 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph2Video: Leveraging Video Models to Model Dynamic Graph Evolution
Mar 09, 2026Dynamic graphs are common in real-world systems such as social media, recommender systems, and traffic networks. Existing dynamic graph models for link prediction often fall short in capturing the complexity of temporal evolution. They tend to overlook fine-grained variations in temporal interaction order, struggle with dependencies that span long time horizons, and offer limited capability to model pair-specific relational dynamics. To address these challenges, we propose \textbf{Graph2Video}, a video-inspired framework that views the temporal neighborhood of a target link as a sequence of "graph frames". By stacking temporally ordered subgraph frames into a "graph video", Graph2Video leverages the inductive biases of video foundation models to capture both fine-grained local variations and long-range temporal dynamics. It generates a link-level embedding that serves as a lightweight and plug-and-play link-centric memory unit. This embedding integrates seamlessly into existing dynamic graph encoders, effectively addressing the limitations of prior approaches. Extensive experiments on benchmark datasets show that Graph2Video outperforms state-of-the-art baselines on the link prediction task in most cases. The results highlight the potential of borrowing spatio-temporal modeling techniques from computer vision as a promising and effective approach for advancing dynamic graph learning.
DynamicGTR: Leveraging Graph Topology Representation Preferences to Boost VLM Capabilities on Graph QAs
Feb 25, 2026Vision-Language Models (VLMs) have emerged as versatile solutions for zero-shot question answering (QA) across various domains. However, enabling VLMs to effectively comprehend structured graphs and perform accurate, efficient QA remains challenging. Existing approaches typically rely on one single graph topology representation (GTR), such as fixed-style visual images or unified text descriptions. This ``one-size-fits-all'' strategy often neglects model-specific and task-specific preferences, resulting in inaccurate or over-lengthy responses to graph-related queries. To address this, we propose the $\mbox{DynamicGTR}$ framework, which dynamically selects the optimal GTR for each query during inference, thereby enhancing the zero-shot graph QA capabilities of VLMs with a customizable accuracy and brevity trade-off. Extensive experiments show that DynamicGTR not only improves VLM-based graph algorithm QA performance but also successfully transfers the experience trained from synthetic graph algorithm tasks to real-world applications like link prediction and node classification, without any additional training. Additionally, DynamicGTR demonstrates strong transferability across tasks, domains, and models, suggesting its potential as a flexible solution for broad graph scenarios.
Harnessing Adaptive Topology Representations for Zero-Shot Graph Question Answering
Aug 08, 2025



Large Multimodal Models (LMMs) have shown generalized zero-shot capabilities in diverse domain question-answering (QA) tasks, including graph QA that involves complex graph topologies. However, most current approaches use only a single type of graph representation, namely Topology Representation Form (TRF), such as prompt-unified text descriptions or style-fixed visual styles. Those "one-size-fits-all" approaches fail to consider the specific preferences of different models or tasks, often leading to incorrect or overly long responses. To address this, we first analyze the characteristics and weaknesses of existing TRFs, and then design a set of TRFs, denoted by $F_{ZS}$, tailored to zero-shot graph QA. We then introduce a new metric, Graph Response Efficiency (GRE), which measures the balance between the performance and the brevity in graph QA. Built on these, we develop the DynamicTRF framework, which aims to improve both the accuracy and conciseness of graph QA. To be specific, DynamicTRF first creates a TRF Preference (TRFP) dataset that ranks TRFs based on their GRE scores, to probe the question-specific TRF preferences. Then it trains a TRF router on the TRFP dataset, to adaptively assign the best TRF from $F_{ZS}$ for each question during the inference. Extensive experiments across 7 in-domain algorithmic graph QA tasks and 2 out-of-domain downstream tasks show that DynamicTRF significantly enhances the zero-shot graph QA of LMMs in terms of accuracy
Elastic Graph Neural Networks
Jul 05, 2021
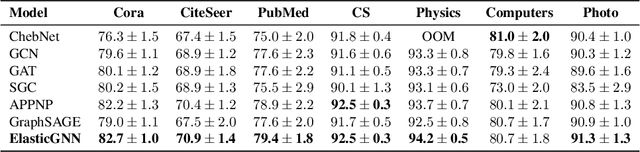
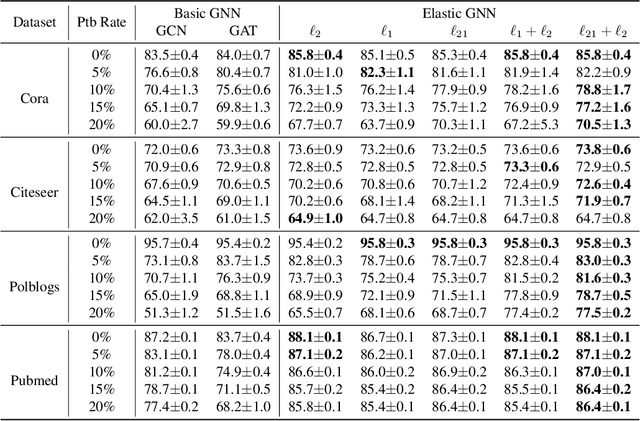
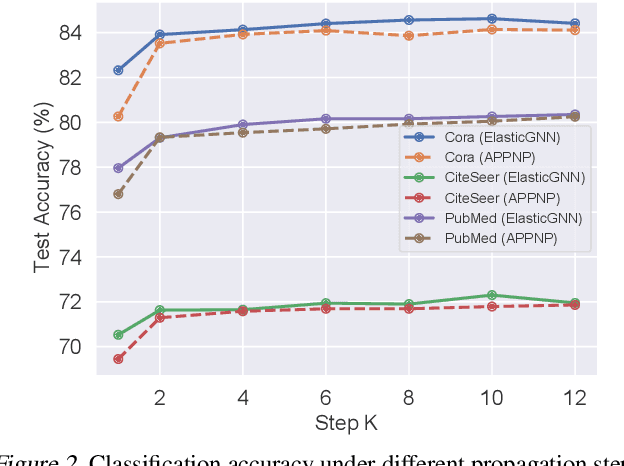
While many existing graph neural networks (GNNs) have been proven to perform $\ell_2$-based graph smoothing that enforces smoothness globally, in this work we aim to further enhance the local smoothness adaptivity of GNNs via $\ell_1$-based graph smoothing. As a result, we introduce a family of GNNs (Elastic GNNs) based on $\ell_1$ and $\ell_2$-based graph smoothing. In particular, we propose a novel and general message passing scheme into GNNs. This message passing algorithm is not only friendly to back-propagation training but also achieves the desired smoothing properties with a theoretical convergence guarantee. Experiments on semi-supervised learning tasks demonstrate that the proposed Elastic GNNs obtain better adaptivity on benchmark datasets and are significantly robust to graph adversarial attacks. The implementation of Elastic GNNs is available at \url{https://github.com/lxiaorui/ElasticGNN}.