 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemote Sensing Image Intelligent Interpretation with the Language-Centered Perspective: Principles, Methods and Challenges
Aug 09, 2025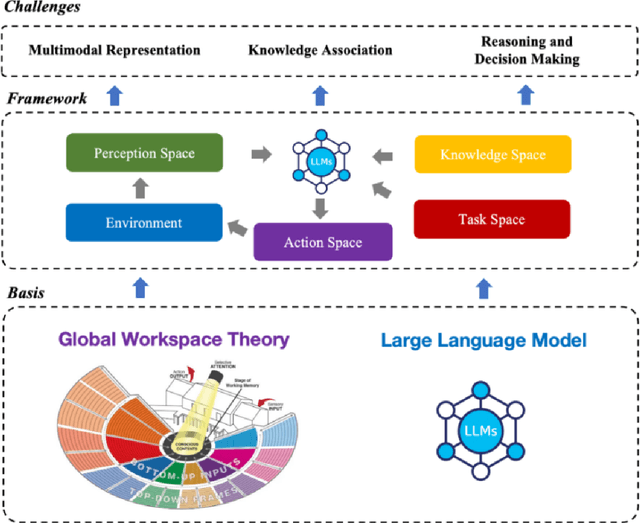
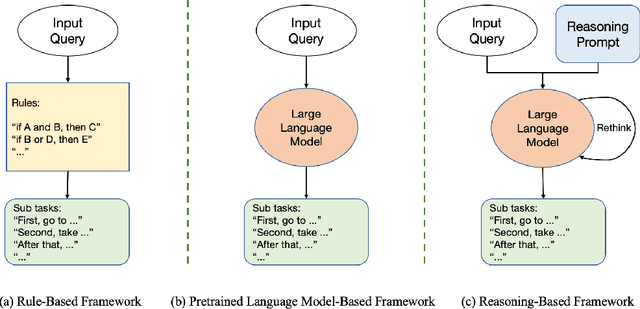
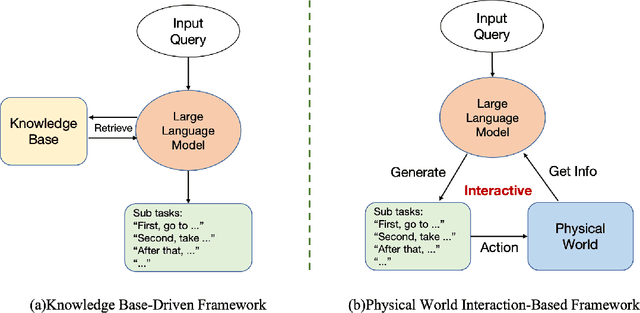
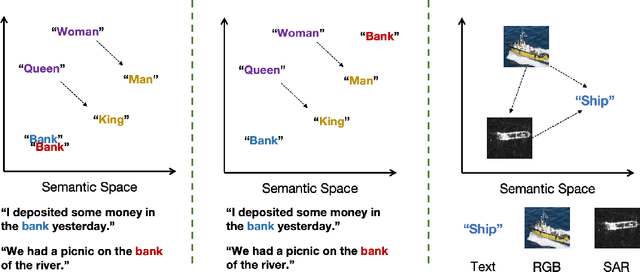
The mainstream paradigm of remote sensing image interpretation has long been dominated by vision-centered models, which rely on visual features for semantic understanding. However, these models face inherent limitations in handling multi-modal reasoning, semantic abstraction, and interactive decision-making. While recent advances have introduced Large Language Models (LLMs) into remote sensing workflows, existing studies primarily focus on downstream applications, lacking a unified theoretical framework that explains the cognitive role of language. This review advocates a paradigm shift from vision-centered to language-centered remote sensing interpretation. Drawing inspiration from the Global Workspace Theory (GWT) of human cognition, We propose a language-centered framework for remote sensing interpretation that treats LLMs as the cognitive central hub integrating perceptual, task, knowledge and action spaces to enable unified understanding, reasoning, and decision-making. We first explore the potential of LLMs as the central cognitive component in remote sensing interpretation, and then summarize core technical challenges, including unified multimodal representation, knowledge association, and reasoning and decision-making. Furthermore, we construct a global workspace-driven interpretation mechanism and review how language-centered solutions address each challenge. Finally, we outline future research directions from four perspectives: adaptive alignment of multimodal data, task understanding under dynamic knowledge constraints, trustworthy reasoning, and autonomous interaction. This work aims to provide a conceptual foundation for the next generation of remote sensing interpretation systems and establish a roadmap toward cognition-driven intelligent geospatial analysis.
Intention Enhanced Diffusion Model for Multimodal Pedestrian Trajectory Prediction
Aug 06, 2025



Predicting pedestrian motion trajectories is critical for path planning and motion control of autonomous vehicles. However, accurately forecasting crowd trajectories remains a challenging task due to the inherently multimodal and uncertain nature of human motion. Recent diffusion-based models have shown promising results in capturing the stochasticity of pedestrian behavior for trajectory prediction. However, few diffusion-based approaches explicitly incorporate the underlying motion intentions of pedestrians, which can limit the interpretability and precision of prediction models. In this work, we propose a diffusion-based multimodal trajectory prediction model that incorporates pedestrians' motion intentions into the prediction framework. The motion intentions are decomposed into lateral and longitudinal components, and a pedestrian intention recognition module is introduced to enable the model to effectively capture these intentions. Furthermore, we adopt an efficient guidance mechanism that facilitates the generation of interpretable trajectories. The proposed framework is evaluated on two widely used human trajectory prediction benchmarks, ETH and UCY, on which it is compared against state-of-the-art methods. The experimental results demonstrate that our method achieves competitive performance.
Generative molecule evolution using 3D pharmacophore for efficient Structure-Based Drug Design
Jul 27, 2025



Recent advances in generative models, particularly diffusion and auto-regressive models, have revolutionized fields like computer vision and natural language processing. However, their application to structure-based drug design (SBDD) remains limited due to critical data constraints. To address the limitation of training data for models targeting SBDD tasks, we propose an evolutionary framework named MEVO, which bridges the gap between billion-scale small molecule dataset and the scarce protein-ligand complex dataset, and effectively increase the abundance of training data for generative SBDD models. MEVO is composed of three key components: a high-fidelity VQ-VAE for molecule representation in latent space, a diffusion model for pharmacophore-guided molecule generation, and a pocket-aware evolutionary strategy for molecule optimization with physics-based scoring function. This framework efficiently generate high-affinity binders for various protein targets, validated with predicted binding affinities using free energy perturbation (FEP) methods. In addition, we showcase the capability of MEVO in designing potent inhibitors to KRAS$^{\textrm{G12D}}$, a challenging target in cancer therapeutics, with similar affinity to the known highly active inhibitor evaluated by FEP calculations. With high versatility and generalizability, MEVO offers an effective and data-efficient model for various tasks in structure-based ligand design.
From Coarse to Nuanced: Cross-Modal Alignment of Fine-Grained Linguistic Cues and Visual Salient Regions for Dynamic Emotion Recognition
Jul 16, 2025Dynamic Facial Expression Recognition (DFER) aims to identify human emotions from temporally evolving facial movements and plays a critical role in affective computing. While recent vision-language approaches have introduced semantic textual descriptions to guide expression recognition, existing methods still face two key limitations: they often underutilize the subtle emotional cues embedded in generated text, and they have yet to incorporate sufficiently effective mechanisms for filtering out facial dynamics that are irrelevant to emotional expression. To address these gaps, We propose GRACE, Granular Representation Alignment for Cross-modal Emotion recognition that integrates dynamic motion modeling, semantic text refinement, and token-level cross-modal alignment to facilitate the precise localization of emotionally salient spatiotemporal features. Our method constructs emotion-aware textual descriptions via a Coarse-to-fine Affective Text Enhancement (CATE) module and highlights expression-relevant facial motion through a motion-difference weighting mechanism. These refined semantic and visual signals are aligned at the token level using entropy-regularized optimal transport. Experiments on three benchmark datasets demonstrate that our method significantly improves recognition performance, particularly in challenging settings with ambiguous or imbalanced emotion classes, establishing new state-of-the-art (SOTA) results in terms of both UAR and WAR.
Joint Beamforming and Position Optimization for Fluid STAR-RIS-NOMA Assisted Wireless Communication Systems
Jul 09, 2025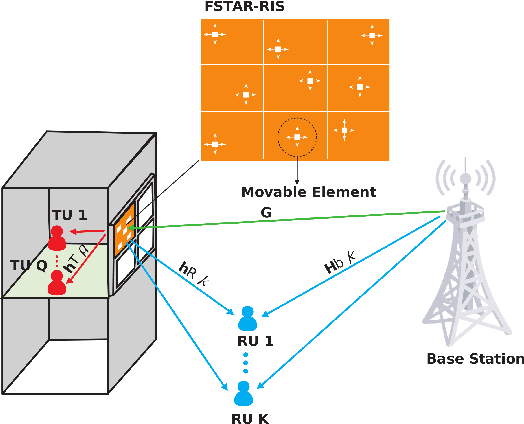
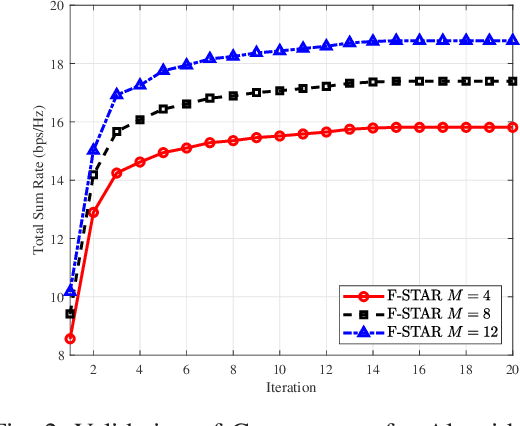
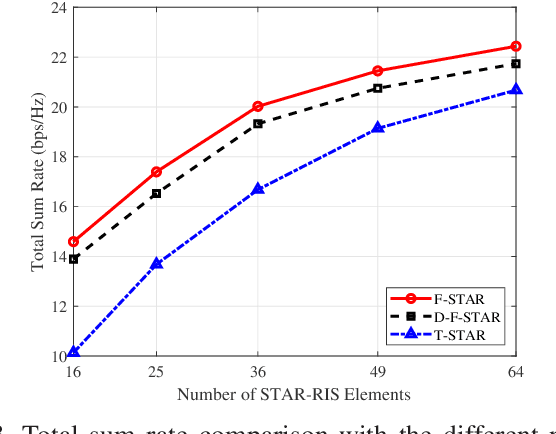
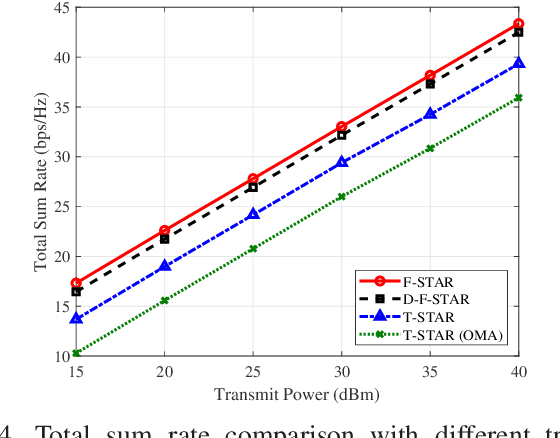
To address the limitations of traditional reconfigurable intelligent surfaces (RIS) in spatial control capability, this paper introduces the concept of the fluid antenna system (FAS) and proposes a fluid simultaneously transmitting and reflecting RIS (FSTAR-RIS) assisted non-orthogonal multiple access (NOMA) multi-user communication system. In this system, each FSTAR-RIS element is capable of flexible mobility and can dynamically adjust its position in response to environmental variations, thereby enabling simultaneous service to users in both the transmission and reflection zones. This significantly enhances the system's spatial degrees of freedom (DoF) and service adaptability. To maximize the system's weighted sum-rate, we formulate a non-convex optimization problem that jointly optimizes the base station beamforming, the transmission/reflection coefficients of the FSTAR-RIS, and the element positions. An alternating optimization (AO) algorithm is developed, incorporating successive convex approximation (SCA), semi-definite relaxation (SDR), and majorization-minimization (MM) techniques. In particular, to address the complex channel coupling introduced by the coexistence of direct and FSTAR-RIS paths, the MM framework is employed in the element position optimization subproblem, enabling an efficient iterative solution strategy. Simulation results validate that the proposed system achieves up to a 27% increase in total sum rate compared to traditional STAR-RIS systems and requires approximately 50% fewer RIS elements to attain the same performance, highlighting its effectiveness for cost-efficient large-scale deployment.
Bridging Data Gaps of Rare Conditions in ICU: A Multi-Disease Adaptation Approach for Clinical Prediction
Jul 08, 2025Artificial Intelligence has revolutionised critical care for common conditions. Yet, rare conditions in the intensive care unit (ICU), including recognised rare diseases and low-prevalence conditions in the ICU, remain underserved due to data scarcity and intra-condition heterogeneity. To bridge such gaps, we developed KnowRare, a domain adaptation-based deep learning framework for predicting clinical outcomes for rare conditions in the ICU. KnowRare mitigates data scarcity by initially learning condition-agnostic representations from diverse electronic health records through self-supervised pre-training. It addresses intra-condition heterogeneity by selectively adapting knowledge from clinically similar conditions with a developed condition knowledge graph. Evaluated on two ICU datasets across five clinical prediction tasks (90-day mortality, 30-day readmission, ICU mortality, remaining length of stay, and phenotyping), KnowRare consistently outperformed existing state-of-the-art models. Additionally, KnowRare demonstrated superior predictive performance compared to established ICU scoring systems, including APACHE IV and IV-a. Case studies further demonstrated KnowRare's flexibility in adapting its parameters to accommodate dataset-specific and task-specific characteristics, its generalisation to common conditions under limited data scenarios, and its rationality in selecting source conditions. These findings highlight KnowRare's potential as a robust and practical solution for supporting clinical decision-making and improving care for rare conditions in the ICU.
A Survey of Multi-sensor Fusion Perception for Embodied AI: Background, Methods, Challenges and Prospects
Jun 24, 2025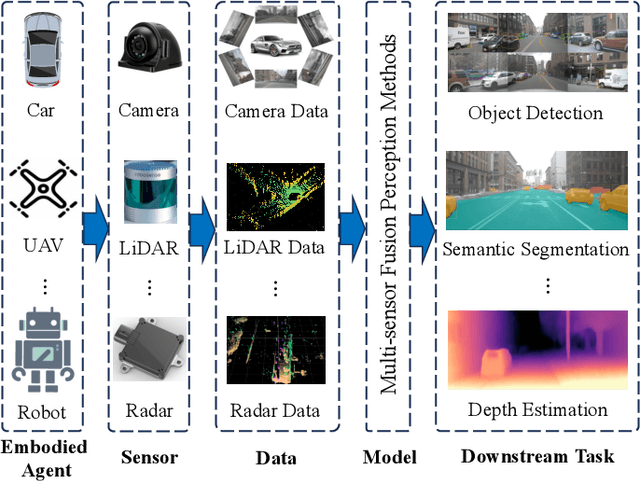
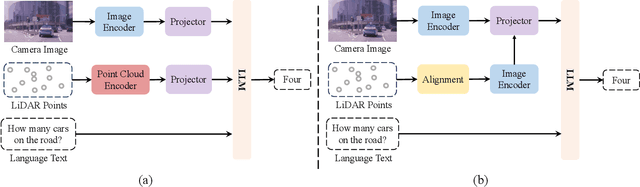
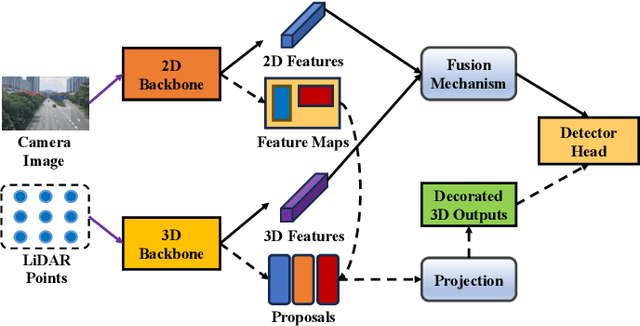
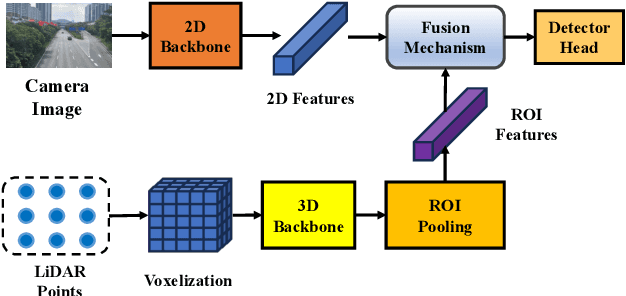
Multi-sensor fusion perception (MSFP) is a key technology for embodied AI, which can serve a variety of downstream tasks (e.g., 3D object detection and semantic segmentation) and application scenarios (e.g., autonomous driving and swarm robotics). Recently, impressive achievements on AI-based MSFP methods have been reviewed in relevant surveys. However, we observe that the existing surveys have some limitations after a rigorous and detailed investigation. For one thing, most surveys are oriented to a single task or research field, such as 3D object detection or autonomous driving. Therefore, researchers in other related tasks often find it difficult to benefit directly. For another, most surveys only introduce MSFP from a single perspective of multi-modal fusion, while lacking consideration of the diversity of MSFP methods, such as multi-view fusion and time-series fusion. To this end, in this paper, we hope to organize MSFP research from a task-agnostic perspective, where methods are reported from various technical views. Specifically, we first introduce the background of MSFP. Next, we review multi-modal and multi-agent fusion methods. A step further, time-series fusion methods are analyzed. In the era of LLM, we also investigate multimodal LLM fusion methods. Finally, we discuss open challenges and future directions for MSFP. We hope this survey can help researchers understand the important progress in MSFP and provide possible insights for future research.
Performance Analysis of OAMP Detection for ODDM Modulation in Satellite Communications
Jun 24, 2025

Towards future 6G wireless networks, low earth orbit (LEO) satellites have been widely considered as a promising component to enhance the terrestrial communications. To ensure the link reliability of high-mobility satellite communication scenarios, the emerging orthogonal delay-Doppler division multiplexing (ODDM) modulation has attracted significant research attention. In this paper, we study the diversity gain achieved by ODDM modulation along with the mathematical analysis and numerical simulations. Additionally, we propose an orthogonal approximate message passing (OAMP) algorithm based detector to harvest the diversity gain promised by ODDM modulation. By operating the linear and non-linear estimator iteratively, the orthogonal approximate message passing (OAMP) detector can utilize the sparsity of the effective delay-Doppler (DD) domain channel and extract the full diversity. Simulation results reveal the relationship between diversity gain and system parameters, and demonstrate that our proposed detector can achieve better performance than the conventional message passing methods with significantly reduced complexity.
A Gravity-informed Spatiotemporal Transformer for Human Activity Intensity Prediction
Jun 16, 2025Human activity intensity prediction is a crucial to many location-based services. Although tremendous progress has been made to model dynamic spatiotemporal patterns of human activity, most existing methods, including spatiotemporal graph neural networks (ST-GNNs), overlook physical constraints of spatial interactions and the over-smoothing phenomenon in spatial correlation modeling. To address these limitations, this work proposes a physics-informed deep learning framework, namely Gravity-informed Spatiotemporal Transformer (Gravityformer) by refining transformer attention to integrate the universal law of gravitation and explicitly incorporating constraints from spatial interactions. Specifically, it (1) estimates two spatially explicit mass parameters based on inflow and outflow, (2) models the likelihood of cross-unit interaction using closed-form solutions of spatial interactions to constrain spatial modeling randomness, and (3) utilizes the learned spatial interaction to guide and mitigate the over-smoothing phenomenon in transformer attention matrices. The underlying law of human activity can be explicitly modeled by the proposed adaptive gravity model. Moreover, a parallel spatiotemporal graph convolution transformer structure is proposed for achieving a balance between coupled spatial and temporal learning. Systematic experiments on six real-world large-scale activity datasets demonstrate the quantitative and qualitative superiority of our approach over state-of-the-art benchmarks. Additionally, the learned gravity attention matrix can be disentangled and interpreted based on geographical laws. This work provides a novel insight into integrating physical laws with deep learning for spatiotemporal predictive learning.
Towards Seamless Borders: A Method for Mitigating Inconsistencies in Image Inpainting and Outpainting
Jun 14, 2025Image inpainting is the task of reconstructing missing or damaged parts of an image in a way that seamlessly blends with the surrounding content. With the advent of advanced generative models, especially diffusion models and generative adversarial networks, inpainting has achieved remarkable improvements in visual quality and coherence. However, achieving seamless continuity remains a significant challenge. In this work, we propose two novel methods to address discrepancy issues in diffusion-based inpainting models. First, we introduce a modified Variational Autoencoder that corrects color imbalances, ensuring that the final inpainted results are free of color mismatches. Second, we propose a two-step training strategy that improves the blending of generated and existing image content during the diffusion process. Through extensive experiments, we demonstrate that our methods effectively reduce discontinuity and produce high-quality inpainting results that are coherent and visually appealing.