 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEEK: Context Map as an Orientation Cache for Long-Context LLM Agents
May 19, 2026Large language model (LLM) agents increasingly operate over long and recurring external contexts, like document corpora and code repositories. Across invocations, existing approaches preserve either the agent's trajectory, passive access to raw material, or task-level strategies. None of them preserves what we argue is most needed for repeated same-context workloads: reusable orientation knowledge (e.g., what the context contains, how it is organized, and which entities, constants, and schemas have historically been useful) about the recurring context itself. We introduce PEEK, a system that caches and maintains this orientation knowledge as a context map: a small, constant-sized artifact in the agent's prompt that gives it a persistent peek into the external context. The map is maintained by a programmable cache policy with three modules: a Distiller that extracts transferable knowledge from inference-time signals, a Cartographer that translates it into structured edits, and a priority-based Evictor that enforces a fixed token budget. On long-context reasoning and information aggregation, PEEK improves over strong baselines by 6.3-34.0% while using 93-145 fewer iterations and incurring 1.7-5.8x lower cost than the state-of-the-art prompt-learning framework, ACE. On context learning, PEEK improves solving rate and rubric accuracy by 6.0-14.0% and 7.8-12.1%, respectively, at 1.4x lower cost than ACE. These gains generalize across LMs and agent architectures, including OpenAI Codex, a production-grade coding agent. Together, these results show that a context map helps long-context LLM agents interact with recurring external contexts more accurately and efficiently.
FrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
May 14, 2026Many real-world coding challenges are open-ended and admit no known optimal solution. Yet, recent progress in LLM coding has focused on well-defined tasks such as feature implementation, bug fixing, and competitive programming. Open-ended coding remains a weak spot for LLMs, largely because open-ended training problems are scarce and expensive to construct. Our goal is to synthesize open-ended coding problems at scale to train stronger LLM coders. We introduce FrontierSmith, an automated system for iteratively evolving open-ended problems from existing closed-ended coding tasks. Starting from competitive programming problems, FrontierSmith generates candidate open-ended variants by changing the problems'goals, restricting outputs, and generalizing inputs. It then uses a quantitative idea divergence metric to select problems that elicit genuinely diverse approaches from different solvers. Agents then generate test cases and verifiers for the surviving candidates. On two open-ended coding benchmarks, training on our synthesized data yields substantial gains over the base models: Qwen3.5-9B improves by +8.82 score on FrontierCS and +306.36 (Elo-rating-based performance) on ALE-bench; Qwen3.5-27B improves by +12.12 and +309.12, respectively. The synthesized problems also make agents take more turns and use more tokens, similar to human-curated ones, suggesting that closed-ended seeds can be a practical starting point for long-horizon coding data.
Combee: Scaling Prompt Learning for Self-Improving Language Model Agents
Apr 05, 2026Recent advances in prompt learning allow large language model agents to acquire task-relevant knowledge from inference-time context without parameter changes. For example, existing methods (like ACE or GEPA) can learn system prompts to improve accuracy based on previous agent runs. However, these methods primarily focus on single-agent or low-parallelism settings. This fundamentally limits their ability to efficiently learn from a large set of collected agentic traces. It would be efficient and beneficial to run prompt learning in parallel to accommodate the growing trend of learning from many agentic traces or parallel agent executions. Yet without a principled strategy for scaling, current methods suffer from quality degradation with high parallelism. To improve both the efficiency and quality of prompt learning, we propose Combee, a novel framework to scale parallel prompt learning for self-improving agents. Combee speeds up learning and enables running many agents in parallel while learning from their aggregate traces without quality degradation. To achieve this, Combee leverages parallel scans and employs an augmented shuffle mechanism; Combee also introduces a dynamic batch size controller to balance quality and delay. Evaluations on AppWorld, Terminal-Bench, Formula, and FiNER demonstrate that Combee achieves up to 17x speedup over previous methods with comparable or better accuracy and equivalent cost.
Meta-Harness: End-to-End Optimization of Model Harnesses
Mar 30, 2026The performance of large language model (LLM) systems depends not only on model weights, but also on their harness: the code that determines what information to store, retrieve, and present to the model. Yet harnesses are still designed largely by hand, and existing text optimizers are poorly matched to this setting because they compress feedback too aggressively. We introduce Meta-Harness, an outer-loop system that searches over harness code for LLM applications. It uses an agentic proposer that accesses the source code, scores, and execution traces of all prior candidates through a filesystem. On online text classification, Meta-Harness improves over a state-of-the-art context management system by 7.7 points while using 4x fewer context tokens. On retrieval-augmented math reasoning, a single discovered harness improves accuracy on 200 IMO-level problems by 4.7 points on average across five held-out models. On agentic coding, discovered harnesses surpass the best hand-engineered baselines on TerminalBench-2. Together, these results show that richer access to prior experience can enable automated harness engineering.
Adaptation of Agentic AI
Dec 22, 2025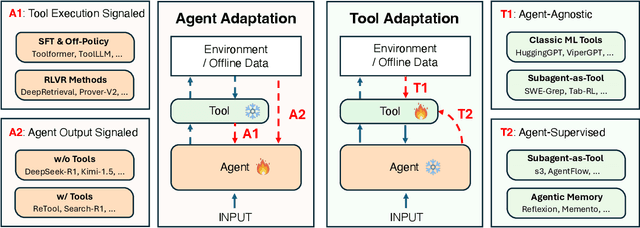
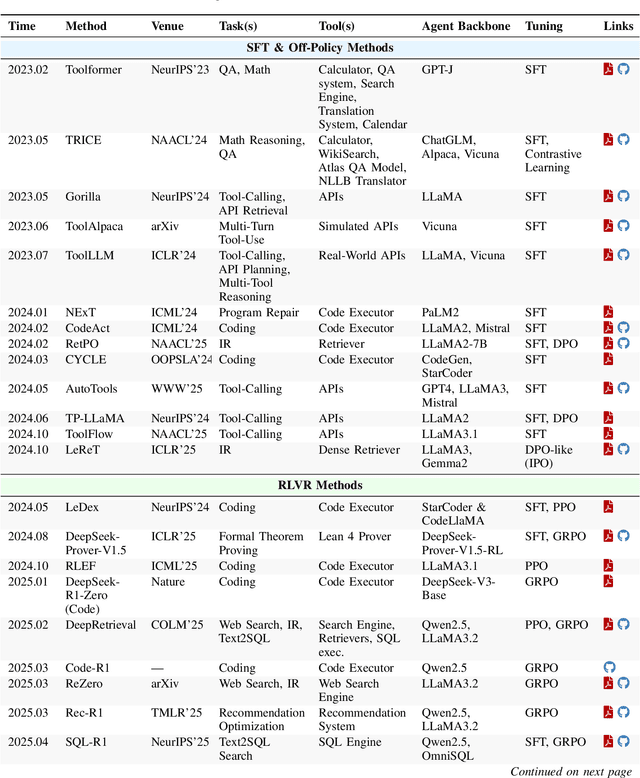
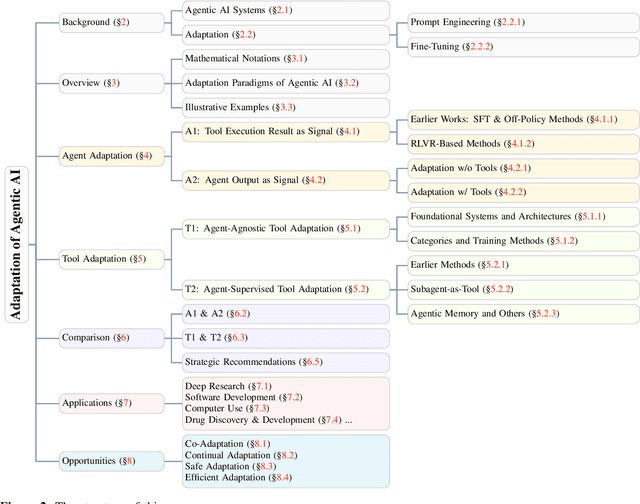
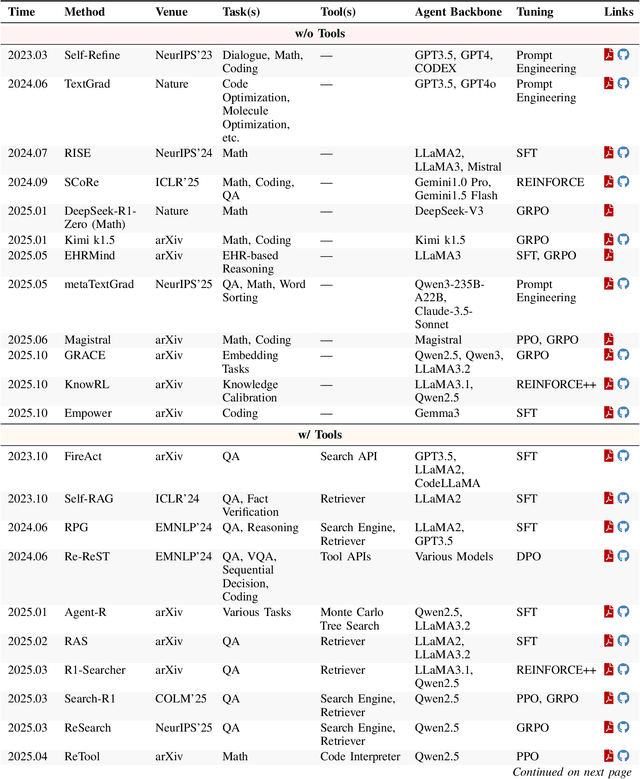
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
EVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
Dec 16, 2025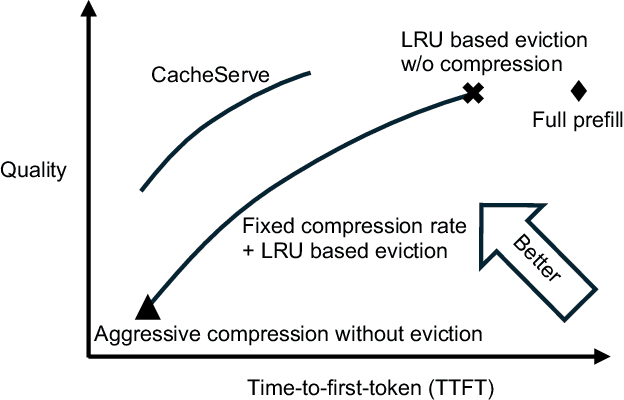
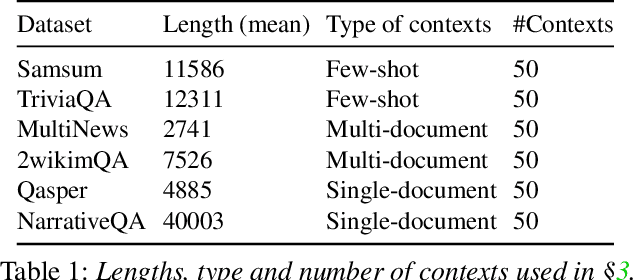
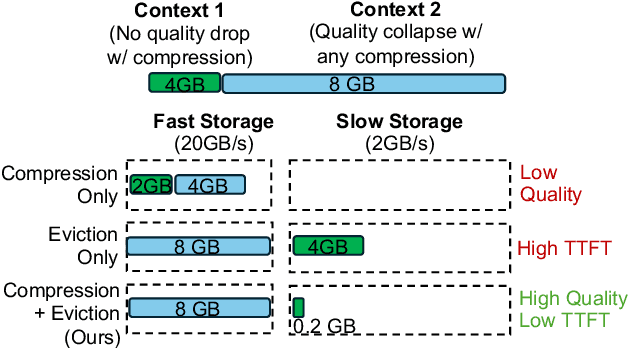
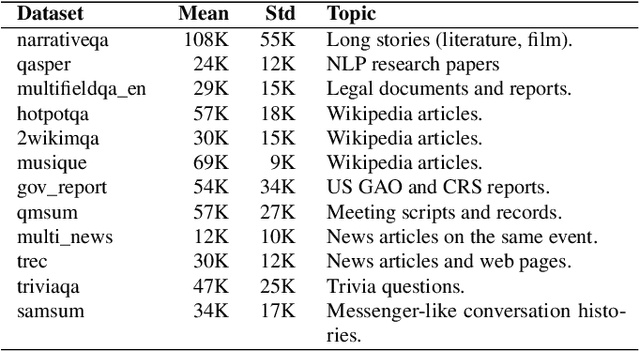
Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Oct 06, 2025



Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation -- modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.
FlowRL: Matching Reward Distributions for LLM Reasoning
Sep 18, 2025We propose FlowRL: matching the full reward distribution via flow balancing instead of maximizing rewards in large language model (LLM) reinforcement learning (RL). Recent advanced reasoning models adopt reward-maximizing methods (\eg, PPO and GRPO), which tend to over-optimize dominant reward signals while neglecting less frequent but valid reasoning paths, thus reducing diversity. In contrast, we transform scalar rewards into a normalized target distribution using a learnable partition function, and then minimize the reverse KL divergence between the policy and the target distribution. We implement this idea as a flow-balanced optimization method that promotes diverse exploration and generalizable reasoning trajectories. We conduct experiments on math and code reasoning tasks: FlowRL achieves a significant average improvement of $10.0\%$ over GRPO and $5.1\%$ over PPO on math benchmarks, and performs consistently better on code reasoning tasks. These results highlight reward distribution-matching as a key step toward efficient exploration and diverse reasoning in LLM reinforcement learning.
Cost-Efficient Serving of LLM Agents via Test-Time Plan Caching
Jun 17, 2025



LLM-based agentic applications have shown increasingly remarkable capabilities in complex workflows but incur substantial costs due to extensive planning and reasoning requirements. Existing LLM caching techniques (like context caching and semantic caching), primarily designed for serving chatbots, are insufficient for agentic applications where outputs depend on external data or environmental contexts. We propose agentic plan caching, a novel approach that extracts, stores, adapts, and reuses structured plan templates from planning stages of agentic applications across semantically similar tasks to reduce the cost of serving. Unlike traditional semantic caching, our system extracts plan templates from completed agent executions at test-time, employs keyword extraction to match new requests against cached plans, and utilizes lightweight models to adapt these templates to task-specific plans with contexts. Evaluation across multiple real-world agentic applications shows that our system can reduce costs by 46.62% on average while maintaining performance, offering a more efficient solution for serving LLM-based agents that complements existing LLM serving infrastructures.