 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\(X\)-evolve: Solution space evolution powered by large language models
Aug 11, 2025



While combining large language models (LLMs) with evolutionary algorithms (EAs) shows promise for solving complex optimization problems, current approaches typically evolve individual solutions, often incurring high LLM call costs. We introduce \(X\)-evolve, a paradigm-shifting method that instead evolves solution spaces \(X\) (sets of individual solutions) - subsets of the overall search space \(S\). In \(X\)-evolve, LLMs generate tunable programs wherein certain code snippets, designated as parameters, define a tunable solution space. A score-based search algorithm then efficiently explores this parametrically defined space, guided by feedback from objective function scores. This strategy enables broader and more efficient exploration, which can potentially accelerate convergence at a much lower search cost, requiring up to two orders of magnitude fewer LLM calls than prior leading methods. We demonstrate \(X\)-evolve's efficacy across three distinct hard optimization problems. For the cap set problem, we discover a larger partial admissible set, establishing a new tighter asymptotic lower bound for the cap set constant (\(C \ge 2.2203\)). In information theory, we uncover a larger independent set for the 15-vertex cycle graph (\(\mathcal{C}_{15}^{\boxtimes 5}\), size 19,946), thereby raising the known lower bound on its Shannon capacity. Furthermore, for the NP-hard online bin packing problem, we generate heuristics that consistently outperform standard strategies across established benchmarks. By evolving solution spaces, our method considerably improves search effectiveness, making it possible to tackle high-dimensional problems that were previously computationally prohibitive.
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Apr 17, 2024



Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
Intelligent Anomaly Detection for Lane Rendering Using Transformer with Self-Supervised Pre-Training and Customized Fine-Tuning
Dec 07, 2023The burgeoning navigation services using digital maps provide great convenience to drivers. Nevertheless, the presence of anomalies in lane rendering map images occasionally introduces potential hazards, as such anomalies can be misleading to human drivers and consequently contribute to unsafe driving conditions. In response to this concern and to accurately and effectively detect the anomalies, this paper transforms lane rendering image anomaly detection into a classification problem and proposes a four-phase pipeline consisting of data pre-processing, self-supervised pre-training with the masked image modeling (MiM) method, customized fine-tuning using cross-entropy based loss with label smoothing, and post-processing to tackle it leveraging state-of-the-art deep learning techniques, especially those involving Transformer models. Various experiments verify the effectiveness of the proposed pipeline. Results indicate that the proposed pipeline exhibits superior performance in lane rendering image anomaly detection, and notably, the self-supervised pre-training with MiM can greatly enhance the detection accuracy while significantly reducing the total training time. For instance, employing the Swin Transformer with Uniform Masking as self-supervised pretraining (Swin-Trans-UM) yielded a heightened accuracy at 94.77% and an improved Area Under The Curve (AUC) score of 0.9743 compared with the pure Swin Transformer without pre-training (Swin-Trans) with an accuracy of 94.01% and an AUC of 0.9498. The fine-tuning epochs were dramatically reduced to 41 from the original 280. In conclusion, the proposed pipeline, with its incorporation of self-supervised pre-training using MiM and other advanced deep learning techniques, emerges as a robust solution for enhancing the accuracy and efficiency of lane rendering image anomaly detection in digital navigation systems.
Robust Lane Detection through Self Pre-training with Masked Sequential Autoencoders and Fine-tuning with Customized PolyLoss
May 26, 2023Lane detection is crucial for vehicle localization which makes it the foundation for automated driving and many intelligent and advanced driving assistant systems. Available vision-based lane detection methods do not make full use of the valuable features and aggregate contextual information, especially the interrelationships between lane lines and other regions of the images in continuous frames. To fill this research gap and upgrade lane detection performance, this paper proposes a pipeline consisting of self pre-training with masked sequential autoencoders and fine-tuning with customized PolyLoss for the end-to-end neural network models using multi-continuous image frames. The masked sequential autoencoders are adopted to pre-train the neural network models with reconstructing the missing pixels from a random masked image as the objective. Then, in the fine-tuning segmentation phase where lane detection segmentation is performed, the continuous image frames are served as the inputs, and the pre-trained model weights are transferred and further updated using the backpropagation mechanism with customized PolyLoss calculating the weighted errors between the output lane detection results and the labeled ground truth. Extensive experiment results demonstrate that, with the proposed pipeline, the lane detection model performance on both normal and challenging scenes can be advanced beyond the state-of-the-art, delivering the best testing accuracy (98.38%), precision (0.937), and F1-measure (0.924) on the normal scene testing set, together with the best overall accuracy (98.36%) and precision (0.844) in the challenging scene test set, while the training time can be substantially shortened.
Exposing Query Identification for Search Transparency
Oct 14, 2021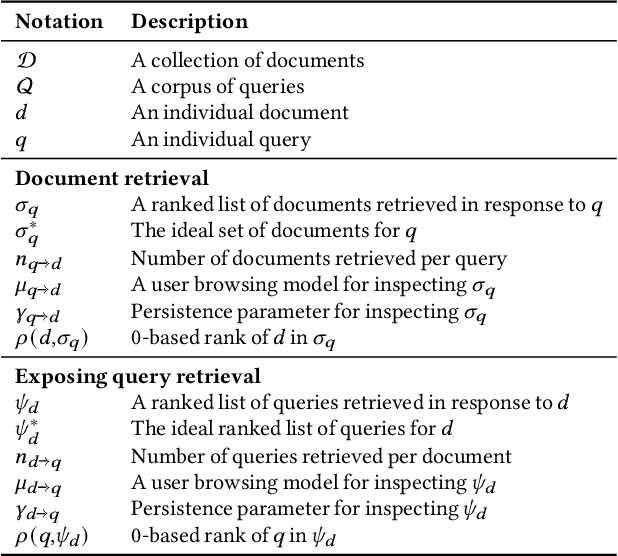

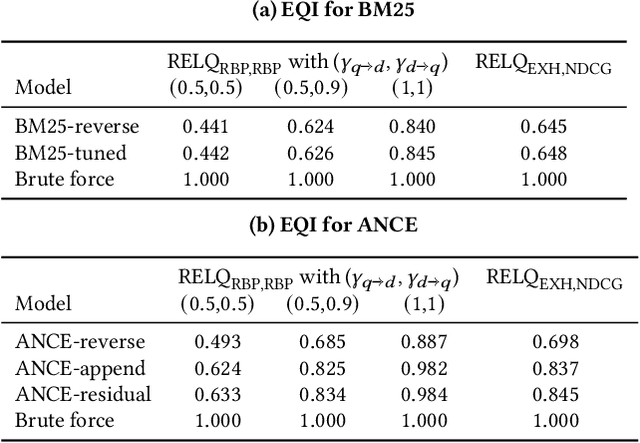
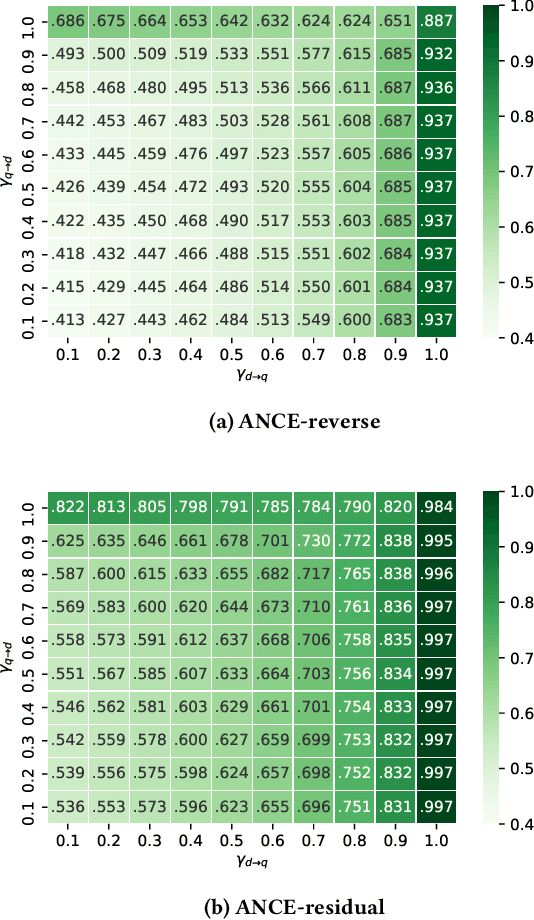
Search systems control the exposure of ranked content to searchers. In many cases, creators value not only the exposure of their content but, moreover, an understanding of the specific searches where the content is surfaced. The problem of identifying which queries expose a given piece of content in the ranking results is an important and relatively under-explored search transparency challenge. Exposing queries are useful for quantifying various issues of search bias, privacy, data protection, security, and search engine optimization. Exact identification of exposing queries in a given system is computationally expensive, especially in dynamic contexts such as web search. In quest of a more lightweight solution, we explore the feasibility of approximate exposing query identification (EQI) as a retrieval task by reversing the role of queries and documents in two classes of search systems: dense dual-encoder models and traditional BM25 models. We then propose how this approach can be improved through metric learning over the retrieval embedding space. We further derive an evaluation metric to measure the quality of a ranking of exposing queries, as well as conducting an empirical analysis focusing on various practical aspects of approximate EQI.