 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgriAgent: Contract-Driven Planning and Capability-Aware Tool Orchestration in Real-World Agriculture
Jan 13, 2026Intelligent agent systems in real-world agricultural scenarios must handle diverse tasks under multimodal inputs, ranging from lightweight information understanding to complex multi-step execution. However, most existing approaches rely on a unified execution paradigm, which struggles to accommodate large variations in task complexity and incomplete tool availability commonly observed in agricultural environments. To address this challenge, we propose AgriAgent, a two-level agent framework for real-world agriculture. AgriAgent adopts a hierarchical execution strategy based on task complexity: simple tasks are handled through direct reasoning by modality-specific agents, while complex tasks trigger a contract-driven planning mechanism that formulates tasks as capability requirements and performs capability-aware tool orchestration and dynamic tool generation, enabling multi-step and verifiable execution with failure recovery. Experimental results show that AgriAgent achieves higher execution success rates and robustness on complex tasks compared to existing tool-centric agent baselines that rely on unified execution paradigms. All code, data will be released at after our work be accepted to promote reproducible research.
ObjSplat: Geometry-Aware Gaussian Surfels for Active Object Reconstruction
Jan 11, 2026Autonomous high-fidelity object reconstruction is fundamental for creating digital assets and bridging the simulation-to-reality gap in robotics. We present ObjSplat, an active reconstruction framework that leverages Gaussian surfels as a unified representation to progressively reconstruct unknown objects with both photorealistic appearance and accurate geometry. Addressing the limitations of conventional opacity or depth-based cues, we introduce a geometry-aware viewpoint evaluation pipeline that explicitly models back-face visibility and occlusion-aware multi-view covisibility, reliably identifying under-reconstructed regions even on geometrically complex objects. Furthermore, to overcome the limitations of greedy planning strategies, ObjSplat employs a next-best-path (NBP) planner that performs multi-step lookahead on a dynamically constructed spatial graph. By jointly optimizing information gain and movement cost, this planner generates globally efficient trajectories. Extensive experiments in simulation and on real-world cultural artifacts demonstrate that ObjSplat produces physically consistent models within minutes, achieving superior reconstruction fidelity and surface completeness while significantly reducing scan time and path length compared to state-of-the-art approaches. Project page: https://li-yuetao.github.io/ObjSplat-page/ .
SlingBAG Pro: Accelerating point cloud-based iterative reconstruction for 3D photoacoustic imaging with arbitrary array geometries
Jan 06, 2026High-quality three-dimensional (3D) photoacoustic imaging (PAI) is gaining increasing attention in clinical applications. To address the challenges of limited space and high costs, irregular geometric transducer arrays that conform to specific imaging regions are promising for achieving high-quality 3D PAI with fewer transducers. However, traditional iterative reconstruction algorithms struggle with irregular array configurations, suffering from high computational complexity, substantial memory requirements, and lengthy reconstruction times. In this work, we introduce SlingBAG Pro, an advanced reconstruction algorithm based on the point cloud iteration concept of the Sliding ball adaptive growth (SlingBAG) method, while extending its compatibility to arbitrary array geometries. SlingBAG Pro maintains high reconstruction quality, reduces the number of required transducers, and employs a hierarchical optimization strategy that combines zero-gradient filtering with progressively increased temporal sampling rates during iteration. This strategy rapidly removes redundant spatial point clouds, accelerates convergence, and significantly shortens overall reconstruction time. Compared to the original SlingBAG algorithm, SlingBAG Pro achieves up to a 2.2-fold speed improvement in point cloud-based 3D PA reconstruction under irregular array geometries. The proposed method is validated through both simulation and in vivo mouse experiments, and the source code is publicly available at https://github.com/JaegerCQ/SlingBAG_Pro.
Digital Twin AI: Opportunities and Challenges from Large Language Models to World Models
Jan 04, 2026Digital twins, as precise digital representations of physical systems, have evolved from passive simulation tools into intelligent and autonomous entities through the integration of artificial intelligence technologies. This paper presents a unified four-stage framework that systematically characterizes AI integration across the digital twin lifecycle, spanning modeling, mirroring, intervention, and autonomous management. By synthesizing existing technologies and practices, we distill a unified four-stage framework that systematically characterizes how AI methodologies are embedded across the digital twin lifecycle: (1) modeling the physical twin through physics-based and physics-informed AI approaches, (2) mirroring the physical system into a digital twin with real-time synchronization, (3) intervening in the physical twin through predictive modeling, anomaly detection, and optimization strategies, and (4) achieving autonomous management through large language models, foundation models, and intelligent agents. We analyze the synergy between physics-based modeling and data-driven learning, highlighting the shift from traditional numerical solvers to physics-informed and foundation models for physical systems. Furthermore, we examine how generative AI technologies, including large language models and generative world models, transform digital twins into proactive and self-improving cognitive systems capable of reasoning, communication, and creative scenario generation. Through a cross-domain review spanning eleven application domains, including healthcare, aerospace, smart manufacturing, robotics, and smart cities, we identify common challenges related to scalability, explainability, and trustworthiness, and outline directions for responsible AI-driven digital twin systems.
SoulSeek: Exploring the Use of Social Cues in LLM-based Information Seeking
Jan 03, 2026Social cues, which convey others' presence, behaviors, or identities, play a crucial role in human information seeking by helping individuals judge relevance and trustworthiness. However, existing LLM-based search systems primarily rely on semantic features, creating a misalignment with the socialized cognition underlying natural information seeking. To address this gap, we explore how the integration of social cues into LLM-based search influences users' perceptions, experiences, and behaviors. Focusing on social media platforms that are beginning to adopt LLM-based search, we integrate design workshops, the implementation of the prototype system (SoulSeek), a between-subjects study, and mixed-method analyses to examine both outcome- and process-level findings. The workshop informs the prototype's cue-integrated design. The study shows that social cues improve perceived outcomes and experiences, promote reflective information behaviors, and reveal limits of current LLM-based search. We propose design implications emphasizing better social-knowledge understanding, personalized cue settings, and controllable interactions.
Improving Scientific Document Retrieval with Academic Concept Index
Jan 02, 2026Adapting general-domain retrievers to scientific domains is challenging due to the scarcity of large-scale domain-specific relevance annotations and the substantial mismatch in vocabulary and information needs. Recent approaches address these issues through two independent directions that leverage large language models (LLMs): (1) generating synthetic queries for fine-tuning, and (2) generating auxiliary contexts to support relevance matching. However, both directions overlook the diverse academic concepts embedded within scientific documents, often producing redundant or conceptually narrow queries and contexts. To address this limitation, we introduce an academic concept index, which extracts key concepts from papers and organizes them guided by an academic taxonomy. This structured index serves as a foundation for improving both directions. First, we enhance the synthetic query generation with concept coverage-based generation (CCQGen), which adaptively conditions LLMs on uncovered concepts to generate complementary queries with broader concept coverage. Second, we strengthen the context augmentation with concept-focused auxiliary contexts (CCExpand), which leverages a set of document snippets that serve as concise responses to the concept-aware CCQGen queries. Extensive experiments show that incorporating the academic concept index into both query generation and context augmentation leads to higher-quality queries, better conceptual alignment, and improved retrieval performance.
Benchmarking ERP Analysis: Manual Features, Deep Learning, and Foundation Models
Jan 02, 2026Event-related potential (ERP), a specialized paradigm of electroencephalographic (EEG), reflects neurological responses to external stimuli or events, generally associated with the brain's processing of specific cognitive tasks. ERP plays a critical role in cognitive analysis, the detection of neurological diseases, and the assessment of psychological states. Recent years have seen substantial advances in deep learning-based methods for spontaneous EEG and other non-time-locked task-related EEG signals. However, their effectiveness on ERP data remains underexplored, and many existing ERP studies still rely heavily on manually extracted features. In this paper, we conduct a comprehensive benchmark study that systematically compares traditional manual features (followed by a linear classifier), deep learning models, and pre-trained EEG foundation models for ERP analysis. We establish a unified data preprocessing and training pipeline and evaluate these approaches on two representative tasks, ERP stimulus classification and ERP-based brain disease detection, across 12 publicly available datasets. Furthermore, we investigate various patch-embedding strategies within advanced Transformer architectures to identify embedding designs that better suit ERP data. Our study provides a landmark framework to guide method selection and tailored model design for future ERP analysis. The code is available at https://github.com/DL4mHealth/ERP-Benchmark.
GaussianDWM: 3D Gaussian Driving World Model for Unified Scene Understanding and Multi-Modal Generation
Dec 29, 2025Driving World Models (DWMs) have been developing rapidly with the advances of generative models. However, existing DWMs lack 3D scene understanding capabilities and can only generate content conditioned on input data, without the ability to interpret or reason about the driving environment. Moreover, current approaches represent 3D spatial information with point cloud or BEV features do not accurately align textual information with the underlying 3D scene. To address these limitations, we propose a novel unified DWM framework based on 3D Gaussian scene representation, which enables both 3D scene understanding and multi-modal scene generation, while also enabling contextual enrichment for understanding and generation tasks. Our approach directly aligns textual information with the 3D scene by embedding rich linguistic features into each Gaussian primitive, thereby achieving early modality alignment. In addition, we design a novel task-aware language-guided sampling strategy that removes redundant 3D Gaussians and injects accurate and compact 3D tokens into LLM. Furthermore, we design a dual-condition multi-modal generation model, where the information captured by our vision-language model is leveraged as a high-level language condition in combination with a low-level image condition, jointly guiding the multi-modal generation process. We conduct comprehensive studies on the nuScenes, and NuInteract datasets to validate the effectiveness of our framework. Our method achieves state-of-the-art performance. We will release the code publicly on GitHub https://github.com/dtc111111/GaussianDWM.
From Pixels to Predicates Structuring urban perception with scene graphs
Dec 22, 2025Perception research is increasingly modelled using streetscapes, yet many approaches still rely on pixel features or object co-occurrence statistics, overlooking the explicit relations that shape human perception. This study proposes a three stage pipeline that transforms street view imagery (SVI) into structured representations for predicting six perceptual indicators. In the first stage, each image is parsed using an open-set Panoptic Scene Graph model (OpenPSG) to extract object predicate object triplets. In the second stage, compact scene-level embeddings are learned through a heterogeneous graph autoencoder (GraphMAE). In the third stage, a neural network predicts perception scores from these embeddings. We evaluate the proposed approach against image-only baselines in terms of accuracy, precision, and cross-city generalization. Results indicate that (i) our approach improves perception prediction accuracy by an average of 26% over baseline models, and (ii) maintains strong generalization performance in cross-city prediction tasks. Additionally, the structured representation clarifies which relational patterns contribute to lower perception scores in urban scenes, such as graffiti on wall and car parked on sidewalk. Overall, this study demonstrates that graph-based structure provides expressive, generalizable, and interpretable signals for modelling urban perception, advancing human-centric and context-aware urban analytics.
Adaptation of Agentic AI
Dec 22, 2025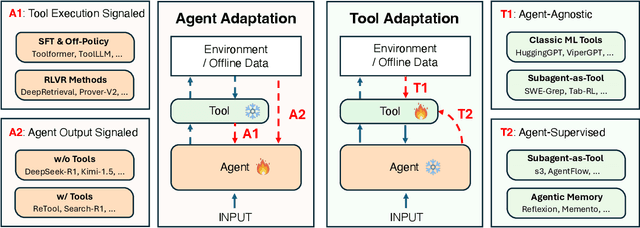
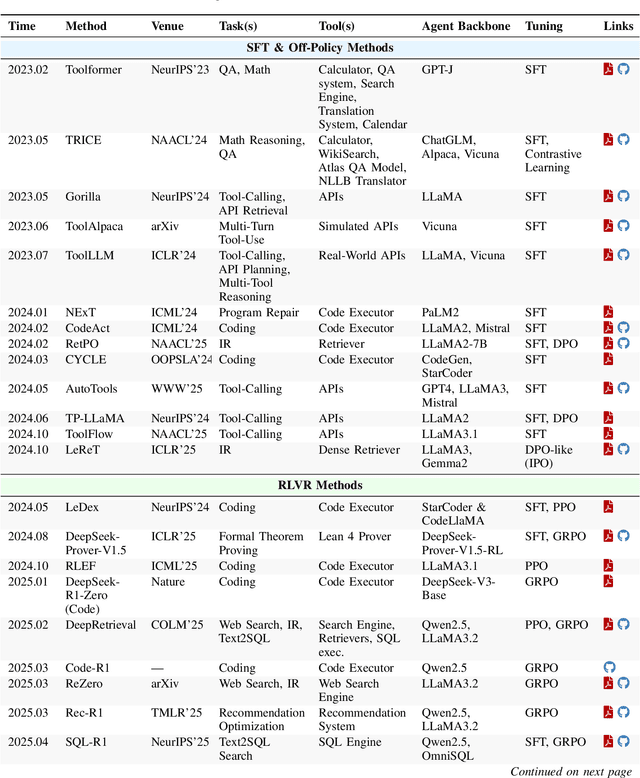
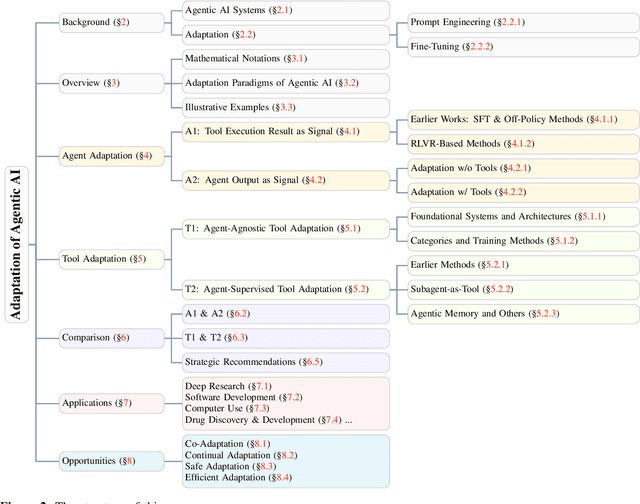
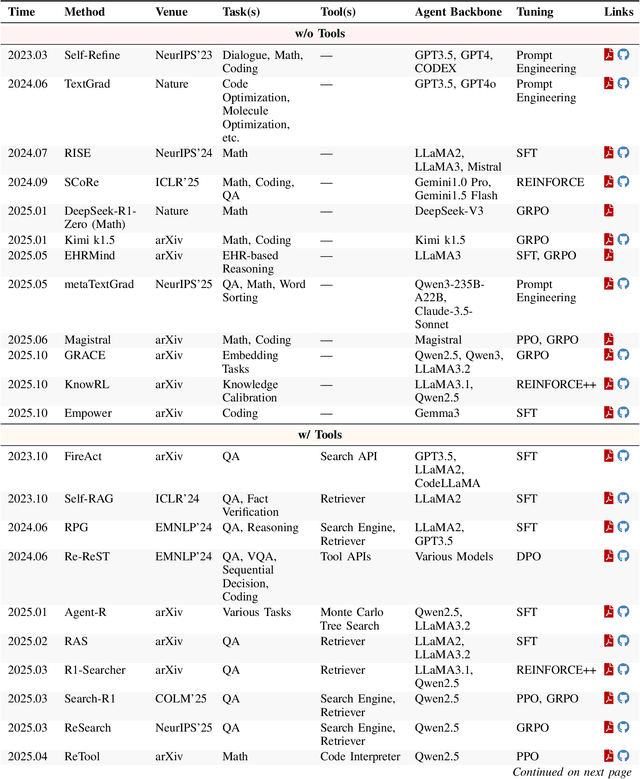
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.