 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAB: An LLM-Inspired Sequence-First Click-Through Rate Prediction Modeling Paradigm
Feb 03, 2026Traditional Deep Learning Recommendation Models (DLRMs) face increasing bottlenecks in performance and efficiency, often struggling with generalization and long-sequence modeling. Inspired by the scaling success of Large Language Models (LLMs), we propose Generative Ranking for Ads at Baidu (GRAB), an end-to-end generative framework for Click-Through Rate (CTR) prediction. GRAB integrates a novel Causal Action-aware Multi-channel Attention (CamA) mechanism to effectively capture temporal dynamics and specific action signals within user behavior sequences. Full-scale online deployment demonstrates that GRAB significantly outperforms established DLRMs, delivering a 3.05% increase in revenue and a 3.49% rise in CTR. Furthermore, the model demonstrates desirable scaling behavior: its expressive power shows a monotonic and approximately linear improvement as longer interaction sequences are utilized.
Adaptive Speaker Embedding Self-Augmentation for Personal Voice Activity Detection with Short Enrollment Speech
Jan 19, 2026Personal Voice Activity Detection (PVAD) is crucial for identifying target speaker segments in the mixture, yet its performance heavily depends on the quality of speaker embeddings. A key practical limitation is the short enrollment speech--such as a wake-up word--which provides limited cues. This paper proposes a novel adaptive speaker embedding self-augmentation strategy that enhances PVAD performance by augmenting the original enrollment embeddings through additive fusion of keyframe embeddings extracted from mixed speech. Furthermore, we introduce a long-term adaptation strategy to iteratively refine embeddings during detection, mitigating speaker temporal variability. Experiments show significant gains in recall, precision, and F1-score under short enrollment conditions, matching full-length enrollment performance after five iterative updates. The source code is available at https://anonymous.4open.science/r/ASE-PVAD-E5D6 .
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
FlowDrive: Energy Flow Field for End-to-End Autonomous Driving
Sep 17, 2025Recent advances in end-to-end autonomous driving leverage multi-view images to construct BEV representations for motion planning. In motion planning, autonomous vehicles need considering both hard constraints imposed by geometrically occupied obstacles (e.g., vehicles, pedestrians) and soft, rule-based semantics with no explicit geometry (e.g., lane boundaries, traffic priors). However, existing end-to-end frameworks typically rely on BEV features learned in an implicit manner, lacking explicit modeling of risk and guidance priors for safe and interpretable planning. To address this, we propose FlowDrive, a novel framework that introduces physically interpretable energy-based flow fields-including risk potential and lane attraction fields-to encode semantic priors and safety cues into the BEV space. These flow-aware features enable adaptive refinement of anchor trajectories and serve as interpretable guidance for trajectory generation. Moreover, FlowDrive decouples motion intent prediction from trajectory denoising via a conditional diffusion planner with feature-level gating, alleviating task interference and enhancing multimodal diversity. Experiments on the NAVSIM v2 benchmark demonstrate that FlowDrive achieves state-of-the-art performance with an EPDMS of 86.3, surpassing prior baselines in both safety and planning quality. The project is available at https://astrixdrive.github.io/FlowDrive.github.io/.
RewardDance: Reward Scaling in Visual Generation
Sep 10, 2025Reward Models (RMs) are critical for improving generation models via Reinforcement Learning (RL), yet the RM scaling paradigm in visual generation remains largely unexplored. It primarily due to fundamental limitations in existing approaches: CLIP-based RMs suffer from architectural and input modality constraints, while prevalent Bradley-Terry losses are fundamentally misaligned with the next-token prediction mechanism of Vision-Language Models (VLMs), hindering effective scaling. More critically, the RLHF optimization process is plagued by Reward Hacking issue, where models exploit flaws in the reward signal without improving true quality. To address these challenges, we introduce RewardDance, a scalable reward modeling framework that overcomes these barriers through a novel generative reward paradigm. By reformulating the reward score as the model's probability of predicting a "yes" token, indicating that the generated image outperforms a reference image according to specific criteria, RewardDance intrinsically aligns reward objectives with VLM architectures. This alignment unlocks scaling across two dimensions: (1) Model Scaling: Systematic scaling of RMs up to 26 billion parameters; (2) Context Scaling: Integration of task-specific instructions, reference examples, and chain-of-thought (CoT) reasoning. Extensive experiments demonstrate that RewardDance significantly surpasses state-of-the-art methods in text-to-image, text-to-video, and image-to-video generation. Crucially, we resolve the persistent challenge of "reward hacking": Our large-scale RMs exhibit and maintain high reward variance during RL fine-tuning, proving their resistance to hacking and ability to produce diverse, high-quality outputs. It greatly relieves the mode collapse problem that plagues smaller models.
MEAN-RIR: Multi-Modal Environment-Aware Network for Robust Room Impulse Response Estimation
Sep 05, 2025This paper presents a Multi-Modal Environment-Aware Network (MEAN-RIR), which uses an encoder-decoder framework to predict room impulse response (RIR) based on multi-level environmental information from audio, visual, and textual sources. Specifically, reverberant speech capturing room acoustic properties serves as the primary input, which is combined with panoramic images and text descriptions as supplementary inputs. Each input is processed by its respective encoder, and the outputs are fed into cross-attention modules to enable effective interaction between different modalities. The MEAN-RIR decoder generates two distinct components: the first component captures the direct sound and early reflections, while the second produces masks that modulate learnable filtered noise to synthesize the late reverberation. These two components are mixed to reconstruct the final RIR. The results show that MEAN-RIR significantly improves RIR estimation, with notable gains in acoustic parameters.
Automated 3D-GS Registration and Fusion via Skeleton Alignment and Gaussian-Adaptive Features
Jul 28, 2025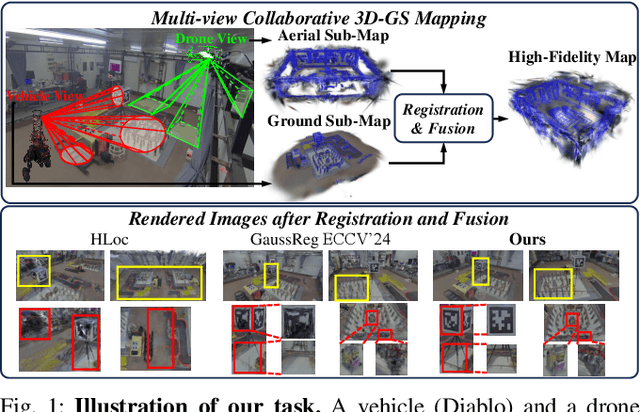
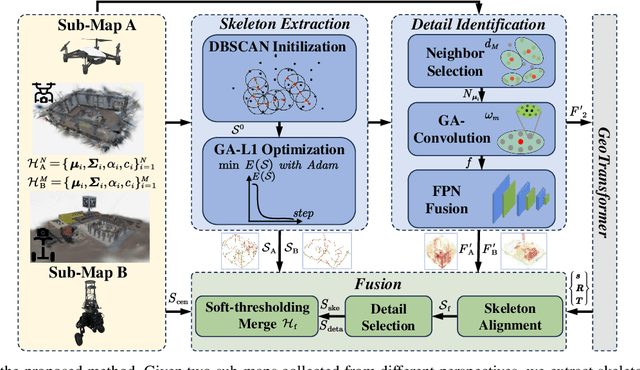
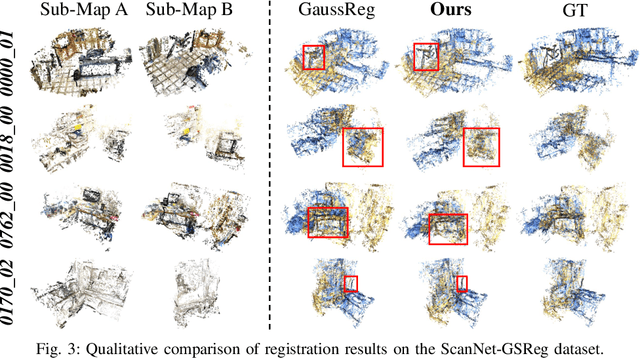
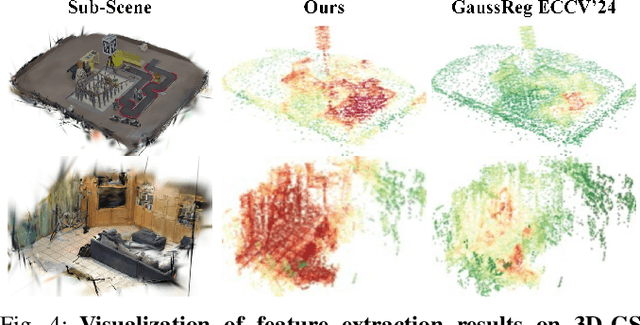
In recent years, 3D Gaussian Splatting (3D-GS)-based scene representation demonstrates significant potential in real-time rendering and training efficiency. However, most existing methods primarily focus on single-map reconstruction, while the registration and fusion of multiple 3D-GS sub-maps remain underexplored. Existing methods typically rely on manual intervention to select a reference sub-map as a template and use point cloud matching for registration. Moreover, hard-threshold filtering of 3D-GS primitives often degrades rendering quality after fusion. In this paper, we present a novel approach for automated 3D-GS sub-map alignment and fusion, eliminating the need for manual intervention while enhancing registration accuracy and fusion quality. First, we extract geometric skeletons across multiple scenes and leverage ellipsoid-aware convolution to capture 3D-GS attributes, facilitating robust scene registration. Second, we introduce a multi-factor Gaussian fusion strategy to mitigate the scene element loss caused by rigid thresholding. Experiments on the ScanNet-GSReg and our Coord datasets demonstrate the effectiveness of the proposed method in registration and fusion. For registration, it achieves a 41.9\% reduction in RRE on complex scenes, ensuring more precise pose estimation. For fusion, it improves PSNR by 10.11 dB, highlighting superior structural preservation. These results confirm its ability to enhance scene alignment and reconstruction fidelity, ensuring more consistent and accurate 3D scene representation for robotic perception and autonomous navigation.
End-to-End DOA-Guided Speech Extraction in Noisy Multi-Talker Scenarios
Jul 28, 2025Target Speaker Extraction (TSE) plays a critical role in enhancing speech signals in noisy and multi-speaker environments. This paper presents an end-to-end TSE model that incorporates Direction of Arrival (DOA) and beamwidth embeddings to extract speech from a specified spatial region centered around the DOA. Our approach efficiently captures spatial and temporal features, enabling robust performance in highly complex scenarios with multiple simultaneous speakers. Experimental results demonstrate that the proposed model not only significantly enhances the target speech within the defined beamwidth but also effectively suppresses interference from other directions, producing a clear and isolated target voice. Furthermore, the model achieves remarkable improvements in downstream Automatic Speech Recognition (ASR) tasks, making it particularly suitable for real-world applications.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025



Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.