 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision Synthesis of Multi-Tracer PET via VLM-Modulated Rectified Flow for Stratifying Mild Cognitive Impairment
Apr 13, 2026The biological definition of Alzheimer's disease (AD) relies on multi-modal neuroimaging, yet the clinical utility of positron emission tomography (PET) is limited by cost and radiation exposure, hindering early screening at preclinical or prodromal stages. While generative models offer a promising alternative by synthesizing PET from magnetic resonance imaging (MRI), achieving subject-specific precision remains a primary challenge. Here, we introduce DIReCT$++$, a Domain-Informed ReCTified flow model for synthesizing multi-tracer PET from MRI combined with fundamental clinical information. Our approach integrates a 3D rectified flow architecture to capture complex cross-modal and cross-tracer relationships with a domain-adapted vision-language model (BiomedCLIP) that provides text-guided, personalized generation using clinical scores and imaging knowledge. Extensive evaluations on multi-center datasets demonstrate that DIReCT$++$ not only produces synthetic PET images ($^{18}$F-AV-45 and $^{18}$F-FDG) of superior fidelity and generalizability but also accurately recapitulates disease-specific patterns. Crucially, combining these synthesized PET images with MRI enables precise personalized stratification of mild cognitive impairment (MCI), advancing a scalable, data-efficient tool for the early diagnosis and prognostic prediction of AD. The source code will be released on https://github.com/ladderlab-xjtu/DIReCT-PLUS.
Online Conformal Prediction via Universal Portfolio Algorithms
Feb 03, 2026Online conformal prediction (OCP) seeks prediction intervals that achieve long-run $1-α$ coverage for arbitrary (possibly adversarial) data streams, while remaining as informative as possible. Existing OCP methods often require manual learning-rate tuning to work well, and may also require algorithm-specific analyses. Here, we develop a general regret-to-coverage theory for interval-valued OCP based on the $(1-α)$-pinball loss. Our first contribution is to identify \emph{linearized regret} as a key notion, showing that controlling it implies coverage bounds for any online algorithm. This relies on a black-box reduction that depends only on the Fenchel conjugate of an upper bound on the linearized regret. Building on this theory, we propose UP-OCP, a parameter-free method for OCP, via a reduction to a two-asset portfolio selection problem, leveraging universal portfolio algorithms. We show strong finite-time bounds on the miscoverage of UP-OCP, even for polynomially growing predictions. Extensive experiments support that UP-OCP delivers consistently better size/coverage trade-offs than prior online conformal baselines.
Think as Cardiac Sonographers: Marrying SAM with Left Ventricular Indicators Measurements According to Clinical Guidelines
Aug 12, 2025Left ventricular (LV) indicator measurements following clinical echocardiog-raphy guidelines are important for diagnosing cardiovascular disease. Alt-hough existing algorithms have explored automated LV quantification, they can struggle to capture generic visual representations due to the normally small training datasets. Therefore, it is necessary to introduce vision founda-tional models (VFM) with abundant knowledge. However, VFMs represented by the segment anything model (SAM) are usually suitable for segmentation but incapable of identifying key anatomical points, which are critical in LV indicator measurements. In this paper, we propose a novel framework named AutoSAME, combining the powerful visual understanding of SAM with seg-mentation and landmark localization tasks simultaneously. Consequently, the framework mimics the operation of cardiac sonographers, achieving LV indi-cator measurements consistent with clinical guidelines. We further present fil-tered cross-branch attention (FCBA) in AutoSAME, which leverages relatively comprehensive features in the segmentation to enhance the heatmap regression (HR) of key points from the frequency domain perspective, optimizing the vis-ual representation learned by the latter. Moreover, we propose spatial-guided prompt alignment (SGPA) to automatically generate prompt embeddings guid-ed by spatial properties of LV, thereby improving the accuracy of dense pre-dictions by prior spatial knowledge. The extensive experiments on an echocar-diography dataset demonstrate the efficiency of each design and the superiori-ty of our AutoSAME in LV segmentation, landmark localization, and indicator measurements. The code will be available at https://github.com/QC-LIU-1997/AutoSAME.
Adaptively-weighted Integral Space for Fast Multiview Clustering
Aug 25, 2022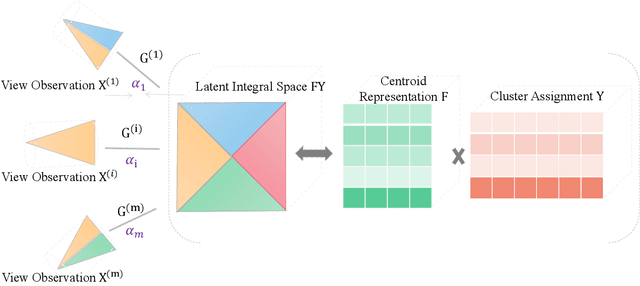
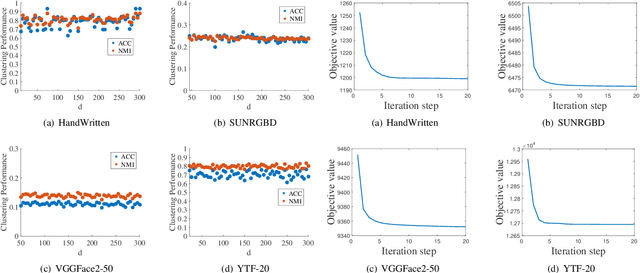
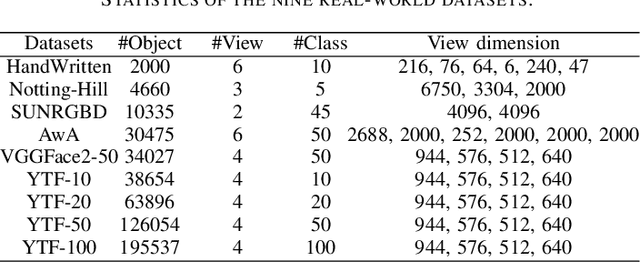
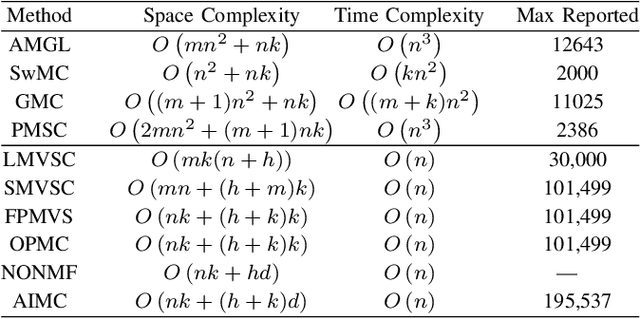
Multiview clustering has been extensively studied to take advantage of multi-source information to improve the clustering performance. In general, most of the existing works typically compute an n * n affinity graph by some similarity/distance metrics (e.g. the Euclidean distance) or learned representations, and explore the pairwise correlations across views. But unfortunately, a quadratic or even cubic complexity is often needed, bringing about difficulty in clustering largescale datasets. Some efforts have been made recently to capture data distribution in multiple views by selecting view-wise anchor representations with k-means, or by direct matrix factorization on the original observations. Despite the significant success, few of them have considered the view-insufficiency issue, implicitly holding the assumption that each individual view is sufficient to recover the cluster structure. Moreover, the latent integral space as well as the shared cluster structure from multiple insufficient views is not able to be simultaneously discovered. In view of this, we propose an Adaptively-weighted Integral Space for Fast Multiview Clustering (AIMC) with nearly linear complexity. Specifically, view generation models are designed to reconstruct the view observations from the latent integral space with diverse adaptive contributions. Meanwhile, a centroid representation with orthogonality constraint and cluster partition are seamlessly constructed to approximate the latent integral space. An alternate minimizing algorithm is developed to solve the optimization problem, which is proved to have linear time complexity w.r.t. the sample size. Extensive experiments conducted on several realworld datasets confirm the superiority of the proposed AIMC method compared with the state-of-the-art methods.