 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTAVG-Bench 2.0: Diagnosing Failure Modes of Cinematic Expressiveness in Multi-Talker Audio-Video Generation
May 27, 2026In recent years, Multi-Talker Audio-Video Generation (MTAVG) models have shown promising performance on fundamental metrics such as lip-sync and audio-visual alignment. However, these metrics remain insufficient for assessing cinematic expressiveness in scene-level generation. In multi-character scenes, generation models must go beyond audio-visual realism to convey coherent character performance and other higher-level cinematic qualities. To fill this gap, we introduce MTAVG-Bench 2.0, a benchmark for diagnosing failure modes of cinematic expressiveness in multi-talker audio-video generation. Unlike prior settings that mainly focus on the quality of basic multi-turn dialogue, MTAVG-Bench 2.0 targets short-drama and scene-level generation, and establishes a high-level failure taxonomy spanning acting, narrative, atmosphere, and audio-visual language. Based on this taxonomy, we construct more than 10,000 question-answering evaluation instances, together with subsets for short-drama-level assessment and temporal localization of failure modes, to systematically evaluate the ability of omni large language models to diagnose high-level audio-visual failures. Experimental results show that commercial omni models such as Gemini substantially outperform other evaluators, yet even the strongest models continue to struggle with complex failures in our benchmark. These results demonstrate that MTAVG-Bench 2.0 provides a systematic benchmark for failure diagnosis in cinematic multi-talker audio-video generation.
ShopSimulator: Evaluating and Exploring RL-Driven LLM Agent for Shopping Assistants
Jan 26, 2026Large language model (LLM)-based agents are increasingly deployed in e-commerce shopping. To perform thorough, user-tailored product searches, agents should interpret personal preferences, engage in multi-turn dialogues, and ultimately retrieve and discriminate among highly similar products. However, existing research has yet to provide a unified simulation environment that consistently captures all of these aspects, and always focuses solely on evaluation benchmarks without training support. In this paper, we introduce ShopSimulator, a large-scale and challenging Chinese shopping environment. Leveraging ShopSimulator, we evaluate LLMs across diverse scenarios, finding that even the best-performing models achieve less than 40% full-success rate. Error analysis reveals that agents struggle with deep search and product selection in long trajectories, fail to balance the use of personalization cues, and to effectively engage with users. Further training exploration provides practical guidance for overcoming these weaknesses, with the combination of supervised fine-tuning (SFT) and reinforcement learning (RL) yielding significant performance improvements. Code and data will be released at https://github.com/ShopAgent-Team/ShopSimulator.
Empowering All-in-Loop Health Management of Spacecraft Power System in the Mega-Constellation Era via Human-AI Collaboration
Jan 19, 2026It is foreseeable that the number of spacecraft will increase exponentially, ushering in an era dominated by satellite mega-constellations (SMC). This necessitates a focus on energy in space: spacecraft power systems (SPS), especially their health management (HM), given their role in power supply and high failure rates. Providing health management for dozens of SPS and for thousands of SPS represents two fundamentally different paradigms. Therefore, to adapt the health management in the SMC era, this work proposes a principle of aligning underlying capabilities (AUC principle) and develops SpaceHMchat, an open-source Human-AI collaboration (HAIC) framework for all-in-loop health management (AIL HM). SpaceHMchat serves across the entire loop of work condition recognition, anomaly detection, fault localization, and maintenance decision making, achieving goals such as conversational task completion, adaptive human-in-the-loop learning, personnel structure optimization, knowledge sharing, efficiency enhancement, as well as transparent reasoning and improved interpretability. Meanwhile, to validate this exploration, a hardware-realistic fault injection experimental platform is established, and its simulation model is built and open-sourced, both fully replicating the real SPS. The corresponding experimental results demonstrate that SpaceHMchat achieves excellent performance across 23 quantitative metrics, such as 100% conclusion accuracy in logical reasoning of work condition recognition, over 99% success rate in anomaly detection tool invocation, over 90% precision in fault localization, and knowledge base search time under 3 minutes in maintenance decision-making. Another contribution of this work is the release of the first-ever AIL HM dataset of SPS. This dataset contains four sub-datasets, involving 4 types of AIL HM sub-tasks, 17 types of faults, and over 700,000 timestamps.
GaussianDWM: 3D Gaussian Driving World Model for Unified Scene Understanding and Multi-Modal Generation
Dec 29, 2025Driving World Models (DWMs) have been developing rapidly with the advances of generative models. However, existing DWMs lack 3D scene understanding capabilities and can only generate content conditioned on input data, without the ability to interpret or reason about the driving environment. Moreover, current approaches represent 3D spatial information with point cloud or BEV features do not accurately align textual information with the underlying 3D scene. To address these limitations, we propose a novel unified DWM framework based on 3D Gaussian scene representation, which enables both 3D scene understanding and multi-modal scene generation, while also enabling contextual enrichment for understanding and generation tasks. Our approach directly aligns textual information with the 3D scene by embedding rich linguistic features into each Gaussian primitive, thereby achieving early modality alignment. In addition, we design a novel task-aware language-guided sampling strategy that removes redundant 3D Gaussians and injects accurate and compact 3D tokens into LLM. Furthermore, we design a dual-condition multi-modal generation model, where the information captured by our vision-language model is leveraged as a high-level language condition in combination with a low-level image condition, jointly guiding the multi-modal generation process. We conduct comprehensive studies on the nuScenes, and NuInteract datasets to validate the effectiveness of our framework. Our method achieves state-of-the-art performance. We will release the code publicly on GitHub https://github.com/dtc111111/GaussianDWM.
OmniDrive-R1: Reinforcement-driven Interleaved Multi-modal Chain-of-Thought for Trustworthy Vision-Language Autonomous Driving
Dec 16, 2025



The deployment of Vision-Language Models (VLMs) in safety-critical domains like autonomous driving (AD) is critically hindered by reliability failures, most notably object hallucination. This failure stems from their reliance on ungrounded, text-based Chain-of-Thought (CoT) reasoning.While existing multi-modal CoT approaches attempt mitigation, they suffer from two fundamental flaws: (1) decoupled perception and reasoning stages that prevent end-to-end joint optimization, and (2) reliance on expensive, dense localization labels.Thus we introduce OmniDrive-R1, an end-to-end VLM framework designed for autonomous driving, which unifies perception and reasoning through an interleaved Multi-modal Chain-of-Thought (iMCoT) mechanism. Our core innovation is an Reinforcement-driven visual grounding capability, enabling the model to autonomously direct its attention and "zoom in" on critical regions for fine-grained analysis. This capability is enabled by our pure two-stage reinforcement learning training pipeline and Clip-GRPO algorithm. Crucially, Clip-GRPO introduces an annotation-free, process-based grounding reward. This reward not only eliminates the need for dense labels but also circumvents the instability of external tool calls by enforcing real-time cross-modal consistency between the visual focus and the textual reasoning. Extensive experiments on DriveLMM-o1 demonstrate our model's significant improvements. Compared to the baseline Qwen2.5VL-7B, OmniDrive-R1 improves the overall reasoning score from 51.77% to 80.35%, and the final answer accuracy from 37.81% to 73.62%.
Atomic Norm Soft Thresholding for Sparse Time-frequency Representation
Jan 14, 2025Time-frequency (TF) representation of non-stationary signals typically requires the effective concentration of energy distribution along the instantaneous frequency (IF) ridge, which exhibits intrinsic sparsity. Inspired by the sparse optimization over continuum via atomic norm, a novel atomic norm soft thresholding for sparse TF representation (AST-STF) method is proposed, which ensures accurate TF localization under the strong duality. Numerical experiments demonstrate that the performance of the proposed method surpasses that of conventional methods.
Small Object Few-shot Segmentation for Vision-based Industrial Inspection
Jul 31, 2024
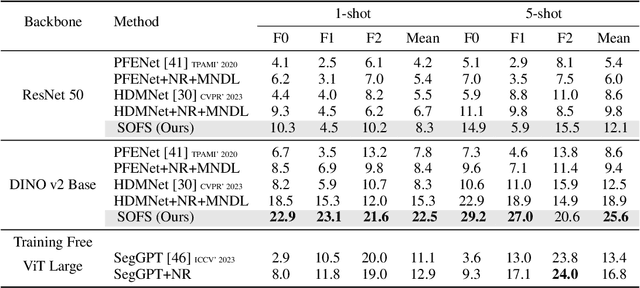
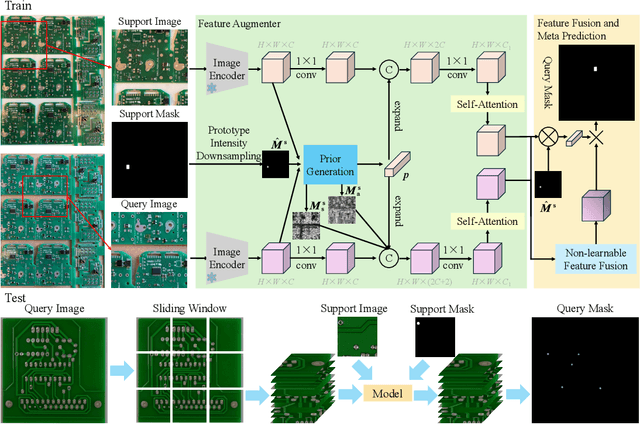
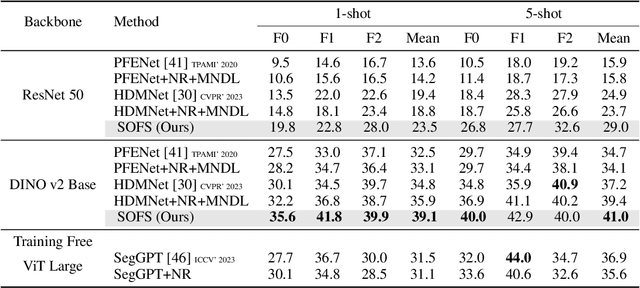
Vision-based industrial inspection (VII) aims to locate defects quickly and accurately. Supervised learning under a close-set setting and industrial anomaly detection, as two common paradigms in VII, face different problems in practical applications. The former is that various and sufficient defects are difficult to obtain, while the latter is that specific defects cannot be located. To solve these problems, in this paper, we focus on the few-shot semantic segmentation (FSS) method, which can locate unseen defects conditioned on a few annotations without retraining. Compared to common objects in natural images, the defects in VII are small. This brings two problems to current FSS methods: 1 distortion of target semantics and 2 many false positives for backgrounds. To alleviate these problems, we propose a small object few-shot segmentation (SOFS) model. The key idea for alleviating 1 is to avoid the resizing of the original image and correctly indicate the intensity of target semantics. SOFS achieves this idea via the non-resizing procedure and the prototype intensity downsampling of support annotations. To alleviate 2, we design an abnormal prior map in SOFS to guide the model to reduce false positives and propose a mixed normal Dice loss to preferentially prevent the model from predicting false positives. SOFS can achieve FSS and few-shot anomaly detection determined by support masks. Diverse experiments substantiate the superior performance of SOFS. Code is available at https://github.com/zhangzilongc/SOFS.
CA2: Class-Agnostic Adaptive Feature Adaptation for One-class Classification
Sep 04, 2023



One-class classification (OCC), i.e., identifying whether an example belongs to the same distribution as the training data, is essential for deploying machine learning models in the real world. Adapting the pre-trained features on the target dataset has proven to be a promising paradigm for improving OCC performance. Existing methods are constrained by assumptions about the number of classes. This contradicts the real scenario where the number of classes is unknown. In this work, we propose a simple class-agnostic adaptive feature adaptation method (CA2). We generalize the center-based method to unknown classes and optimize this objective based on the prior existing in the pre-trained network, i.e., pre-trained features that belong to the same class are adjacent. CA2 is validated to consistently improve OCC performance across a spectrum of training data classes, spanning from 1 to 1024, outperforming current state-of-the-art methods. Code is available at https://github.com/zhangzilongc/CA2.
A Novel Unsupervised Graph Wavelet Autoencoder for Mechanical System Fault Detection
Jul 20, 2023Reliable fault detection is an essential requirement for safe and efficient operation of complex mechanical systems in various industrial applications. Despite the abundance of existing approaches and the maturity of the fault detection research field, the interdependencies between condition monitoring data have often been overlooked. Recently, graph neural networks have been proposed as a solution for learning the interdependencies among data, and the graph autoencoder (GAE) architecture, similar to standard autoencoders, has gained widespread use in fault detection. However, both the GAE and the graph variational autoencoder (GVAE) have fixed receptive fields, limiting their ability to extract multiscale features and model performance. To overcome these limitations, we propose two graph neural network models: the graph wavelet autoencoder (GWAE), and the graph wavelet variational autoencoder (GWVAE). GWAE consists mainly of the spectral graph wavelet convolutional (SGWConv) encoder and a feature decoder, while GWVAE is the variational form of GWAE. The developed SGWConv is built upon the spectral graph wavelet transform which can realize multiscale feature extraction by decomposing the graph signal into one scaling function coefficient and several spectral graph wavelet coefficients. To achieve unsupervised mechanical system fault detection, we transform the collected system signals into PathGraph by considering the neighboring relationships of each data sample. Fault detection is then achieved by evaluating the reconstruction errors of normal and abnormal samples. We carried out experiments on two condition monitoring datasets collected from fuel control systems and one acoustic monitoring dataset from a valve. The results show that the proposed methods improve the performance by around 3%~4% compared to the comparison methods.
Industrial Anomaly Detection with Domain Shift: A Real-world Dataset and Masked Multi-scale Reconstruction
Apr 05, 2023



Industrial anomaly detection (IAD) is crucial for automating industrial quality inspection. The diversity of the datasets is the foundation for developing comprehensive IAD algorithms. Existing IAD datasets focus on the diversity of data categories, overlooking the diversity of domains within the same data category. In this paper, to bridge this gap, we propose the Aero-engine Blade Anomaly Detection (AeBAD) dataset, consisting of two sub-datasets: the single-blade dataset and the video anomaly detection dataset of blades. Compared to existing datasets, AeBAD has the following two characteristics: 1.) The target samples are not aligned and at different scales. 2.) There is a domain shift between the distribution of normal samples in the test set and the training set, where the domain shifts are mainly caused by the changes in illumination and view. Based on this dataset, we observe that current state-of-the-art (SOTA) IAD methods exhibit limitations when the domain of normal samples in the test set undergoes a shift. To address this issue, we propose a novel method called masked multi-scale reconstruction (MMR), which enhances the model's capacity to deduce causality among patches in normal samples by a masked reconstruction task. MMR achieves superior performance compared to SOTA methods on the AeBAD dataset. Furthermore, MMR achieves competitive performance with SOTA methods to detect the anomalies of different types on the MVTec AD dataset. Code and dataset are available at https://github.com/zhangzilongc/MMR.