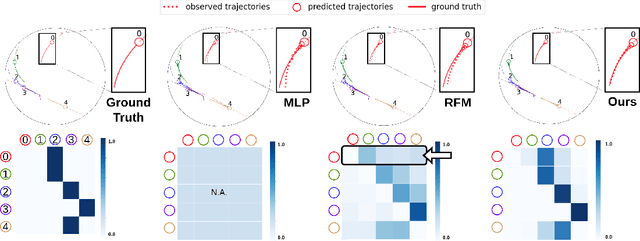
Modeling multi-agent systems requires understanding how agents interact. Such systems are often difficult to model because they can involve a variety of types of interactions that layer together to drive rich social behavioral dynamics. Here we introduce a method for accurately modeling multi-agent systems. We present Interaction Modeling with Multiplex Attention (IMMA), a forward prediction model that uses a multiplex latent graph to represent multiple independent types of interactions and attention to account for relations of different strengths. We also introduce Progressive Layer Training, a training strategy for this architecture. We show that our approach outperforms state-of-the-art models in trajectory forecasting and relation inference, spanning three multi-agent scenarios: social navigation, cooperative task achievement, and team sports. We further demonstrate that our approach can improve zero-shot generalization and allows us to probe how different interactions impact agent behavior.
Equivariant Neural Network for Factor Graphs
Sep 29, 2021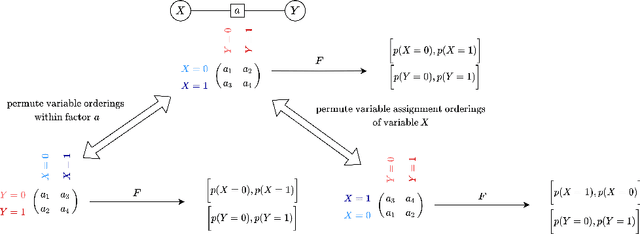

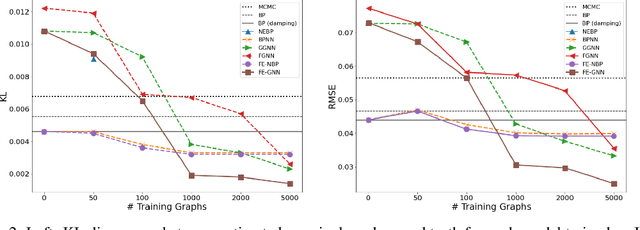
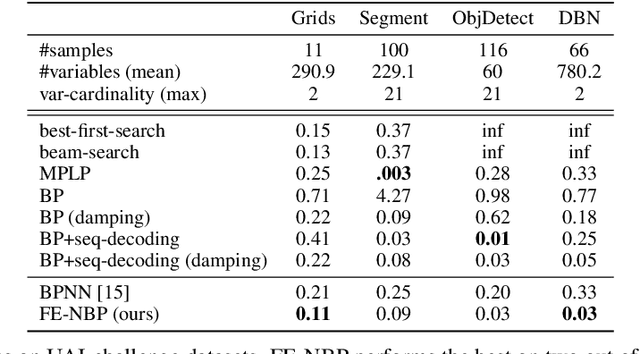
Several indices used in a factor graph data structure can be permuted without changing the underlying probability distribution. An algorithm that performs inference on a factor graph should ideally be equivariant or invariant to permutations of global indices of nodes, variable orderings within a factor, and variable assignment orderings. However, existing neural network-based inference procedures fail to take advantage of this inductive bias. In this paper, we precisely characterize these isomorphic properties of factor graphs and propose two inference models: Factor-Equivariant Neural Belief Propagation (FE-NBP) and Factor-Equivariant Graph Neural Networks (FE-GNN). FE-NBP is a neural network that generalizes BP and respects each of the above properties of factor graphs while FE-GNN is an expressive GNN model that relaxes an isomorphic property in favor of greater expressivity. Empirically, we demonstrate on both real-world and synthetic datasets, for both marginal inference and MAP inference, that FE-NBP and FE-GNN together cover a range of sample complexity regimes: FE-NBP achieves state-of-the-art performance on small datasets while FE-GNN achieves state-of-the-art performance on large datasets.
Physion: Evaluating Physical Prediction from Vision in Humans and Machines
Jun 17, 2021
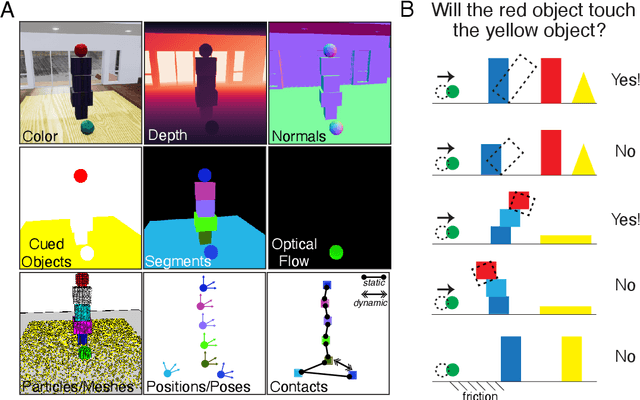
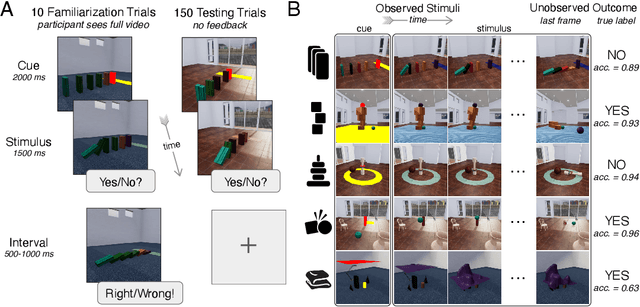
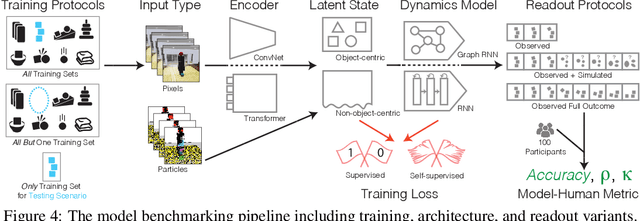
While machine learning algorithms excel at many challenging visual tasks, it is unclear that they can make predictions about commonplace real world physical events. Here, we present a visual and physical prediction benchmark that precisely measures this capability. In realistically simulating a wide variety of physical phenomena -- rigid and soft-body collisions, stable multi-object configurations, rolling and sliding, projectile motion -- our dataset presents a more comprehensive challenge than existing benchmarks. Moreover, we have collected human responses for our stimuli so that model predictions can be directly compared to human judgments. We compare an array of algorithms -- varying in their architecture, learning objective, input-output structure, and training data -- on their ability to make diverse physical predictions. We find that graph neural networks with access to the physical state best capture human behavior, whereas among models that receive only visual input, those with object-centric representations or pretraining do best but fall far short of human accuracy. This suggests that extracting physically meaningful representations of scenes is the main bottleneck to achieving human-like visual prediction. We thus demonstrate how our benchmark can identify areas for improvement and measure progress on this key aspect of physical understanding.