 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirection Informed Trees (DIT*): Optimal Path Planning via Direction Filter and Direction Cost Heuristic
Aug 26, 2025Optimal path planning requires finding a series of feasible states from the starting point to the goal to optimize objectives. Popular path planning algorithms, such as Effort Informed Trees (EIT*), employ effort heuristics to guide the search. Effective heuristics are accurate and computationally efficient, but achieving both can be challenging due to their conflicting nature. This paper proposes Direction Informed Trees (DIT*), a sampling-based planner that focuses on optimizing the search direction for each edge, resulting in goal bias during exploration. We define edges as generalized vectors and integrate similarity indexes to establish a directional filter that selects the nearest neighbors and estimates direction costs. The estimated direction cost heuristics are utilized in edge evaluation. This strategy allows the exploration to share directional information efficiently. DIT* convergence faster than existing single-query, sampling-based planners on tested problems in R^4 to R^16 and has been demonstrated in real-world environments with various planning tasks. A video showcasing our experimental results is available at: https://youtu.be/2SX6QT2NOek
Alternating Training-based Label Smoothing Enhances Prompt Generalization
Aug 25, 2025



Recent advances in pre-trained vision-language models have demonstrated remarkable zero-shot generalization capabilities. To further enhance these models' adaptability to various downstream tasks, prompt tuning has emerged as a parameter-efficient fine-tuning method. However, despite its efficiency, the generalization ability of prompt remains limited. In contrast, label smoothing (LS) has been widely recognized as an effective regularization technique that prevents models from becoming over-confident and improves their generalization. This inspires us to explore the integration of LS with prompt tuning. However, we have observed that the vanilla LS even weakens the generalization ability of prompt tuning. To address this issue, we propose the Alternating Training-based Label Smoothing (ATLaS) method, which alternately trains with standard one-hot labels and soft labels generated by LS to supervise the prompt tuning. Moreover, we introduce two types of efficient offline soft labels, including Class-wise Soft Labels (CSL) and Instance-wise Soft Labels (ISL), to provide inter-class or instance-class relationships for prompt tuning. The theoretical properties of the proposed ATLaS method are analyzed. Extensive experiments demonstrate that the proposed ATLaS method, combined with CSL and ISL, consistently enhances the generalization performance of prompt tuning. Moreover, the proposed ATLaS method exhibits high compatibility with prevalent prompt tuning methods, enabling seamless integration into existing methods.
Generalizable Engagement Estimation in Conversation via Domain Prompting and Parallel Attention
Aug 20, 2025



Accurate engagement estimation is essential for adaptive human-computer interaction systems, yet robust deployment is hindered by poor generalizability across diverse domains and challenges in modeling complex interaction dynamics.To tackle these issues, we propose DAPA (Domain-Adaptive Parallel Attention), a novel framework for generalizable conversational engagement modeling. DAPA introduces a Domain Prompting mechanism by prepending learnable domain-specific vectors to the input, explicitly conditioning the model on the data's origin to facilitate domain-aware adaptation while preserving generalizable engagement representations. To capture interactional synchrony, the framework also incorporates a Parallel Cross-Attention module that explicitly aligns reactive (forward BiLSTM) and anticipatory (backward BiLSTM) states between participants.Extensive experiments demonstrate that DAPA establishes a new state-of-the-art performance on several cross-cultural and cross-linguistic benchmarks, notably achieving an absolute improvement of 0.45 in Concordance Correlation Coefficient (CCC) over a strong baseline on the NoXi-J test set. The superiority of our method was also confirmed by winning the first place in the Multi-Domain Engagement Estimation Challenge at MultiMediate'25.
DGenCTR: Towards a Universal Generative Paradigm for Click-Through Rate Prediction via Discrete Diffusion
Aug 20, 2025



Recent advances in generative models have inspired the field of recommender systems to explore generative approaches, but most existing research focuses on sequence generation, a paradigm ill-suited for click-through rate (CTR) prediction. CTR models critically depend on a large number of cross-features between the target item and the user to estimate the probability of clicking on the item, and discarding these cross-features will significantly impair model performance. Therefore, to harness the ability of generative models to understand data distributions and thereby alleviate the constraints of traditional discriminative models in label-scarce space, diverging from the item-generation paradigm of sequence generation methods, we propose a novel sample-level generation paradigm specifically designed for the CTR task: a two-stage Discrete Diffusion-Based Generative CTR training framework (DGenCTR). This two-stage framework comprises a diffusion-based generative pre-training stage and a CTR-targeted supervised fine-tuning stage for CTR. Finally, extensive offline experiments and online A/B testing conclusively validate the effectiveness of our framework.
Global-Distribution Aware Scenario-Specific Variational Representation Learning Framework
Aug 20, 2025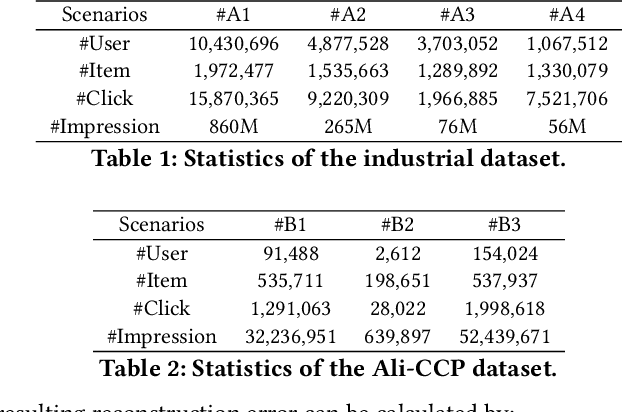
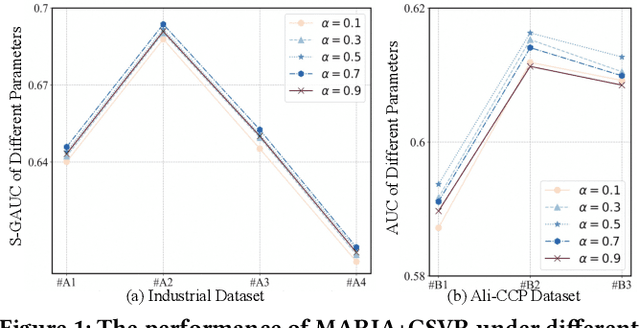
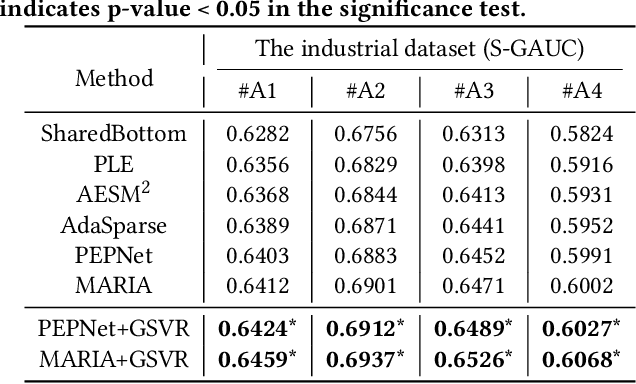
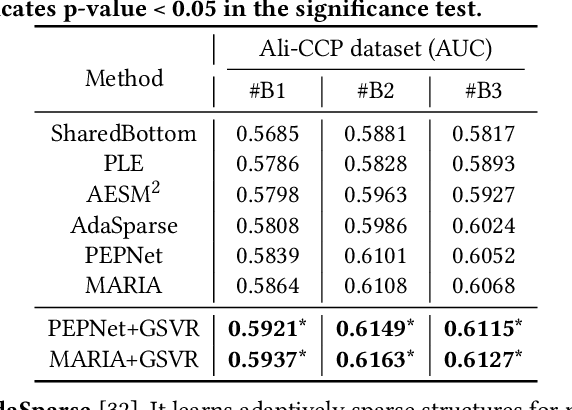
With the emergence of e-commerce, the recommendations provided by commercial platforms must adapt to diverse scenarios to accommodate users' varying shopping preferences. Current methods typically use a unified framework to offer personalized recommendations for different scenarios. However, they often employ shared bottom representations, which partially hinders the model's capacity to capture scenario uniqueness. Ideally, users and items should exhibit specific characteristics in different scenarios, prompting the need to learn scenario-specific representations to differentiate scenarios. Yet, variations in user and item interactions across scenarios lead to data sparsity issues, impeding the acquisition of scenario-specific representations. To learn robust scenario-specific representations, we introduce a Global-Distribution Aware Scenario-Specific Variational Representation Learning Framework (GSVR) that can be directly applied to existing multi-scenario methods. Specifically, considering the uncertainty stemming from limited samples, our approach employs a probabilistic model to generate scenario-specific distributions for each user and item in each scenario, estimated through variational inference (VI). Additionally, we introduce the global knowledge-aware multinomial distributions as prior knowledge to regulate the learning of the posterior user and item distributions, ensuring similarities among distributions for users with akin interests and items with similar side information. This mitigates the risk of users or items with fewer records being overwhelmed in sparse scenarios. Extensive experimental results affirm the efficacy of GSVR in assisting existing multi-scenario recommendation methods in learning more robust representations.
Distribution-Guided Auto-Encoder for User Multimodal Interest Cross Fusion
Aug 20, 2025Traditional recommendation methods rely on correlating the embedding vectors of item IDs to capture implicit collaborative filtering signals to model the user's interest in the target item. Consequently, traditional ID-based methods often encounter data sparsity problems stemming from the sparse nature of ID features. To alleviate the problem of item ID sparsity, recommendation models incorporate multimodal item information to enhance recommendation accuracy. However, existing multimodal recommendation methods typically employ early fusion approaches, which focus primarily on combining text and image features, while neglecting the contextual influence of user behavior sequences. This oversight prevents dynamic adaptation of multimodal interest representations based on behavioral patterns, consequently restricting the model's capacity to effectively capture user multimodal interests. Therefore, this paper proposes the Distribution-Guided Multimodal-Interest Auto-Encoder (DMAE), which achieves the cross fusion of user multimodal interest at the behavioral level.Ultimately, extensive experiments demonstrate the superiority of DMAE.
AgriGPT: a Large Language Model Ecosystem for Agriculture
Aug 12, 2025



Despite the rapid progress of Large Language Models (LLMs), their application in agriculture remains limited due to the lack of domain-specific models, curated datasets, and robust evaluation frameworks. To address these challenges, we propose AgriGPT, a domain-specialized LLM ecosystem for agricultural usage. At its core, we design a multi-agent scalable data engine that systematically compiles credible data sources into Agri-342K, a high-quality, standardized question-answer (QA) dataset. Trained on this dataset, AgriGPT supports a broad range of agricultural stakeholders, from practitioners to policy-makers. To enhance factual grounding, we employ Tri-RAG, a three-channel Retrieval-Augmented Generation framework combining dense retrieval, sparse retrieval, and multi-hop knowledge graph reasoning, thereby improving the LLM's reasoning reliability. For comprehensive evaluation, we introduce AgriBench-13K, a benchmark suite comprising 13 tasks with varying types and complexities. Experiments demonstrate that AgriGPT significantly outperforms general-purpose LLMs on both domain adaptation and reasoning. Beyond the model itself, AgriGPT represents a modular and extensible LLM ecosystem for agriculture, comprising structured data construction, retrieval-enhanced generation, and domain-specific evaluation. This work provides a generalizable framework for developing scientific and industry-specialized LLMs. All models, datasets, and code will be released to empower agricultural communities, especially in underserved regions, and to promote open, impactful research.
Think as Cardiac Sonographers: Marrying SAM with Left Ventricular Indicators Measurements According to Clinical Guidelines
Aug 12, 2025Left ventricular (LV) indicator measurements following clinical echocardiog-raphy guidelines are important for diagnosing cardiovascular disease. Alt-hough existing algorithms have explored automated LV quantification, they can struggle to capture generic visual representations due to the normally small training datasets. Therefore, it is necessary to introduce vision founda-tional models (VFM) with abundant knowledge. However, VFMs represented by the segment anything model (SAM) are usually suitable for segmentation but incapable of identifying key anatomical points, which are critical in LV indicator measurements. In this paper, we propose a novel framework named AutoSAME, combining the powerful visual understanding of SAM with seg-mentation and landmark localization tasks simultaneously. Consequently, the framework mimics the operation of cardiac sonographers, achieving LV indi-cator measurements consistent with clinical guidelines. We further present fil-tered cross-branch attention (FCBA) in AutoSAME, which leverages relatively comprehensive features in the segmentation to enhance the heatmap regression (HR) of key points from the frequency domain perspective, optimizing the vis-ual representation learned by the latter. Moreover, we propose spatial-guided prompt alignment (SGPA) to automatically generate prompt embeddings guid-ed by spatial properties of LV, thereby improving the accuracy of dense pre-dictions by prior spatial knowledge. The extensive experiments on an echocar-diography dataset demonstrate the efficiency of each design and the superiori-ty of our AutoSAME in LV segmentation, landmark localization, and indicator measurements. The code will be available at https://github.com/QC-LIU-1997/AutoSAME.
\(X\)-evolve: Solution space evolution powered by large language models
Aug 11, 2025



While combining large language models (LLMs) with evolutionary algorithms (EAs) shows promise for solving complex optimization problems, current approaches typically evolve individual solutions, often incurring high LLM call costs. We introduce \(X\)-evolve, a paradigm-shifting method that instead evolves solution spaces \(X\) (sets of individual solutions) - subsets of the overall search space \(S\). In \(X\)-evolve, LLMs generate tunable programs wherein certain code snippets, designated as parameters, define a tunable solution space. A score-based search algorithm then efficiently explores this parametrically defined space, guided by feedback from objective function scores. This strategy enables broader and more efficient exploration, which can potentially accelerate convergence at a much lower search cost, requiring up to two orders of magnitude fewer LLM calls than prior leading methods. We demonstrate \(X\)-evolve's efficacy across three distinct hard optimization problems. For the cap set problem, we discover a larger partial admissible set, establishing a new tighter asymptotic lower bound for the cap set constant (\(C \ge 2.2203\)). In information theory, we uncover a larger independent set for the 15-vertex cycle graph (\(\mathcal{C}_{15}^{\boxtimes 5}\), size 19,946), thereby raising the known lower bound on its Shannon capacity. Furthermore, for the NP-hard online bin packing problem, we generate heuristics that consistently outperform standard strategies across established benchmarks. By evolving solution spaces, our method considerably improves search effectiveness, making it possible to tackle high-dimensional problems that were previously computationally prohibitive.
Harnessing Adaptive Topology Representations for Zero-Shot Graph Question Answering
Aug 08, 2025



Large Multimodal Models (LMMs) have shown generalized zero-shot capabilities in diverse domain question-answering (QA) tasks, including graph QA that involves complex graph topologies. However, most current approaches use only a single type of graph representation, namely Topology Representation Form (TRF), such as prompt-unified text descriptions or style-fixed visual styles. Those "one-size-fits-all" approaches fail to consider the specific preferences of different models or tasks, often leading to incorrect or overly long responses. To address this, we first analyze the characteristics and weaknesses of existing TRFs, and then design a set of TRFs, denoted by $F_{ZS}$, tailored to zero-shot graph QA. We then introduce a new metric, Graph Response Efficiency (GRE), which measures the balance between the performance and the brevity in graph QA. Built on these, we develop the DynamicTRF framework, which aims to improve both the accuracy and conciseness of graph QA. To be specific, DynamicTRF first creates a TRF Preference (TRFP) dataset that ranks TRFs based on their GRE scores, to probe the question-specific TRF preferences. Then it trains a TRF router on the TRFP dataset, to adaptively assign the best TRF from $F_{ZS}$ for each question during the inference. Extensive experiments across 7 in-domain algorithmic graph QA tasks and 2 out-of-domain downstream tasks show that DynamicTRF significantly enhances the zero-shot graph QA of LMMs in terms of accuracy