 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Test-Time Compute Scaling for Click-Through Rate Prediction via Uncertainty-Triggered Feature Path Exploration
May 24, 2026Scaling test-time compute has proven highly effective for language models, yet this opportunity remains largely unexplored for industrial Click-Through Rate (CTR) prediction. CTR models suffer from a fundamental asymmetry: feature combinations well-represented in training yield confident predictions, while sparsely observed ones produce unreliable outputs. Existing training-phase solutions such as adaptive gating learn a fixed selection function subject to the same sparsity, offering no per-instance recourse at deployment.We propose UTTSI (Uncertainty-Triggered Test-Time Selective Inference), a training-free model-agnostic framework that scales inference depth proportionally to per-instance uncertainty. A dual-signal estimator combining model logit confidence with a data-level frequency prior distinguishes epistemic uncertainty from aleatoric ambiguity. Every instance undergoes adaptive feature filtering to remove unreliable embeddings; uncertain instances additionally receive stochastic feature-path explorations whose predictions are aggregated via consistency-weighted ensembling. Confident instances bypass exploration entirely, keeping average overhead at approximately $2.8\times$ base model cost with worst-case latency unchanged.Experiments on four datasets with three backbone architectures demonstrate consistent, statistically significant gains over all training-phase baselines. A seven-day online A/B test further confirms a 5.3% relative CTR gain ($p < 0.01$), establishing selective test-time compute allocation as a practical complement to training-phase advances for CTR prediction.
Self-Balancing Gradient Allocation for Heterogeneity-Aware Feature Generation in Click-Through Rate Prediction
May 24, 2026Generative pre-training via discrete diffusion provides dense reconstruction supervision across all feature fields simultaneously, mitigating representation collapse from data sparsity in CTR prediction. However, all existing generative CTR methods share a fundamental limitation: the reconstruction objective assigns equal training weight to every feature field, ignoring the profound heterogeneity of reconstruction difficulty across high-cardinality ID fields, sparse categorical attributes, numerical values, and behavioral sequences. This causes easy fields to dominate training gradients while the hardest but most informative fields remain chronically underfit, a problem we term the generative difficulty imbalance.We propose HeteGenCTR, which resolves this imbalance through per-field learnable difficulty parameters jointly trained with the denoising network. This unified signal drives two coordinated components without additional hyperparameters: a self-balancing loss that automatically reallocates gradient budget toward harder fields with a provably stable equilibrium, and a difficulty-guided attention mechanism that suppresses the influence of already-converged easy fields while amplifying cross-field information flow toward hard fields. Both components share the same learned signal and remain mutually consistent throughout training. Experiments on five CTR benchmarks and a seven-day online A/B test demonstrate consistent, statistically significant improvements over state-of-the-art baselines, with disproportionate gains for cold-start and long-tail users.
AgenticRS-EnsNAS: Ensemble-Decoupled Self-Evolving Architecture Search
Mar 20, 2026Neural Architecture Search (NAS) deployment in industrial production systems faces a fundamental validation bottleneck: verifying a single candidate architecture pi requires evaluating the deployed ensemble of M models, incurring prohibitive O(M) computational cost per candidate. This cost barrier severely limits architecture iteration frequency in real-world applications where ensembles (M=50-200) are standard for robustness. This work introduces Ensemble-Decoupled Architecture Search, a framework that leverages ensemble theory to predict system-level performance from single-learner evaluation. We establish the Ensemble-Decoupled Theory with a sufficient condition for monotonic ensemble improvement under homogeneity assumptions: a candidate architecture pi yields lower ensemble error than the current baseline if rho(pi) < rho(pi_old) - (M / (M - 1)) * (Delta E(pi) / sigma^2(pi)), where Delta E, rho, and sigma^2 are estimable from lightweight dual-learner training. This decouples architecture search from full ensemble training, reducing per-candidate search cost from O(M) to O(1) while maintaining O(M) deployment cost only for validated winners. We unify solution strategies across pipeline continuity: (1) closed-form optimization for tractable continuous pi (exemplified by feature bagging in CTR prediction), (2) constrained differentiable optimization for intractable continuous pi, and (3) LLM-driven search with iterative monotonic acceptance for discrete pi. The framework reveals two orthogonal improvement mechanisms -- base diversity gain and accuracy gain -- providing actionable design principles for industrial-scale NAS. All theoretical derivations are rigorous with detailed proofs deferred to the appendix. Comprehensive empirical validation will be included in the journal extension of this work.
Bridging Sequential and Contextual Features with a Dual-View of Fine-grained Core-Behaviors and Global Interest-Distribution
Mar 13, 2026Click-through rate (CTR) prediction tasks typically estimate the probability of a user clicking on a candidate item by modeling both user behavior sequence features and the item's contextual features, where the user behavior sequence is particularly critical as it dynamically reflects real-time shifts in user interest. Traditional CTR models often aggregate this dynamic sequence into a single vector before interacting it with contextual features. This approach, however, not only leads to behavior information loss during aggregation but also severely limits the model's capacity to capture interactions between contextual features and specific user behaviors, ultimately impairing its ability to capture fine-grained behavioral details and hindering models' prediction accuracy. Conversely, a naive approach of directly interacting with each user action with contextual features is computationally expensive and introduces significant noise from behaviors irrelevant to the candidate item. This noise tends to overwhelm the valuable signals arising from interactions involving more behaviors relevant to the candidate item. Therefore, to resolve the above issue, we propose a Core-Behaviors and Distributional-Compensation Dual-View Interaction Network (CDNet), which bridges the gap between sequential and contextual feature interactions from two complementary angles: a fine-grained interaction involving the most relevant behaviors and contextual features, and a coarse-grained interaction that models the user's overall interest distribution against the contextual features. By simultaneously capturing important behavioral details without forgoing the holistic user interest, CDNet effectively models the interplay between sequential and contextual features without imposing a significant computational burden. Ultimately, extensive experiments validate the effectiveness of CDNet.
Deferred is Better: A Framework for Multi-Granularity Deferred Interaction of Heterogeneous Features
Mar 13, 2026Click-through rate (CTR) prediction models estimates the probability of a user-item click by modeling interactions across a vast feature space. A fundamental yet often overlooked challenge is the inherent heterogeneity of these features: their sparsity and information content vary dramatically. For instance, categorical features like item IDs are extremely sparse, whereas numerical features like item price are relatively dense. Prevailing CTR models have largely ignored this heterogeneity, employing a uniform feature interaction strategy that inputs all features into the interaction layers simultaneously. This approach is suboptimal, as the premature introduction of low-information features can inject significant noise and mask the signals from information-rich features, which leads to model collapse and hinders the learning of robust representations. To address the above challenge, we propose a Multi-Granularity Information-Aware Deferred Interaction Network (MGDIN), which adaptively defers the introduction of features into the feature interaction process. MGDIN's core mechanism operates in two stages: First, it employs a multi-granularity feature grouping strategy to partition the raw features into distinct groups with more homogeneous information density in different granularities, thereby mitigating the effects of extreme individual feature sparsity and enabling the model to capture feature interactions from diverse perspectives. Second, a delayed interaction mechanism is implemented through a hierarchical masking strategy, which governs when and how each group participates by masking low-information groups in the early layers and progressively unmasking them as the network deepens. This deferred introduction allows the model to establish a robust understanding based on high-information features before gradually incorporating sparser information from other groups...
Infer As You Train: A Symmetric Paradigm of Masked Generative for Click-Through Rate Prediction
Nov 18, 2025Generative models are increasingly being explored in click-through rate (CTR) prediction field to overcome the limitations of the conventional discriminative paradigm, which rely on a simple binary classification objective. However, existing generative models typically confine the generative paradigm to the training phase, primarily for representation learning. During online inference, they revert to a standard discriminative paradigm, failing to leverage their powerful generative capabilities to further improve prediction accuracy. This fundamental asymmetry between the training and inference phases prevents the generative paradigm from realizing its full potential. To address this limitation, we propose the Symmetric Masked Generative Paradigm for CTR prediction (SGCTR), a novel framework that establishes symmetry between the training and inference phases. Specifically, after acquiring generative capabilities by learning feature dependencies during training, SGCTR applies the generative capabilities during online inference to iteratively redefine the features of input samples, which mitigates the impact of noisy features and enhances prediction accuracy. Extensive experiments validate the superiority of SGCTR, demonstrating that applying the generative paradigm symmetrically across both training and inference significantly unlocks its power in CTR prediction.
DGenCTR: Towards a Universal Generative Paradigm for Click-Through Rate Prediction via Discrete Diffusion
Aug 20, 2025



Recent advances in generative models have inspired the field of recommender systems to explore generative approaches, but most existing research focuses on sequence generation, a paradigm ill-suited for click-through rate (CTR) prediction. CTR models critically depend on a large number of cross-features between the target item and the user to estimate the probability of clicking on the item, and discarding these cross-features will significantly impair model performance. Therefore, to harness the ability of generative models to understand data distributions and thereby alleviate the constraints of traditional discriminative models in label-scarce space, diverging from the item-generation paradigm of sequence generation methods, we propose a novel sample-level generation paradigm specifically designed for the CTR task: a two-stage Discrete Diffusion-Based Generative CTR training framework (DGenCTR). This two-stage framework comprises a diffusion-based generative pre-training stage and a CTR-targeted supervised fine-tuning stage for CTR. Finally, extensive offline experiments and online A/B testing conclusively validate the effectiveness of our framework.
Global-Distribution Aware Scenario-Specific Variational Representation Learning Framework
Aug 20, 2025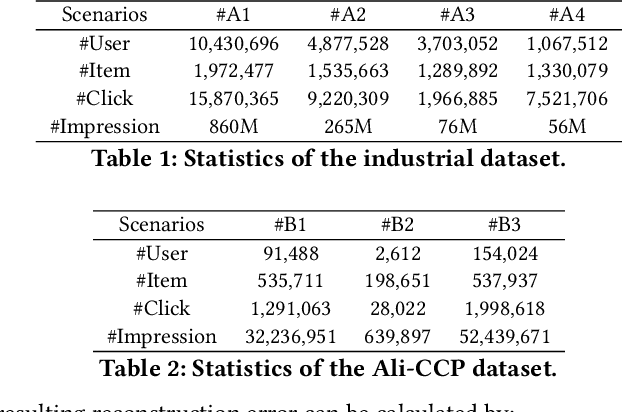
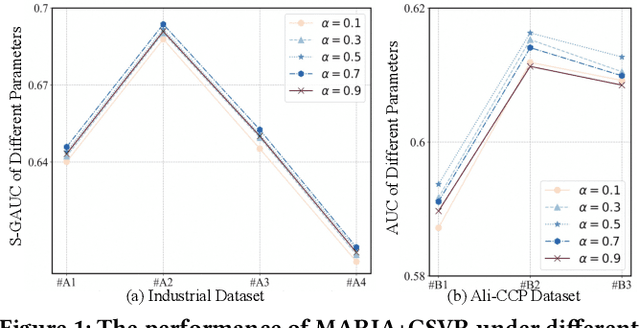
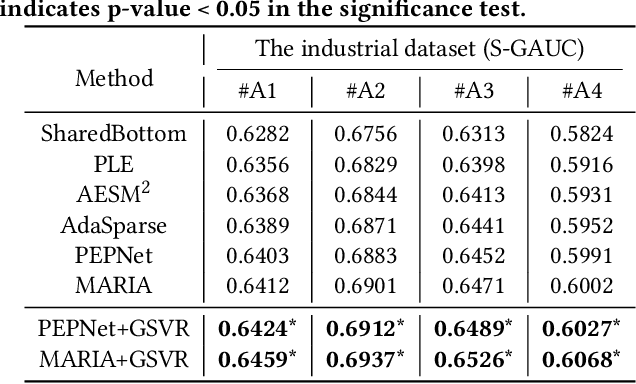
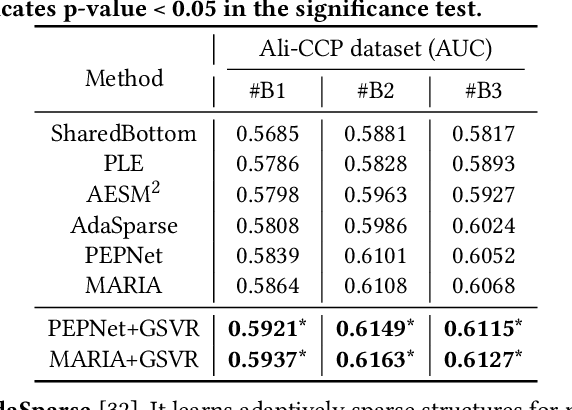
With the emergence of e-commerce, the recommendations provided by commercial platforms must adapt to diverse scenarios to accommodate users' varying shopping preferences. Current methods typically use a unified framework to offer personalized recommendations for different scenarios. However, they often employ shared bottom representations, which partially hinders the model's capacity to capture scenario uniqueness. Ideally, users and items should exhibit specific characteristics in different scenarios, prompting the need to learn scenario-specific representations to differentiate scenarios. Yet, variations in user and item interactions across scenarios lead to data sparsity issues, impeding the acquisition of scenario-specific representations. To learn robust scenario-specific representations, we introduce a Global-Distribution Aware Scenario-Specific Variational Representation Learning Framework (GSVR) that can be directly applied to existing multi-scenario methods. Specifically, considering the uncertainty stemming from limited samples, our approach employs a probabilistic model to generate scenario-specific distributions for each user and item in each scenario, estimated through variational inference (VI). Additionally, we introduce the global knowledge-aware multinomial distributions as prior knowledge to regulate the learning of the posterior user and item distributions, ensuring similarities among distributions for users with akin interests and items with similar side information. This mitigates the risk of users or items with fewer records being overwhelmed in sparse scenarios. Extensive experimental results affirm the efficacy of GSVR in assisting existing multi-scenario recommendation methods in learning more robust representations.
Distribution-Guided Auto-Encoder for User Multimodal Interest Cross Fusion
Aug 20, 2025Traditional recommendation methods rely on correlating the embedding vectors of item IDs to capture implicit collaborative filtering signals to model the user's interest in the target item. Consequently, traditional ID-based methods often encounter data sparsity problems stemming from the sparse nature of ID features. To alleviate the problem of item ID sparsity, recommendation models incorporate multimodal item information to enhance recommendation accuracy. However, existing multimodal recommendation methods typically employ early fusion approaches, which focus primarily on combining text and image features, while neglecting the contextual influence of user behavior sequences. This oversight prevents dynamic adaptation of multimodal interest representations based on behavioral patterns, consequently restricting the model's capacity to effectively capture user multimodal interests. Therefore, this paper proposes the Distribution-Guided Multimodal-Interest Auto-Encoder (DMAE), which achieves the cross fusion of user multimodal interest at the behavioral level.Ultimately, extensive experiments demonstrate the superiority of DMAE.
CSMF: Cascaded Selective Mask Fine-Tuning for Multi-Objective Embedding-Based Retrieval
Apr 17, 2025



Multi-objective embedding-based retrieval (EBR) has become increasingly critical due to the growing complexity of user behaviors and commercial objectives. While traditional approaches often suffer from data sparsity and limited information sharing between objectives, recent methods utilizing a shared network alongside dedicated sub-networks for each objective partially address these limitations. However, such methods significantly increase the model parameters, leading to an increased retrieval latency and a limited ability to model causal relationships between objectives. To address these challenges, we propose the Cascaded Selective Mask Fine-Tuning (CSMF), a novel method that enhances both retrieval efficiency and serving performance for multi-objective EBR. The CSMF framework selectively masks model parameters to free up independent learning space for each objective, leveraging the cascading relationships between objectives during the sequential fine-tuning. Without increasing network parameters or online retrieval overhead, CSMF computes a linearly weighted fusion score for multiple objective probabilities while supporting flexible adjustment of each objective's weight across various recommendation scenarios. Experimental results on real-world datasets demonstrate the superior performance of CSMF, and online experiments validate its significant practical value.