 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMPO: Hybrid Median-length Policy Optimization for Chain-of-Thought Compression
Jun 01, 2026Large language models achieve remarkable performance via extended chain-of-thought (CoT) reasoning, yet this lengthy process incurs substantial inference overhead. Existing CoT compression methods struggle with inflexible manual length budgets, computationally expensive multi-stage training pipelines, and fragile scalability restricted to small models. We propose HMPO (Hybrid Median-length Policy Optimization), a cost-effective, single-stage reinforcement learning framework. HMPO efficiently compresses CoT via three synergistic components: an adaptive median-based budget derived from successful rollouts to eliminate manual tuning, a cosine-decay token reward for smooth length penalization, and a multiplicative reward formulation that substantially mitigates trivial reward hacking by strictly prioritizing answer correctness. Trained exclusively on mathematical data, HMPO generalizes seamlessly across math, code, science, and instruction-following tasks. Extensive experiments scaling from 9B to 122B parameters across dense and Mixture-of-Experts (MoE) architectures demonstrate that HMPO achieves 19%--46% token compression with negligible accuracy degradation, all while drastically reducing training costs compared to existing multi-stage baselines.
GRAB: An LLM-Inspired Sequence-First Click-Through Rate Prediction Modeling Paradigm
Feb 03, 2026Traditional Deep Learning Recommendation Models (DLRMs) face increasing bottlenecks in performance and efficiency, often struggling with generalization and long-sequence modeling. Inspired by the scaling success of Large Language Models (LLMs), we propose Generative Ranking for Ads at Baidu (GRAB), an end-to-end generative framework for Click-Through Rate (CTR) prediction. GRAB integrates a novel Causal Action-aware Multi-channel Attention (CamA) mechanism to effectively capture temporal dynamics and specific action signals within user behavior sequences. Full-scale online deployment demonstrates that GRAB significantly outperforms established DLRMs, delivering a 3.05% increase in revenue and a 3.49% rise in CTR. Furthermore, the model demonstrates desirable scaling behavior: its expressive power shows a monotonic and approximately linear improvement as longer interaction sequences are utilized.
RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation
Jan 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has driven substantial progress in reasoning-intensive domains like mathematics. However, optimizing open-ended generation remains challenging due to the lack of ground truth. While rubric-based evaluation offers a structured proxy for verification, existing methods suffer from scalability bottlenecks and coarse criteria, resulting in a supervision ceiling effect. To address this, we propose an automated Coarse-to-Fine Rubric Generation framework. By synergizing principle-guided synthesis, multi-model aggregation, and difficulty evolution, our approach produces comprehensive and highly discriminative criteria capable of capturing the subtle nuances. Based on this framework, we introduce RubricHub, a large-scale ($\sim$110k) and multi-domain dataset. We validate its utility through a two-stage post-training pipeline comprising Rubric-based Rejection Sampling Fine-Tuning (RuFT) and Reinforcement Learning (RuRL). Experimental results demonstrate that RubricHub unlocks significant performance gains: our post-trained Qwen3-14B achieves state-of-the-art (SOTA) results on HealthBench (69.3), surpassing proprietary frontier models such as GPT-5. The code and data will be released soon.
POI Alias Discovery in Delivery Addresses using User Locations
Sep 20, 2021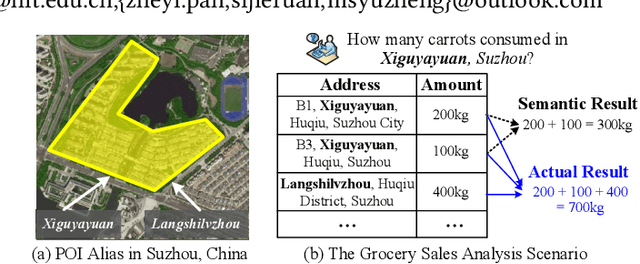
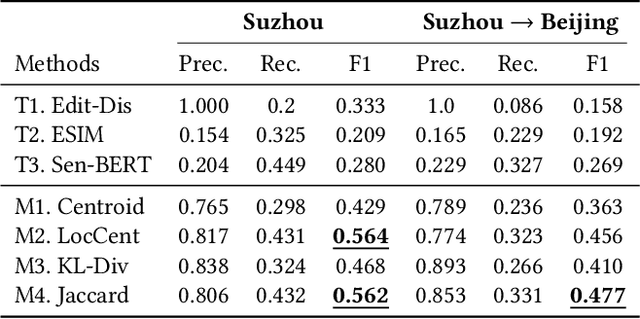
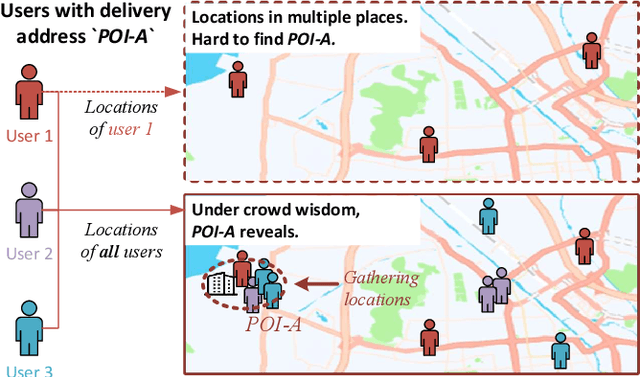
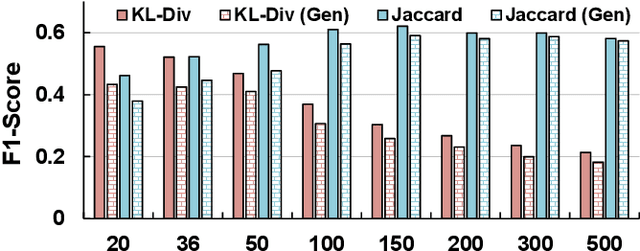
People often refer to a place of interest (POI) by an alias. In e-commerce scenarios, the POI alias problem affects the quality of the delivery address of online orders, bringing substantial challenges to intelligent logistics systems and market decision-making. Labeling the aliases of POIs involves heavy human labor, which is inefficient and expensive. Inspired by the observation that the users' GPS locations are highly related to their delivery address, we propose a ubiquitous alias discovery framework. Firstly, for each POI name in delivery addresses, the location data of its associated users, namely Mobility Profile are extracted. Then, we identify the alias relationship by modeling the similarity of mobility profiles. Comprehensive experiments on the large-scale location data and delivery address data from JD logistics validate the effectiveness.
Effective Cascade Dual-Decoder Model for Joint Entity and Relation Extraction
Jun 27, 2021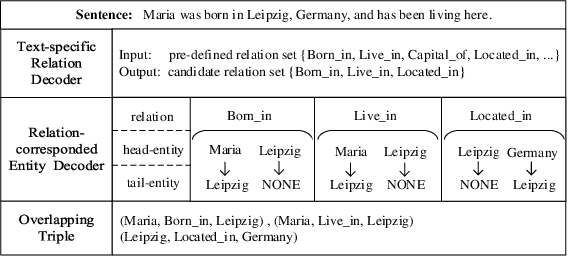
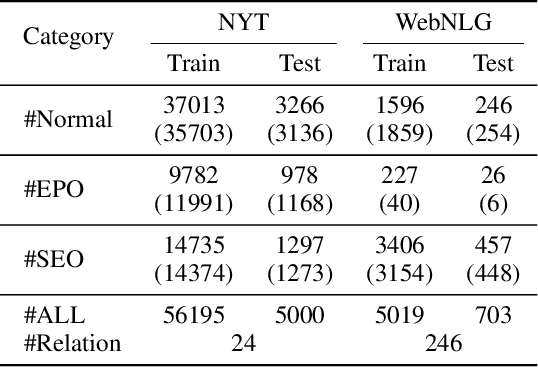
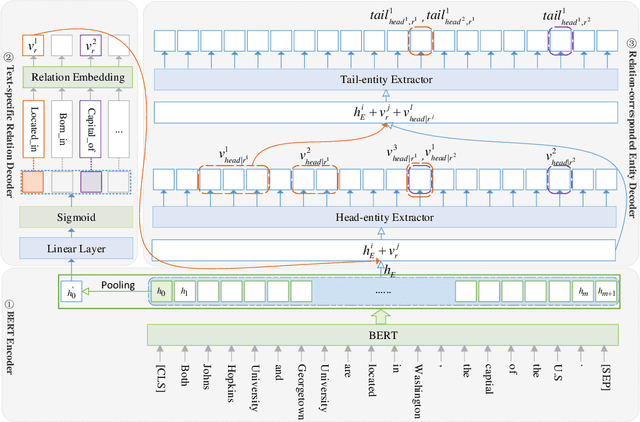
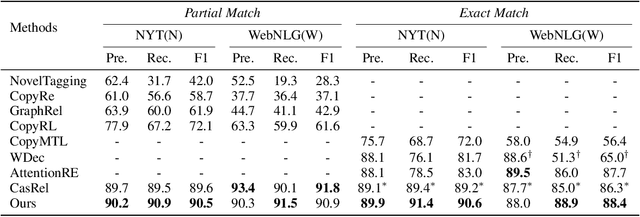
Extracting relational triples from texts is a fundamental task in knowledge graph construction. The popular way of existing methods is to jointly extract entities and relations using a single model, which often suffers from the overlapping triple problem. That is, there are multiple relational triples that share the same entities within one sentence. In this work, we propose an effective cascade dual-decoder approach to extract overlapping relational triples, which includes a text-specific relation decoder and a relation-corresponded entity decoder. Our approach is straightforward: the text-specific relation decoder detects relations from a sentence according to its text semantics and treats them as extra features to guide the entity extraction; for each extracted relation, which is with trainable embedding, the relation-corresponded entity decoder detects the corresponding head and tail entities using a span-based tagging scheme. In this way, the overlapping triple problem is tackled naturally. Experiments on two public datasets demonstrate that our proposed approach outperforms state-of-the-art methods and achieves better F1 scores under the strict evaluation metric. Our implementation is available at https://github.com/prastunlp/DualDec.