 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchKM: A GPU-Oriented Library for Kernel Learning and Model Selection
Jun 04, 2026TorchKM is an open-source library for kernel machines, including support vector machines, kernel logistic regression, and kernel quantile regression, with GPU acceleration. The library features a scikit-learn-style API and is designed to exploit GPU-friendly linear algebra, accelerating the full training and model-selection pipeline through intelligent reuse of matrix operations. Benchmarks show competitive predictive performance together with substantial speedups over standard baselines. Code and documentation are available at https://github.com/YikaiZhang95/torchkm, and the package can be easily installed via PyPI.
Accurate Large-sample Uncertainty Quantification using Stochastic Gradient Markov Chain Monte Carlo
May 29, 2026Tuning algorithms such as stochastic gradient descent (SGD) and stochastic gradient Langevin dynamics (SGLD) for approximate sampling and uncertainty quantification remains challenging, particularly in the practically relevant settings when the batch size is large or the model is misspecified. Existing theory that provides tuning guidance relies on continuous-time limits or strong statistical assumptions, which can become quantitatively inaccurate in these regimes. We address these shortcomings by proposing new discrete-time approximations to SG(L)D with and without momentum, which enables accurate predictions of the stationary covariance, iterate average covariance, and integrated autocorrelation time. Moreover, we prove quantitative, non-asymptotic error bounds showing that these estimates are sufficiently accurate for practical tuning and uncertainty quantification. Numerical experiments demonstrate that our theory yields improved tuning guidance across a range of models and data-generating distributions where existing approaches fail, including when using the $β$-divergence rather than log-loss to obtain statistically robust inferences.
EvoNash-MARL: A Closed-Loop Multi-Agent Reinforcement Learning Framework for Medium-Horizon Equity Allocation
Apr 14, 2026Medium- to long-horizon equity allocation is challenging due to weak predictive structure, non-stationary market regimes, and the degradation of signals under realistic trading constraints. Conventional approaches often rely on single predictors or loosely coupled pipelines, which limit robustness under distributional shift. This paper proposes EvoNash-MARL, a closed-loop framework that integrates reinforcement learning with population-based policy optimization and execution-aware selection to improve robustness in medium- to long-horizon allocation. The framework combines multi-agent policy populations, game-theoretic aggregation, and constraint-aware validation within a unified walk-forward design. Under a 120-window walk-forward protocol, the final configuration achieves the highest robust score among internal baselines. On out-of-sample data from 2014 to 2024, it delivers a 19.6% annualized return, compared to 11.7% for SPY, and remains stable under extended evaluation through 2026. While the framework demonstrates consistent performance under realistic constraints and across market settings, strong global statistical significance is not established under White's Reality Check (WRC) and SPA-lite tests. The results therefore provide evidence of improved robustness rather than definitive proof of superior market timing performance.
ADD for Multi-Bit Image Watermarking
Apr 13, 2026As generative models enable rapid creation of high-fidelity images, societal concerns about misinformation and authenticity have intensified. A promising remedy is multi-bit image watermarking, which embeds a multi-bit message into an image so that a verifier can later detect whether the image is generated by someone and further identify the source by decoding the embedded message. Existing approaches often fall short in capacity, resilience to common image distortions, and theoretical justification. To address these limitations, we propose ADD (Add, Dot, Decode), a multi-bit image watermarking method with two stages: learning a watermark to be linearly combined with the multi-bit message and added to the image, and decoding through inner products between the watermarked image and the learned watermark. On the standard MS-COCO benchmark, we demonstrate that for the challenging task of 48-bit watermarking, ADD achieves 100\% decoding accuracy, with performance dropping by at most 2\% under a wide range of image distortions, substantially smaller than the 14\% average drop of state-of-the-art methods. In addition, ADD achieves substantial computational gains, with 2-fold faster embedding and 7.4-fold faster decoding than the fastest existing method. We further provide a theoretical analysis explaining why the learned watermark and the corresponding decoding rule are effective.
AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
Mar 19, 2026Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) and artificial intelligence (AI) agents have significantly automated data science workflow. However, it remains unclear to what extent AI agents can match the performance of human experts on domain-specific data science tasks, and in which aspects human expertise continues to provide advantages. We introduce AgentDS, a benchmark and competition designed to evaluate both AI agents and human-AI collaboration performance in domain-specific data science. AgentDS consists of 17 challenges across six industries: commerce, food production, healthcare, insurance, manufacturing, and retail banking. We conducted an open competition involving 29 teams and 80 participants, enabling systematic comparison between human-AI collaborative approaches and AI-only baselines. Our results show that current AI agents struggle with domain-specific reasoning. AI-only baselines perform near or below the median of competition participants, while the strongest solutions arise from human-AI collaboration. These findings challenge the narrative of complete automation by AI and underscore the enduring importance of human expertise in data science, while illuminating directions for the next generation of AI. Visit the AgentDS website here: https://agentds.org/ and open source datasets here: https://huggingface.co/datasets/lainmn/AgentDS .
Scalable Dexterous Robot Learning with AR-based Remote Human-Robot Interactions
Feb 07, 2026This paper focuses on the scalable robot learning for manipulation in the dexterous robot arm-hand systems, where the remote human-robot interactions via augmented reality (AR) are established to collect the expert demonstration data for improving efficiency. In such a system, we present a unified framework to address the general manipulation task problem. Specifically, the proposed method consists of two phases: i) In the first phase for pretraining, the policy is created in a behavior cloning (BC) manner, through leveraging the learning data from our AR-based remote human-robot interaction system; ii) In the second phase, a contrastive learning empowered reinforcement learning (RL) method is developed to obtain more efficient and robust policy than the BC, and thus a projection head is designed to accelerate the learning progress. An event-driven augmented reward is adopted for enhancing the safety. To validate the proposed method, both the physics simulations via PyBullet and real-world experiments are carried out. The results demonstrate that compared to the classic proximal policy optimization and soft actor-critic policies, our method not only significantly speeds up the inference, but also achieves much better performance in terms of the success rate for fulfilling the manipulation tasks. By conducting the ablation study, it is confirmed that the proposed RL with contrastive learning overcomes policy collapse. Supplementary demonstrations are available at https://cyberyyc.github.io/.
GRAB: An LLM-Inspired Sequence-First Click-Through Rate Prediction Modeling Paradigm
Feb 03, 2026Traditional Deep Learning Recommendation Models (DLRMs) face increasing bottlenecks in performance and efficiency, often struggling with generalization and long-sequence modeling. Inspired by the scaling success of Large Language Models (LLMs), we propose Generative Ranking for Ads at Baidu (GRAB), an end-to-end generative framework for Click-Through Rate (CTR) prediction. GRAB integrates a novel Causal Action-aware Multi-channel Attention (CamA) mechanism to effectively capture temporal dynamics and specific action signals within user behavior sequences. Full-scale online deployment demonstrates that GRAB significantly outperforms established DLRMs, delivering a 3.05% increase in revenue and a 3.49% rise in CTR. Furthermore, the model demonstrates desirable scaling behavior: its expressive power shows a monotonic and approximately linear improvement as longer interaction sequences are utilized.
TopoDIM: One-shot Topology Generation of Diverse Interaction Modes for Multi-Agent Systems
Jan 15, 2026Optimizing communication topology in LLM-based multi-agent system is critical for enabling collective intelligence. Existing methods mainly rely on spatio-temporal interaction paradigms, where the sequential execution of multi-round dialogues incurs high latency and computation. Motivated by the recent insights that evaluation and debate mechanisms can improve problem-solving in multi-agent systems, we propose TopoDIM, a framework for one-shot Topology generation with Diverse Interaction Modes. Designed for decentralized execution to enhance adaptability and privacy, TopoDIM enables agents to autonomously construct heterogeneous communication without iterative coordination, achieving token efficiency and improved task performance. Experiments demonstrate that TopoDIM reduces total token consumption by 46.41% while improving average performance by 1.50% over state-of-the-art methods. Moreover, the framework exhibits strong adaptability in organizing communication among heterogeneous agents. Code is available at: https://anonymous.4open.science/r/TopoDIM-8D35/
Can Agentic AI Match the Performance of Human Data Scientists?
Dec 24, 2025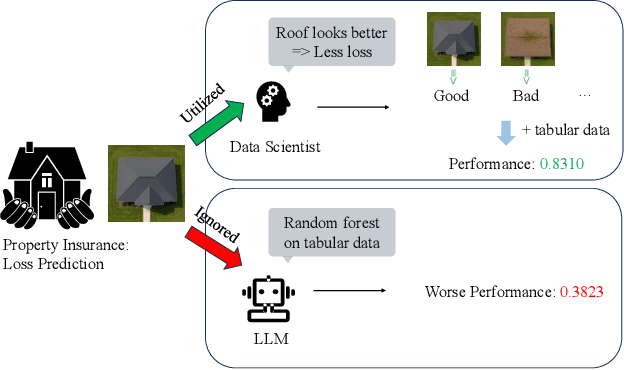

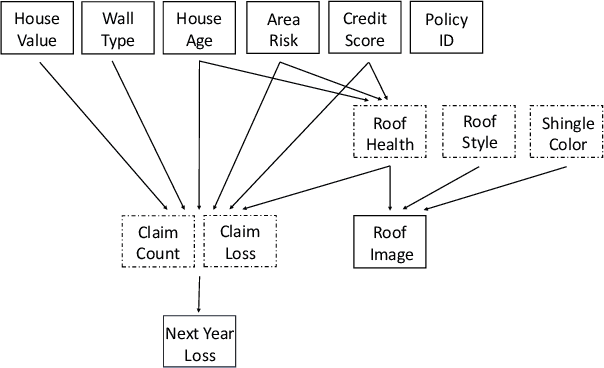

Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) have significantly automated data science workflows, but a fundamental question persists: Can these agentic AI systems truly match the performance of human data scientists who routinely leverage domain-specific knowledge? We explore this question by designing a prediction task where a crucial latent variable is hidden in relevant image data instead of tabular features. As a result, agentic AI that generates generic codes for modeling tabular data cannot perform well, while human experts could identify the important hidden variable using domain knowledge. We demonstrate this idea with a synthetic dataset for property insurance. Our experiments show that agentic AI that relies on generic analytics workflow falls short of methods that use domain-specific insights. This highlights a key limitation of the current agentic AI for data science and underscores the need for future research to develop agentic AI systems that can better recognize and incorporate domain knowledge.
An Outlook on the Opportunities and Challenges of Multi-Agent AI Systems
May 23, 2025Multi-agent AI systems (MAS) offer a promising framework for distributed intelligence, enabling collaborative reasoning, planning, and decision-making across autonomous agents. This paper provides a systematic outlook on the current opportunities and challenges of MAS, drawing insights from recent advances in large language models (LLMs), federated optimization, and human-AI interaction. We formalize key concepts including agent topology, coordination protocols, and shared objectives, and identify major risks such as dependency, misalignment, and vulnerabilities arising from training data overlap. Through a biologically inspired simulation and comprehensive theoretical framing, we highlight critical pathways for developing robust, scalable, and secure MAS in real-world settings.