 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiGSP:Implicit Gradient Subspace Projection for Efficient Continual Learning of Vision-Language Models
May 19, 2026Vision-Language Models require efficient adaptation to continually emerging downstream tasks. While Parameter-Efficient Fine-Tuning mitigates catastrophic forgetting, assigning isolated modules per task leads to parameter explosion. Conversely, recent similarity-driven sharing mechanisms falsely equate superficial visual similarity with underlying alignment consistency. This fundamental mismatch triggers severe negative transfer between visually similar but logically distinct tasks and fails to exploit alignment reuse across visually diverse ones. We argue thatalignment sharing is fundamentally a geometric problem of overlapping optimization trajectories within shared low-rank subspaces. Grounded in this insight, we propose iGSP, a novel framework that achieves efficient adaptation via implicit gradient subspace projection. Leveraging the early convergence of MoE routers to establish the subspace basis, iGSP bifurcates the adaptation process into two phases. First, the Subspace Identification phase introduces candidate experts via basis pre-expansion, applies a novel subspace-constrained regularization to implicitly project new task gradients onto the historical subspace, and precisely prunes redundant dimensions by treating routing probabilities as gradient flow indicators, ultimately to maximize knowledge reuse. Second, the Orthogonal Subspace Fine-Tuning phase fixes this structural basis and removes the regularization to rapidly fit the task-specific residual loss. Extensive experiments on the MTIL benchmark demonstrate that iGSP achieves state-of-the-art accuracy while significantly improving training efficiency, reducing the average trainable parameters by 42.7\% compared to current SOTA methods, and decreasing the final total parameters by 86.9\% relative to counterparts. The source code is available at https://github.com/GeoX-Lab/iGSP.
The Wittgensteinian Representation Hypothesis: Is Language the Attractor of Multimodal Convergence?
May 10, 2026Understanding why independently trained neural networks from different modalities converge toward shared representations, and where this convergence leads, remains an open question in representation learning. All existing evidence relies on symmetric similarity measures, which can detect convergence but are structurally blind to its direction. We introduce directional convergence analysis using cycle-kNN, an asymmetric alignment measure, applied across dozens of independently trained unimodal models spanning point clouds, vision, and language. We uncover a consistent directional asymmetry: non-language modalities move toward the neighborhood structure of language significantly more than the reverse, and this pattern holds across all model families and scales--yet is entirely invisible to symmetric measures. Mechanistic analysis traces the directionality to feature density asymmetry, whereby language representations occupy the most compact regions of representational space. The Information Bottleneck framework provides a principled interpretation: optimization under compression drives representations toward discrete, compositional structures characteristic of language. We formalize this as the Wittgensteinian Representation Hypothesis: the semantic structure of language is the asymptotic attractor of multimodal representation convergence.
Towards Accurate UAV Image Perception: Guiding Vision-Language Models with Stronger Task Prompts
Dec 08, 2025



Existing image perception methods based on VLMs generally follow a paradigm wherein models extract and analyze image content based on user-provided textual task prompts. However, such methods face limitations when applied to UAV imagery, which presents challenges like target confusion, scale variations, and complex backgrounds. These challenges arise because VLMs' understanding of image content depends on the semantic alignment between visual and textual tokens. When the task prompt is simplistic and the image content is complex, achieving effective alignment becomes difficult, limiting the model's ability to focus on task-relevant information. To address this issue, we introduce AerialVP, the first agent framework for task prompt enhancement in UAV image perception. AerialVP proactively extracts multi-dimensional auxiliary information from UAV images to enhance task prompts, overcoming the limitations of traditional VLM-based approaches. Specifically, the enhancement process includes three stages: (1) analyzing the task prompt to identify the task type and enhancement needs, (2) selecting appropriate tools from the tool repository, and (3) generating enhanced task prompts based on the analysis and selected tools. To evaluate AerialVP, we introduce AerialSense, a comprehensive benchmark for UAV image perception that includes Aerial Visual Reasoning, Aerial Visual Question Answering, and Aerial Visual Grounding tasks. AerialSense provides a standardized basis for evaluating model generalization and performance across diverse resolutions, lighting conditions, and both urban and natural scenes. Experimental results demonstrate that AerialVP significantly enhances task prompt guidance, leading to stable and substantial performance improvements in both open-source and proprietary VLMs. Our work will be available at https://github.com/lostwolves/AerialVP.
Remote Sensing Image Intelligent Interpretation with the Language-Centered Perspective: Principles, Methods and Challenges
Aug 09, 2025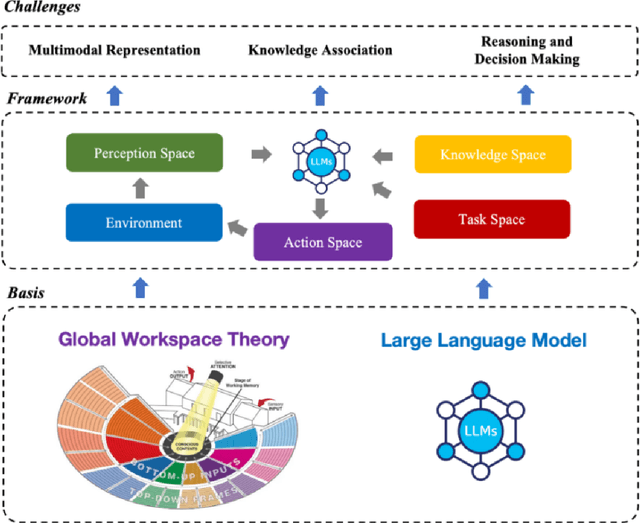
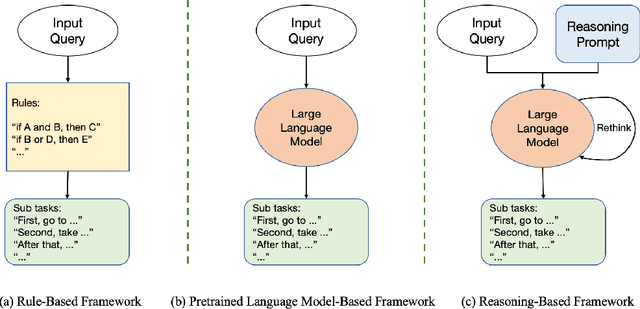
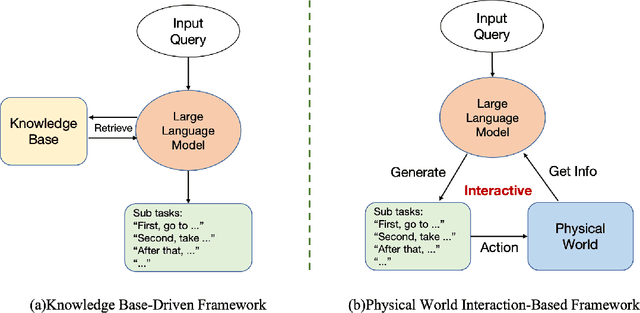
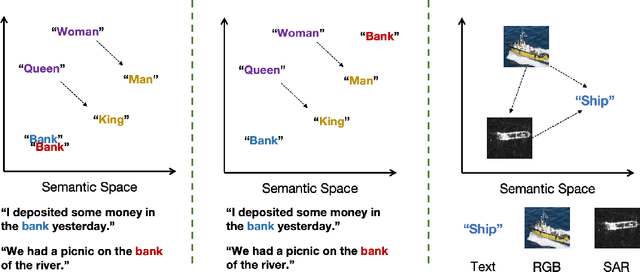
The mainstream paradigm of remote sensing image interpretation has long been dominated by vision-centered models, which rely on visual features for semantic understanding. However, these models face inherent limitations in handling multi-modal reasoning, semantic abstraction, and interactive decision-making. While recent advances have introduced Large Language Models (LLMs) into remote sensing workflows, existing studies primarily focus on downstream applications, lacking a unified theoretical framework that explains the cognitive role of language. This review advocates a paradigm shift from vision-centered to language-centered remote sensing interpretation. Drawing inspiration from the Global Workspace Theory (GWT) of human cognition, We propose a language-centered framework for remote sensing interpretation that treats LLMs as the cognitive central hub integrating perceptual, task, knowledge and action spaces to enable unified understanding, reasoning, and decision-making. We first explore the potential of LLMs as the central cognitive component in remote sensing interpretation, and then summarize core technical challenges, including unified multimodal representation, knowledge association, and reasoning and decision-making. Furthermore, we construct a global workspace-driven interpretation mechanism and review how language-centered solutions address each challenge. Finally, we outline future research directions from four perspectives: adaptive alignment of multimodal data, task understanding under dynamic knowledge constraints, trustworthy reasoning, and autonomous interaction. This work aims to provide a conceptual foundation for the next generation of remote sensing interpretation systems and establish a roadmap toward cognition-driven intelligent geospatial analysis.
A Gift from the Integration of Discriminative and Diffusion-based Generative Learning: Boundary Refinement Remote Sensing Semantic Segmentation
Jul 02, 2025



Remote sensing semantic segmentation must address both what the ground objects are within an image and where they are located. Consequently, segmentation models must ensure not only the semantic correctness of large-scale patches (low-frequency information) but also the precise localization of boundaries between patches (high-frequency information). However, most existing approaches rely heavily on discriminative learning, which excels at capturing low-frequency features, while overlooking its inherent limitations in learning high-frequency features for semantic segmentation. Recent studies have revealed that diffusion generative models excel at generating high-frequency details. Our theoretical analysis confirms that the diffusion denoising process significantly enhances the model's ability to learn high-frequency features; however, we also observe that these models exhibit insufficient semantic inference for low-frequency features when guided solely by the original image. Therefore, we integrate the strengths of both discriminative and generative learning, proposing the Integration of Discriminative and diffusion-based Generative learning for Boundary Refinement (IDGBR) framework. The framework first generates a coarse segmentation map using a discriminative backbone model. This map and the original image are fed into a conditioning guidance network to jointly learn a guidance representation subsequently leveraged by an iterative denoising diffusion process refining the coarse segmentation. Extensive experiments across five remote sensing semantic segmentation datasets (binary and multi-class segmentation) confirm our framework's capability of consistent boundary refinement for coarse results from diverse discriminative architectures. The source code will be available at https://github.com/KeyanHu-git/IDGBR.
A Joint Learning Framework with Feature Reconstruction and Prediction for Incomplete Satellite Image Time Series in Agricultural Semantic Segmentation
May 25, 2025



Satellite Image Time Series (SITS) is crucial for agricultural semantic segmentation. However, Cloud contamination introduces time gaps in SITS, disrupting temporal dependencies and causing feature shifts, leading to degraded performance of models trained on complete SITS. Existing methods typically address this by reconstructing the entire SITS before prediction or using data augmentation to simulate missing data. Yet, full reconstruction may introduce noise and redundancy, while the data-augmented model can only handle limited missing patterns, leading to poor generalization. We propose a joint learning framework with feature reconstruction and prediction to address incomplete SITS more effectively. During training, we simulate data-missing scenarios using temporal masks. The two tasks are guided by both ground-truth labels and the teacher model trained on complete SITS. The prediction task constrains the model from selectively reconstructing critical features from masked inputs that align with the teacher's temporal feature representations. It reduces unnecessary reconstruction and limits noise propagation. By integrating reconstructed features into the prediction task, the model avoids learning shortcuts and maintains its ability to handle varied missing patterns and complete SITS. Experiments on SITS from Hunan Province, Western France, and Catalonia show that our method improves mean F1-scores by 6.93% in cropland extraction and 7.09% in crop classification over baselines. It also generalizes well across satellite sensors, including Sentinel-2 and PlanetScope, under varying temporal missing rates and model backbones.
BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs
May 23, 2025



With the rapid advancement of low-altitude remote sensing and Vision-Language Models (VLMs), Embodied Agents based on Unmanned Aerial Vehicles (UAVs) have shown significant potential in autonomous tasks. However, current evaluation methods for UAV-Embodied Agents (UAV-EAs) remain constrained by the lack of standardized benchmarks, diverse testing scenarios and open system interfaces. To address these challenges, we propose BEDI (Benchmark for Embodied Drone Intelligence), a systematic and standardized benchmark designed for evaluating UAV-EAs. Specifically, we introduce a novel Dynamic Chain-of-Embodied-Task paradigm based on the perception-decision-action loop, which decomposes complex UAV tasks into standardized, measurable subtasks. Building on this paradigm, we design a unified evaluation framework encompassing five core sub-skills: semantic perception, spatial perception, motion control, tool utilization, and task planning. Furthermore, we construct a hybrid testing platform that integrates static real-world environments with dynamic virtual scenarios, enabling comprehensive performance assessment of UAV-EAs across varied contexts. The platform also offers open and standardized interfaces, allowing researchers to customize tasks and extend scenarios, thereby enhancing flexibility and scalability in the evaluation process. Finally, through empirical evaluations of several state-of-the-art (SOTA) VLMs, we reveal their limitations in embodied UAV tasks, underscoring the critical role of the BEDI benchmark in advancing embodied intelligence research and model optimization. By filling the gap in systematic and standardized evaluation within this field, BEDI facilitates objective model comparison and lays a robust foundation for future development in this field. Our benchmark will be released at https://github.com/lostwolves/BEDI .
A large-scale image-text dataset benchmark for farmland segmentation
Mar 29, 2025



The traditional deep learning paradigm that solely relies on labeled data has limitations in representing the spatial relationships between farmland elements and the surrounding environment.It struggles to effectively model the dynamic temporal evolution and spatial heterogeneity of farmland. Language,as a structured knowledge carrier,can explicitly express the spatiotemporal characteristics of farmland, such as its shape, distribution,and surrounding environmental information.Therefore,a language-driven learning paradigm can effectively alleviate the challenges posed by the spatiotemporal heterogeneity of farmland.However,in the field of remote sensing imagery of farmland,there is currently no comprehensive benchmark dataset to support this research direction.To fill this gap,we introduced language based descriptions of farmland and developed FarmSeg-VL dataset,the first fine-grained image-text dataset designed for spatiotemporal farmland segmentation.Firstly, this article proposed a semi-automatic annotation method that can accurately assign caption to each image, ensuring high data quality and semantic richness while improving the efficiency of dataset construction.Secondly,the FarmSeg-VL exhibits significant spatiotemporal characteristics.In terms of the temporal dimension,it covers all four seasons.In terms of the spatial dimension,it covers eight typical agricultural regions across China.In addition, in terms of captions,FarmSeg-VL covers rich spatiotemporal characteristics of farmland,including its inherent properties,phenological characteristics, spatial distribution,topographic and geomorphic features,and the distribution of surrounding environments.Finally,we present a performance analysis of VLMs and the deep learning models that rely solely on labels trained on the FarmSeg-VL,demonstrating its potential as a standard benchmark for farmland segmentation.
MEET: A Million-Scale Dataset for Fine-Grained Geospatial Scene Classification with Zoom-Free Remote Sensing Imagery
Mar 14, 2025Accurate fine-grained geospatial scene classification using remote sensing imagery is essential for a wide range of applications. However, existing approaches often rely on manually zooming remote sensing images at different scales to create typical scene samples. This approach fails to adequately support the fixed-resolution image interpretation requirements in real-world scenarios. To address this limitation, we introduce the Million-scale finE-grained geospatial scEne classification dataseT (MEET), which contains over 1.03 million zoom-free remote sensing scene samples, manually annotated into 80 fine-grained categories. In MEET, each scene sample follows a scene-inscene layout, where the central scene serves as the reference, and auxiliary scenes provide crucial spatial context for finegrained classification. Moreover, to tackle the emerging challenge of scene-in-scene classification, we present the Context-Aware Transformer (CAT), a model specifically designed for this task, which adaptively fuses spatial context to accurately classify the scene samples. CAT adaptively fuses spatial context to accurately classify the scene samples by learning attentional features that capture the relationships between the center and auxiliary scenes. Based on MEET, we establish a comprehensive benchmark for fine-grained geospatial scene classification, evaluating CAT against 11 competitive baselines. The results demonstrate that CAT significantly outperforms these baselines, achieving a 1.88% higher balanced accuracy (BA) with the Swin-Large backbone, and a notable 7.87% improvement with the Swin-Huge backbone. Further experiments validate the effectiveness of each module in CAT and show the practical applicability of CAT in the urban functional zone mapping. The source code and dataset will be publicly available at https://jerrywyn.github.io/project/MEET.html.
Enhancing Scene Classification in Cloudy Image Scenarios: A Collaborative Transfer Method with Information Regulation Mechanism using Optical Cloud-Covered and SAR Remote Sensing Images
Jan 08, 2025



In remote sensing scene classification, leveraging the transfer methods with well-trained optical models is an efficient way to overcome label scarcity. However, cloud contamination leads to optical information loss and significant impacts on feature distribution, challenging the reliability and stability of transferred target models. Common solutions include cloud removal for optical data or directly using Synthetic aperture radar (SAR) data in the target domain. However, cloud removal requires substantial auxiliary data for support and pre-training, while directly using SAR disregards the unobstructed portions of optical data. This study presents a scene classification transfer method that synergistically combines multi-modality data, which aims to transfer the source domain model trained on cloudfree optical data to the target domain that includes both cloudy optical and SAR data at low cost. Specifically, the framework incorporates two parts: (1) the collaborative transfer strategy, based on knowledge distillation, enables the efficient prior knowledge transfer across heterogeneous data; (2) the information regulation mechanism (IRM) is proposed to address the modality imbalance issue during transfer. It employs auxiliary models to measure the contribution discrepancy of each modality, and automatically balances the information utilization of modalities during the target model learning process at the sample-level. The transfer experiments were conducted on simulated and real cloud datasets, demonstrating the superior performance of the proposed method compared to other solutions in cloud-covered scenarios. We also verified the importance and limitations of IRM, and further discussed and visualized the modality imbalance problem during the model transfer. Codes are available at https://github.com/wangyuze-csu/ESCCS