 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuQuant++: Fine-grained Rotation Enhances Microscaling FP4 Quantization
Apr 21, 2026The MXFP4 microscaling format, which partitions tensors into blocks of 32 elements sharing an E8M0 scaling factor, has emerged as a promising substrate for efficient LLM inference, backed by native hardware support on NVIDIA Blackwell Tensor Cores. However, activation outliers pose a unique challenge under this format: a single outlier inflates the shared block scale, compressing the effective dynamic range of the remaining elements and causing significant quantization error. Existing rotation-based remedies, including randomized Hadamard and learnable rotations, are data-agnostic and therefore unable to specifically target the channels where outliers concentrate. We propose DuQuant++, which adapts the outlier-aware fine-grained rotation of DuQuant to the MXFP4 format by aligning the rotation block size with the microscaling group size (B{=}32). Because each MXFP4 group possesses an independent scaling factor, the cross-block variance issue that necessitates dual rotations and a zigzag permutation in the original DuQuant becomes irrelevant, enabling DuQuant++ to replace the entire pipeline with a single outlier-aware rotation, which halves the online rotation cost while simultaneously smoothing the weight distribution. Extensive experiments on the LLaMA-3 family under MXFP4 W4A4 quantization show that DuQuant++ consistently achieves state-of-the-art performance. Our code is available at https://github.com/Hsu1023/DuQuant-v2.
DeepCORO-CLIP: A Multi-View Foundation Model for Comprehensive Coronary Angiography Video-Text Analysis and External Validation
Mar 18, 2026Coronary angiography is the reference standard for evaluating coronary artery disease, yet visual interpretation remains variable between readers. Existing artificial intelligence methods typically analyze single frames or projections and focus mainly on stenosis, limiting comprehensive coronary assessment. We present DeepCORO-CLIP, a multi-view foundation model trained with video-text contrastive learning on 203,808 angiography videos from 28,117 patients across 32,473 studies at the Montreal Heart Institute and externally validated on 4,249 studies from the University of California, San Francisco. DeepCORO-CLIP integrates multiple projections with attention-based pooling for study-level assessment across diagnostic, prognostic, and disease progression tasks. For significant stenosis detection, the model achieved an AUROC of 0.888 internally and 0.89 on external validation. Mean absolute error against core laboratory quantitative coronary angiography was 13.6%, lower than clinical reports at 19.0%. The model also performed strongly for chronic total occlusion, intracoronary thrombus, and coronary calcification detection. Transfer learning enabled prediction of one-year major adverse cardiovascular events with AUROC 0.79 and estimation of left ventricular ejection fraction with mean absolute error 7.3%. Embeddings also captured disease progression across serial examinations. With a mean inference time of 4.2 seconds in hospital deployment, DeepCORO-CLIP provides a foundation for automated coronary angiography interpretation at the point of care. Code, sample data, model weights, and deployment infrastructure are publicly released.
MAPLE: Elevating Medical Reasoning from Statistical Consensus to Process-Led Alignment
Mar 09, 2026Recent advances in medical large language models have explored Test-Time Reinforcement Learning (TTRL) to enhance reasoning. However, standard TTRL often relies on majority voting (MV) as a heuristic supervision signal, which can be unreliable in complex medical scenarios where the most frequent reasoning path is not necessarily the clinically correct one. In this work, we propose a novel and unified training paradigm that integrates medical process reward models with TTRL to bridge the gap between test-time scaling (TTS) and parametric model optimization. Specifically, we advance the TTRL framework by replacing the conventional MV with a fine-grained, expert-aligned supervision paradigm using Med-RPM. This integration ensures that reinforcement learning is guided by medical correctness rather than mere consensus, effectively distilling search-based intelligence into the model's parametric memory. Extensive evaluations on four different benchmarks have demonstrated that our developed method consistently and significantly outperforms current TTRL and standalone PRM selection. Our findings establish that transitioning from stochastic heuristics to structured, step-wise rewards is essential for developing reliable and scalable medical AI systems
CoMMa: Contribution-Aware Medical Multi-Agents From A Game-Theoretic Perspective
Feb 09, 2026Recent multi-agent frameworks have broadened the ability to tackle oncology decision support tasks that require reasoning over dynamic, heterogeneous patient data. We propose Contribution-Aware Medical Multi-Agents (CoMMa), a decentralized LLM-agent framework in which specialists operate on partitioned evidence and coordinate through a game-theoretic objective for robust decision-making. In contrast to most agent architectures relying on stochastic narrative-based reasoning, CoMMa utilizes deterministic embedding projections to approximate contribution-aware credit assignment. This yields explicit evidence attribution by estimating each agent's marginal utility, producing interpretable and mathematically grounded decision pathways with improved stability. Evaluated on diverse oncology benchmarks, including a real-world multidisciplinary tumor board dataset, CoMMa achieves higher accuracy and more stable performance than data-centralized and role-based multi-agents baselines.
PhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
Jan 22, 2026Modern foundational Multimodal Large Language Models (MLLMs) and video world models have advanced significantly in mathematical, common-sense, and visual reasoning, but their grasp of the underlying physics remains underexplored. Existing benchmarks attempting to measure this matter rely on synthetic, Visual Question Answer templates or focus on perceptual video quality that is tangential to measuring how well the video abides by physical laws. To address this fragmentation, we introduce PhysicsMind, a unified benchmark with both real and simulation environments that evaluates law-consistent reasoning and generation over three canonical principles: Center of Mass, Lever Equilibrium, and Newton's First Law. PhysicsMind comprises two main tasks: i) VQA tasks, testing whether models can reason and determine physical quantities and values from images or short videos, and ii) Video Generation(VG) tasks, evaluating if predicted motion trajectories obey the same center-of-mass, torque, and inertial constraints as the ground truth. A broad range of recent models and video generation models is evaluated on PhysicsMind and found to rely on appearance heuristics while often violating basic mechanics. These gaps indicate that current scaling and training are still insufficient for robust physical understanding, underscoring PhysicsMind as a focused testbed for physics-aware multimodal models. Our data will be released upon acceptance.
Forest Before Trees: Latent Superposition for Efficient Visual Reasoning
Jan 11, 2026While Chain-of-Thought empowers Large Vision-Language Models with multi-step reasoning, explicit textual rationales suffer from an information bandwidth bottleneck, where continuous visual details are discarded during discrete tokenization. Recent latent reasoning methods attempt to address this challenge, but often fall prey to premature semantic collapse due to rigid autoregressive objectives. In this paper, we propose Laser, a novel paradigm that reformulates visual deduction via Dynamic Windowed Alignment Learning (DWAL). Instead of forcing a point-wise prediction, Laser aligns the latent state with a dynamic validity window of future semantics. This mechanism enforces a "Forest-before-Trees" cognitive hierarchy, enabling the model to maintain a probabilistic superposition of global features before narrowing down to local details. Crucially, Laser maintains interpretability via decodable trajectories while stabilizing unconstrained learning via Self-Refined Superposition. Extensive experiments on 6 benchmarks demonstrate that Laser achieves state-of-the-art performance among latent reasoning methods, surpassing the strong baseline Monet by 5.03% on average. Notably, it achieves these gains with extreme efficiency, reducing inference tokens by more than 97%, while demonstrating robust generalization to out-of-distribution domains.
Adaptation of Agentic AI
Dec 22, 2025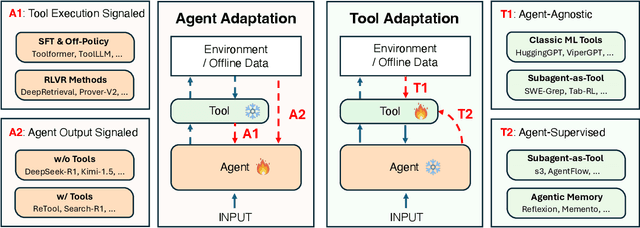
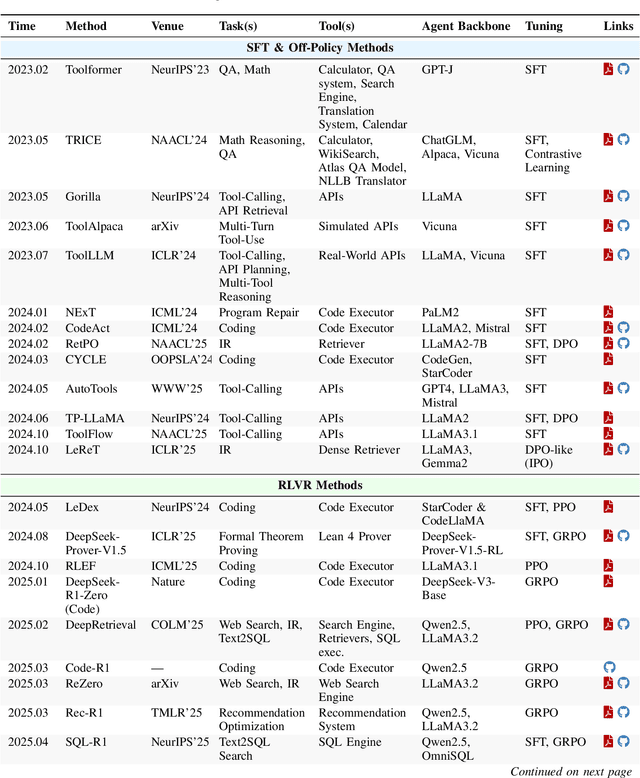
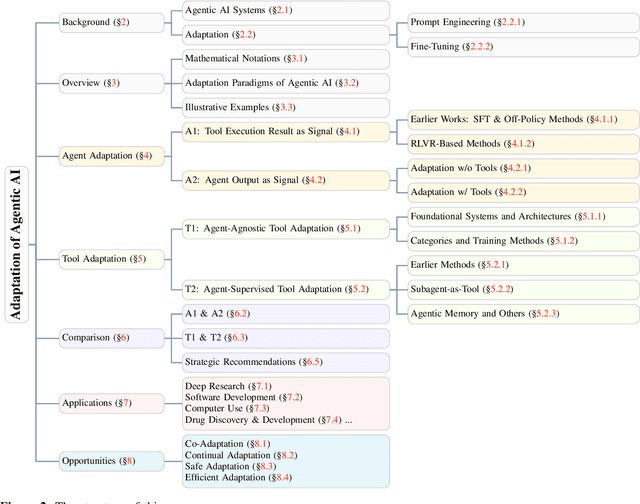
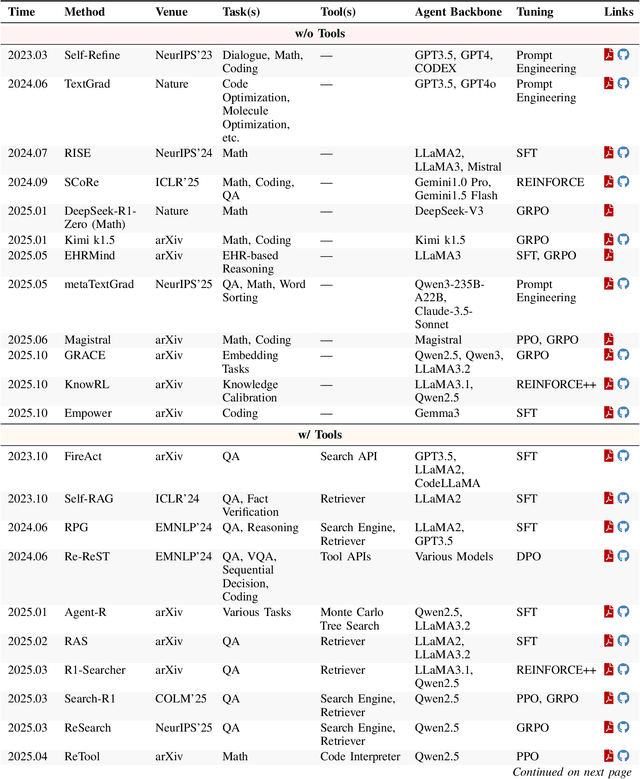
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Quantization Meets dLLMs: A Systematic Study of Post-training Quantization for Diffusion LLMs
Aug 20, 2025Recent advances in diffusion large language models (dLLMs) have introduced a promising alternative to autoregressive (AR) LLMs for natural language generation tasks, leveraging full attention and denoising-based decoding strategies. However, the deployment of these models on edge devices remains challenging due to their massive parameter scale and high resource demands. While post-training quantization (PTQ) has emerged as a widely adopted technique for compressing AR LLMs, its applicability to dLLMs remains largely unexplored. In this work, we present the first systematic study on quantizing diffusion-based language models. We begin by identifying the presence of activation outliers, characterized by abnormally large activation values that dominate the dynamic range. These outliers pose a key challenge to low-bit quantization, as they make it difficult to preserve precision for the majority of values. More importantly, we implement state-of-the-art PTQ methods and conduct a comprehensive evaluation across multiple task types and model variants. Our analysis is structured along four key dimensions: bit-width, quantization method, task category, and model type. Through this multi-perspective evaluation, we offer practical insights into the quantization behavior of dLLMs under different configurations. We hope our findings provide a foundation for future research in efficient dLLM deployment. All codes and experimental setups will be released to support the community.
Virtual Multiplex Staining for Histological Images using a Marker-wise Conditioned Diffusion Model
Aug 20, 2025Multiplex imaging is revolutionizing pathology by enabling the simultaneous visualization of multiple biomarkers within tissue samples, providing molecular-level insights that traditional hematoxylin and eosin (H&E) staining cannot provide. However, the complexity and cost of multiplex data acquisition have hindered its widespread adoption. Additionally, most existing large repositories of H&E images lack corresponding multiplex images, limiting opportunities for multimodal analysis. To address these challenges, we leverage recent advances in latent diffusion models (LDMs), which excel at modeling complex data distributions utilizing their powerful priors for fine-tuning to a target domain. In this paper, we introduce a novel framework for virtual multiplex staining that utilizes pretrained LDM parameters to generate multiplex images from H&E images using a conditional diffusion model. Our approach enables marker-by-marker generation by conditioning the diffusion model on each marker, while sharing the same architecture across all markers. To tackle the challenge of varying pixel value distributions across different marker stains and to improve inference speed, we fine-tune the model for single-step sampling, enhancing both color contrast fidelity and inference efficiency through pixel-level loss functions. We validate our framework on two publicly available datasets, notably demonstrating its effectiveness in generating up to 18 different marker types with improved accuracy, a substantial increase over the 2-3 marker types achieved in previous approaches. This validation highlights the potential of our framework, pioneering virtual multiplex staining. Finally, this paper bridges the gap between H&E and multiplex imaging, potentially enabling retrospective studies and large-scale analyses of existing H&E image repositories.
RadFabric: Agentic AI System with Reasoning Capability for Radiology
Jun 17, 2025Chest X ray (CXR) imaging remains a critical diagnostic tool for thoracic conditions, but current automated systems face limitations in pathology coverage, diagnostic accuracy, and integration of visual and textual reasoning. To address these gaps, we propose RadFabric, a multi agent, multimodal reasoning framework that unifies visual and textual analysis for comprehensive CXR interpretation. RadFabric is built on the Model Context Protocol (MCP), enabling modularity, interoperability, and scalability for seamless integration of new diagnostic agents. The system employs specialized CXR agents for pathology detection, an Anatomical Interpretation Agent to map visual findings to precise anatomical structures, and a Reasoning Agent powered by large multimodal reasoning models to synthesize visual, anatomical, and clinical data into transparent and evidence based diagnoses. RadFabric achieves significant performance improvements, with near-perfect detection of challenging pathologies like fractures (1.000 accuracy) and superior overall diagnostic accuracy (0.799) compared to traditional systems (0.229 to 0.527). By integrating cross modal feature alignment and preference-driven reasoning, RadFabric advances AI-driven radiology toward transparent, anatomically precise, and clinically actionable CXR analysis.