 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeath of the Novel(ty): Beyond n-Gram Novelty as a Metric for Textual Creativity
Sep 26, 2025



N-gram novelty is widely used to evaluate language models' ability to generate text outside of their training data. More recently, it has also been adopted as a metric for measuring textual creativity. However, theoretical work on creativity suggests that this approach may be inadequate, as it does not account for creativity's dual nature: novelty (how original the text is) and appropriateness (how sensical and pragmatic it is). We investigate the relationship between this notion of creativity and n-gram novelty through 7542 expert writer annotations (n=26) of novelty, pragmaticality, and sensicality via close reading of human and AI-generated text. We find that while n-gram novelty is positively associated with expert writer-judged creativity, ~91% of top-quartile expressions by n-gram novelty are not judged as creative, cautioning against relying on n-gram novelty alone. Furthermore, unlike human-written text, higher n-gram novelty in open-source LLMs correlates with lower pragmaticality. In an exploratory study with frontier close-source models, we additionally confirm that they are less likely to produce creative expressions than humans. Using our dataset, we test whether zero-shot, few-shot, and finetuned models are able to identify creative expressions (a positive aspect of writing) and non-pragmatic ones (a negative aspect). Overall, frontier LLMs exhibit performance much higher than random but leave room for improvement, especially struggling to identify non-pragmatic expressions. We further find that LLM-as-a-Judge novelty scores from the best-performing model were predictive of expert writer preferences.
V-FLUTE: Visual Figurative Language Understanding with Textual Explanations
May 02, 2024Large Vision-Language models (VLMs) have demonstrated strong reasoning capabilities in tasks requiring a fine-grained understanding of literal images and text, such as visual question-answering or visual entailment. However, there has been little exploration of these models' capabilities when presented with images and captions containing figurative phenomena such as metaphors or humor, the meaning of which is often implicit. To close this gap, we propose a new task and a high-quality dataset: Visual Figurative Language Understanding with Textual Explanations (V-FLUTE). We frame the visual figurative language understanding problem as an explainable visual entailment task, where the model has to predict whether the image (premise) entails a claim (hypothesis) and justify the predicted label with a textual explanation. Using a human-AI collaboration framework, we build a high-quality dataset, V-FLUTE, that contains 6,027 <image, claim, label, explanation> instances spanning five diverse multimodal figurative phenomena: metaphors, similes, idioms, sarcasm, and humor. The figurative phenomena can be present either in the image, the caption, or both. We further conduct both automatic and human evaluations to assess current VLMs' capabilities in understanding figurative phenomena.
Learning to Follow Object-Centric Image Editing Instructions Faithfully
Oct 29, 2023



Natural language instructions are a powerful interface for editing the outputs of text-to-image diffusion models. However, several challenges need to be addressed: 1) underspecification (the need to model the implicit meaning of instructions) 2) grounding (the need to localize where the edit has to be performed), 3) faithfulness (the need to preserve the elements of the image not affected by the edit instruction). Current approaches focusing on image editing with natural language instructions rely on automatically generated paired data, which, as shown in our investigation, is noisy and sometimes nonsensical, exacerbating the above issues. Building on recent advances in segmentation, Chain-of-Thought prompting, and visual question answering, we significantly improve the quality of the paired data. In addition, we enhance the supervision signal by highlighting parts of the image that need to be changed by the instruction. The model fine-tuned on the improved data is capable of performing fine-grained object-centric edits better than state-of-the-art baselines, mitigating the problems outlined above, as shown by automatic and human evaluations. Moreover, our model is capable of generalizing to domains unseen during training, such as visual metaphors.
NormDial: A Comparable Bilingual Synthetic Dialog Dataset for Modeling Social Norm Adherence and Violation
Oct 25, 2023



Social norms fundamentally shape interpersonal communication. We present NormDial, a high-quality dyadic dialogue dataset with turn-by-turn annotations of social norm adherences and violations for Chinese and American cultures. Introducing the task of social norm observance detection, our dataset is synthetically generated in both Chinese and English using a human-in-the-loop pipeline by prompting large language models with a small collection of expert-annotated social norms. We show that our generated dialogues are of high quality through human evaluation and further evaluate the performance of existing large language models on this task. Our findings point towards new directions for understanding the nuances of social norms as they manifest in conversational contexts that span across languages and cultures.
ICLEF: In-Context Learning with Expert Feedback for Explainable Style Transfer
Sep 15, 2023



While state-of-the-art language models excel at the style transfer task, current work does not address explainability of style transfer systems. Explanations could be generated using large language models such as GPT-3.5 and GPT-4, but the use of such complex systems is inefficient when smaller, widely distributed, and transparent alternatives are available. We propose a framework to augment and improve a formality style transfer dataset with explanations via model distillation from ChatGPT. To further refine the generated explanations, we propose a novel way to incorporate scarce expert human feedback using in-context learning (ICLEF: In-Context Learning from Expert Feedback) by prompting ChatGPT to act as a critic to its own outputs. We use the resulting dataset of 9,960 explainable formality style transfer instances (e-GYAFC) to show that current openly distributed instruction-tuned models (and, in some settings, ChatGPT) perform poorly on the task, and that fine-tuning on our high-quality dataset leads to significant improvements as shown by automatic evaluation. In human evaluation, we show that models much smaller than ChatGPT fine-tuned on our data align better with expert preferences. Finally, we discuss two potential applications of models fine-tuned on the explainable style transfer task: interpretable authorship verification and interpretable adversarial attacks on AI-generated text detectors.
I Spy a Metaphor: Large Language Models and Diffusion Models Co-Create Visual Metaphors
May 24, 2023



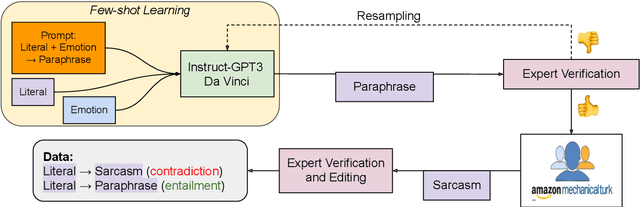
Visual metaphors are powerful rhetorical devices used to persuade or communicate creative ideas through images. Similar to linguistic metaphors, they convey meaning implicitly through symbolism and juxtaposition of the symbols. We propose a new task of generating visual metaphors from linguistic metaphors. This is a challenging task for diffusion-based text-to-image models, such as DALL$\cdot$E 2, since it requires the ability to model implicit meaning and compositionality. We propose to solve the task through the collaboration between Large Language Models (LLMs) and Diffusion Models: Instruct GPT-3 (davinci-002) with Chain-of-Thought prompting generates text that represents a visual elaboration of the linguistic metaphor containing the implicit meaning and relevant objects, which is then used as input to the diffusion-based text-to-image models.Using a human-AI collaboration framework, where humans interact both with the LLM and the top-performing diffusion model, we create a high-quality dataset containing 6,476 visual metaphors for 1,540 linguistic metaphors and their associated visual elaborations. Evaluation by professional illustrators shows the promise of LLM-Diffusion Model collaboration for this task.To evaluate the utility of our Human-AI collaboration framework and the quality of our dataset, we perform both an intrinsic human-based evaluation and an extrinsic evaluation using visual entailment as a downstream task.
Sociocultural Norm Similarities and Differences via Situational Alignment and Explainable Textual Entailment
May 23, 2023



Designing systems that can reason across cultures requires that they are grounded in the norms of the contexts in which they operate. However, current research on developing computational models of social norms has primarily focused on American society. Here, we propose a novel approach to discover and compare descriptive social norms across Chinese and American cultures. We demonstrate our approach by leveraging discussions on a Chinese Q&A platform-Zhihu-and the existing SocialChemistry dataset as proxies for contrasting cultural axes, align social situations cross-culturally, and extract social norms from texts using in-context learning. Embedding Chain-of-Thought prompting in a human-AI collaborative framework, we build a high-quality dataset of 3,069 social norms aligned with social situations across Chinese and American cultures alongside corresponding free-text explanations. To test the ability of models to reason about social norms across cultures, we introduce the task of explainable social norm entailment, showing that existing models under 3B parameters have significant room for improvement in both automatic and human evaluation. Further analysis of cross-cultural norm differences based on our dataset shows empirical alignment with the social orientations framework, revealing several situational and descriptive nuances in norms across these cultures.
FLUTE: Figurative Language Understanding and Textual Explanations
May 24, 2022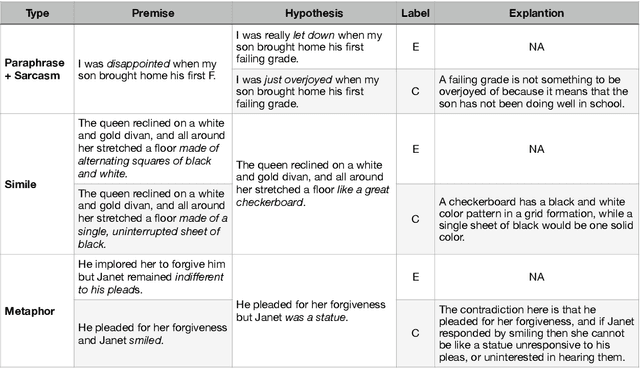
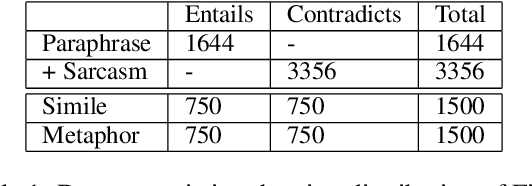

In spite of the prevalence of figurative language, transformer-based models struggle to demonstrate an understanding of it. Meanwhile, even classical natural language inference (NLI) tasks have been plagued by spurious correlations and annotation artifacts. Datasets like eSNLI have been released, allowing to probe whether language models are right for the right reasons. Yet no such data exists for figurative language, making it harder to asses genuine understanding of such expressions. In light of the above, we release FLUTE, a dataset of 8,000 figurative NLI instances with explanations, spanning three categories: Sarcasm, Simile, and Metaphor. We collect the data through the Human-AI collaboration framework based on GPT-3, crowdworkers, and expert annotation. We show how utilizing GPT-3 in conjunction with human experts can aid in scaling up the creation of datasets even for such complex linguistic phenomena as figurative language. Baseline performance of the T5 model shows our dataset is a challenging testbed for figurative language understanding.
Don't Go Far Off: An Empirical Study on Neural Poetry Translation
Sep 10, 2021

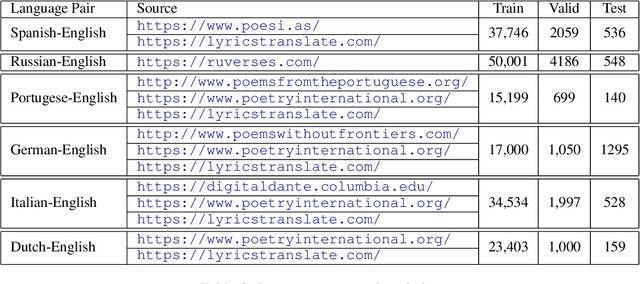

Despite constant improvements in machine translation quality, automatic poetry translation remains a challenging problem due to the lack of open-sourced parallel poetic corpora, and to the intrinsic complexities involved in preserving the semantics, style, and figurative nature of poetry. We present an empirical investigation for poetry translation along several dimensions: 1) size and style of training data (poetic vs. non-poetic), including a zero-shot setup; 2) bilingual vs. multilingual learning; and 3) language-family-specific models vs. mixed-multilingual models. To accomplish this, we contribute a parallel dataset of poetry translations for several language pairs. Our results show that multilingual fine-tuning on poetic text significantly outperforms multilingual fine-tuning on non-poetic text that is 35X larger in size, both in terms of automatic metrics (BLEU, BERTScore) and human evaluation metrics such as faithfulness (meaning and poetic style). Moreover, multilingual fine-tuning on poetic data outperforms \emph{bilingual} fine-tuning on poetic data.
COVID-Fact: Fact Extraction and Verification of Real-World Claims on COVID-19 Pandemic
Jun 07, 2021

We introduce a FEVER-like dataset COVID-Fact of $4,086$ claims concerning the COVID-19 pandemic. The dataset contains claims, evidence for the claims, and contradictory claims refuted by the evidence. Unlike previous approaches, we automatically detect true claims and their source articles and then generate counter-claims using automatic methods rather than employing human annotators. Along with our constructed resource, we formally present the task of identifying relevant evidence for the claims and verifying whether the evidence refutes or supports a given claim. In addition to scientific claims, our data contains simplified general claims from media sources, making it better suited for detecting general misinformation regarding COVID-19. Our experiments indicate that COVID-Fact will provide a challenging testbed for the development of new systems and our approach will reduce the costs of building domain-specific datasets for detecting misinformation.