 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilling the Gaps: Selective Knowledge Augmentation for LLM Recommenders
Apr 09, 2026Large language models (LLMs) have recently emerged as powerful training-free recommenders. However, their knowledge of individual items is inevitably uneven due to imbalanced information exposure during pretraining, a phenomenon we refer to as knowledge gap problem. To address this, most prior methods have employed a naive uniform augmentation that appends external information for every item in the input prompt. However, this approach not only wastes limited context budget on redundant augmentation for well-known items but can also hinder the model's effective reasoning. To this end, we propose KnowSA_CKP (Knowledge-aware Selective Augmentation with Comparative Knowledge Probing) to mitigate the knowledge gap problem. KnowSA_CKP estimates the LLM's internal knowledge by evaluating its capability to capture collaborative relationships and selectively injects additional information only where it is most needed. By avoiding unnecessary augmentation for well-known items, KnowSA_CKP focuses on items that benefit most from knowledge supplementation, thereby making more effective use of the context budget. KnowSA_CKP requires no fine-tuning step, and consistently improves both recommendation accuracy and context efficiency across four real-world datasets.
VLM2Rec: Resolving Modality Collapse in Vision-Language Model Embedders for Multimodal Sequential Recommendation
Mar 18, 2026Sequential Recommendation (SR) in multimodal settings typically relies on small frozen pretrained encoders, which limits semantic capacity and prevents Collaborative Filtering (CF) signals from being fully integrated into item representations. Inspired by the recent success of Large Language Models (LLMs) as high-capacity embedders, we investigate the use of Vision-Language Models (VLMs) as CF-aware multimodal encoders for SR. However, we find that standard contrastive supervised fine-tuning (SFT), which adapts VLMs for embedding generation and injects CF signals, can amplify its inherent modality collapse. In this state, optimization is dominated by a single modality while the other degrades, ultimately undermining recommendation accuracy. To address this, we propose VLM2Rec, a VLM embedder-based framework for multimodal sequential recommendation designed to ensure balanced modality utilization. Specifically, we introduce Weak-modality Penalized Contrastive Learning to rectify gradient imbalance during optimization and Cross-Modal Relational Topology Regularization to preserve geometric consistency between modalities. Extensive experiments demonstrate that VLM2Rec consistently outperforms state-of-the-art baselines in both accuracy and robustness across diverse scenarios.
Dynamic Multi-period Experts for Online Time Series Forecasting
Mar 10, 2026Online Time Series Forecasting (OTSF) requires models to continuously adapt to concept drift. However, existing methods often treat concept drift as a monolithic phenomenon. To address this limitation, we first redefine concept drift by categorizing it into two distinct types: Recurring Drift, where previously seen patterns reappear, and Emergent Drift, where entirely new patterns emerge. We then propose DynaME (Dynamic Multi-period Experts), a novel hybrid framework designed to effectively address this dual nature of drift. For Recurring Drift, DynaME employs a committee of specialized experts that are dynamically fitted to the most relevant historical periodic patterns at each time step. For Emergent Drift, the framework detects high-uncertainty scenarios and shifts reliance to a stable, general expert. Extensive experiments on several benchmark datasets and backbones demonstrate that DynaME effectively adapts to both concept drifts and significantly outperforms existing baselines.
Harmonic Dataset Distillation for Time Series Forecasting
Mar 04, 2026Time Series forecasting (TSF) in the modern era faces significant computational and storage cost challenges due to the massive scale of real-world data. Dataset Distillation (DD), a paradigm that synthesizes a small, compact dataset to achieve training performance comparable to that of the original dataset, has emerged as a promising solution. However, conventional DD methods are not tailored for time series and suffer from architectural overfitting and limited scalability. To address these issues, we propose Harmonic Dataset Distillation for Time Series Forecasting (HDT). HDT decomposes the time series into its sinusoidal basis through the FFT and aligns the core periodic structure by Harmonic Matching. Since this process operates in the frequency domain, all updates during distillation are applied globally without disrupting temporal dependencies of time series. Extensive experiments demonstrate that HDT achieves strong cross-architecture generalization and scalability, validating its practicality for large-scale, real-world applications.
COMPASS: A Framework for Evaluating Organization-Specific Policy Alignment in LLMs
Jan 05, 2026As large language models are deployed in high-stakes enterprise applications, from healthcare to finance, ensuring adherence to organization-specific policies has become essential. Yet existing safety evaluations focus exclusively on universal harms. We present COMPASS (Company/Organization Policy Alignment Assessment), the first systematic framework for evaluating whether LLMs comply with organizational allowlist and denylist policies. We apply COMPASS to eight diverse industry scenarios, generating and validating 5,920 queries that test both routine compliance and adversarial robustness through strategically designed edge cases. Evaluating seven state-of-the-art models, we uncover a fundamental asymmetry: models reliably handle legitimate requests (>95% accuracy) but catastrophically fail at enforcing prohibitions, refusing only 13-40% of adversarial denylist violations. These results demonstrate that current LLMs lack the robustness required for policy-critical deployments, establishing COMPASS as an essential evaluation framework for organizational AI safety.
Improving Scientific Document Retrieval with Academic Concept Index
Jan 02, 2026Adapting general-domain retrievers to scientific domains is challenging due to the scarcity of large-scale domain-specific relevance annotations and the substantial mismatch in vocabulary and information needs. Recent approaches address these issues through two independent directions that leverage large language models (LLMs): (1) generating synthetic queries for fine-tuning, and (2) generating auxiliary contexts to support relevance matching. However, both directions overlook the diverse academic concepts embedded within scientific documents, often producing redundant or conceptually narrow queries and contexts. To address this limitation, we introduce an academic concept index, which extracts key concepts from papers and organizes them guided by an academic taxonomy. This structured index serves as a foundation for improving both directions. First, we enhance the synthetic query generation with concept coverage-based generation (CCQGen), which adaptively conditions LLMs on uncovered concepts to generate complementary queries with broader concept coverage. Second, we strengthen the context augmentation with concept-focused auxiliary contexts (CCExpand), which leverages a set of document snippets that serve as concise responses to the concept-aware CCQGen queries. Extensive experiments show that incorporating the academic concept index into both query generation and context augmentation leads to higher-quality queries, better conceptual alignment, and improved retrieval performance.
Personalized Federated Recommendation With Knowledge Guidance
Nov 18, 2025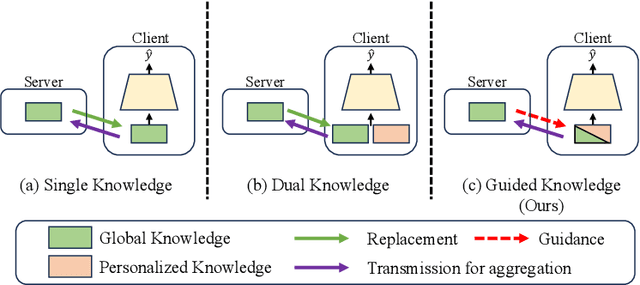


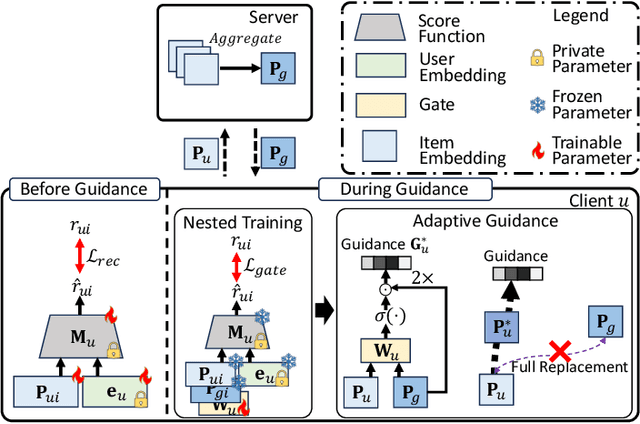
Federated Recommendation (FedRec) has emerged as a key paradigm for building privacy-preserving recommender systems. However, existing FedRec models face a critical dilemma: memory-efficient single-knowledge models suffer from a suboptimal knowledge replacement practice that discards valuable personalization, while high-performance dual-knowledge models are often too memory-intensive for practical on-device deployment. We propose Federated Recommendation with Knowledge Guidance (FedRKG), a model-agnostic framework that resolves this dilemma. The core principle, Knowledge Guidance, avoids full replacement and instead fuses global knowledge into preserved local embeddings, attaining the personalization benefits of dual-knowledge within a single-knowledge memory footprint. Furthermore, we introduce Adaptive Guidance, a fine-grained mechanism that dynamically modulates the intensity of this guidance for each user-item interaction, overcoming the limitations of static fusion methods. Extensive experiments on benchmark datasets demonstrate that FedRKG significantly outperforms state-of-the-art methods, validating the effectiveness of our approach. The code is available at https://github.com/Jaehyung-Lim/fedrkg.
MAP4TS: A Multi-Aspect Prompting Framework for Time-Series Forecasting with Large Language Models
Oct 27, 2025



Recent advances have investigated the use of pretrained large language models (LLMs) for time-series forecasting by aligning numerical inputs with LLM embedding spaces. However, existing multimodal approaches often overlook the distinct statistical properties and temporal dependencies that are fundamental to time-series data. To bridge this gap, we propose MAP4TS, a novel Multi-Aspect Prompting Framework that explicitly incorporates classical time-series analysis into the prompt design. Our framework introduces four specialized prompt components: a Global Domain Prompt that conveys dataset-level context, a Local Domain Prompt that encodes recent trends and series-specific behaviors, and a pair of Statistical and Temporal Prompts that embed handcrafted insights derived from autocorrelation (ACF), partial autocorrelation (PACF), and Fourier analysis. Multi-Aspect Prompts are combined with raw time-series embeddings and passed through a cross-modality alignment module to produce unified representations, which are then processed by an LLM and projected for final forecasting. Extensive experiments across eight diverse datasets show that MAP4TS consistently outperforms state-of-the-art LLM-based methods. Our ablation studies further reveal that prompt-aware designs significantly enhance performance stability and that GPT-2 backbones, when paired with structured prompts, outperform larger models like LLaMA in long-term forecasting tasks.
STEPER: Step-wise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models
Oct 09, 2025Answering complex real-world questions requires step-by-step retrieval and integration of relevant information to generate well-grounded responses. However, existing knowledge distillation methods overlook the need for different reasoning abilities at different steps, hindering transfer in multi-step retrieval-augmented frameworks. To address this, we propose Stepwise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models (StepER). StepER employs step-wise supervision to align with evolving information and reasoning demands across stages. Additionally, it incorporates difficulty-aware training to progressively optimize learning by prioritizing suitable steps. Our method is adaptable to various multi-step retrieval-augmented language models, including those that use retrieval queries for reasoning paths or decomposed questions. Extensive experiments show that StepER outperforms prior methods on multi-hop QA benchmarks, with an 8B model achieving performance comparable to a 70B teacher model.
Topic Coverage-based Demonstration Retrieval for In-Context Learning
Sep 15, 2025The effectiveness of in-context learning relies heavily on selecting demonstrations that provide all the necessary information for a given test input. To achieve this, it is crucial to identify and cover fine-grained knowledge requirements. However, prior methods often retrieve demonstrations based solely on embedding similarity or generation probability, resulting in irrelevant or redundant examples. In this paper, we propose TopicK, a topic coverage-based retrieval framework that selects demonstrations to comprehensively cover topic-level knowledge relevant to both the test input and the model. Specifically, TopicK estimates the topics required by the input and assesses the model's knowledge on those topics. TopicK then iteratively selects demonstrations that introduce previously uncovered required topics, in which the model exhibits low topical knowledge. We validate the effectiveness of TopicK through extensive experiments across various datasets and both open- and closed-source LLMs. Our source code is available at https://github.com/WonbinKweon/TopicK_EMNLP2025.