 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStubborn: A Streamlined and Unified Reinforcement Learning Framework for Robust Motion Tracking and Fall Recovery for Humanoids
Jun 11, 2026Recent reinforcement learning approaches have shown great promise in improving humanoid motion tracking performance and achieving fall recovery under disturbances. However, most existing works treat motion tracking and fall recovery as different tasks and require multi-stage training with specialized recovery rewards and/or separate recovery policies. Moreover, existing reinforcement learning-based methods often terminate training episodes immediately after severe tracking failures, limiting recovery-oriented exploration in unstable or fallen states. To address the above issues, we propose Stubborn, a streamlined and unified reinforcement learning framework to achieve robust humanoid motion tracking and fall recovery. Specifically, Stubborn uses an asymmetric Actor-Critic architecture and consists of three major components. First, a yaw-aligned tracking representation is adopted to reduce sensitivity to global drift and heading disturbances while preserving gravity-related balance information. Second, we introduce a Bernoulli-based probabilistic termination mechanism that enables the policy to encourage exploration of fall-recovery behaviors under varying failure modes. Third, we propose a probabilistic termination and tracking-error-driven strategy that dynamically reshapes the sampling distribution based on tracking performance, increasing the training efficiency for difficult motion segments and unstable states. Extensive comparisons with SOTA methods and ablation studies show that Stubborn achieved competitive performance, and the proposed probabilistic termination mechanism and adaptive sampling strategy contributed to the performance and robustness gains. For real-world demonstrations, please refer to https://aislab-sustech.github.io/Stubborn/.
MUSCLE-NET: Predicted-Multiscale-Aware Network for Pedestrian Trajectory Forecasting
May 30, 2026Accurate pedestrian trajectory prediction is essential for safe navigation in autonomous driving and intelligent transportation systems. Despite substantial progress made by recent methods, most existing approaches are limited in fully exploiting diverse observations and often overlook the scale dependency of future motion, treating multiscale features uniformly regardless of underlying motion dynamics. This limits their robustness across diverse pedestrian behaviors. To address these challenges, we propose a Predicted-MUltiSCale-Aware Network (MUSCLE-NET) for Pedestrian Trajectory Forecasting that integrates complementary multimodal cues with scale-adaptive prediction mechanisms. The proposed framework is built upon a Multiscale Multimodal Feature Extraction (MMFE) module, which combines multiscale representation, modality-aware recalibration, and directional cross-modal fusion to construct semantically aligned representations from bounding boxes, velocities, and pose information. Building on these features, a Multiscale Enhanced Hierarchical Prediction (MEHP) module performs prediction-aware future-motion refinement via a probabilistic coarse predictor, scale-aligned fusion, and progressive refinement, adaptively selecting scale-relevant cues to mitigate spatial drift. Extensive experiments on the JAAD and PIE benchmarks demonstrate that the proposed MUSCLE-Net achieves competitive performance and consistent gains compared with state-of-the-art trajectory prediction methods.
ASAP: An Azimuth-Priority Strip-Based Search Approach to Planar Microphone Array DOA Estimation in 3D
Apr 28, 2026Direction-of-arrival (DOA) estimation is an important task in microphone array processing and many downstream applications. The steered response power with phase transform (SRP-PHAT) method has been widely adopted for DOA estimation in recent years. However, accurate SRP-PHAT estimation in 3D scenarios requires evaluating steering responses over thousands of candidate directions, severely limiting real-time performance on resource-constrained platforms. This challenge becomes even more critical for planar arrays, which are widely used in robotics due to their structural simplicity. Motivated by the fact that azimuth estimation is usually more reliable than elevation estimation for most arrays, we propose ASAP, an azimuth-priority strip-based search approach to planar microphone array DOA estimation in 3D. In the first stage, ASAP performs coarse-to-fine region contraction within azimuthal strips to lock azimuth angles while retaining multiple maxima through spherical caps. In the second stage, it refines elevation along the great-circle arc between two close candidates. Extensive simulations and real-world experiments validate the efficiency and merits of the proposed method over existing approaches.
GSM-GS: Geometry-Constrained Single and Multi-view Gaussian Splatting for Surface Reconstruction
Feb 13, 2026Recently, 3D Gaussian Splatting has emerged as a prominent research direction owing to its ultrarapid training speed and high-fidelity rendering capabilities. However, the unstructured and irregular nature of Gaussian point clouds poses challenges to reconstruction accuracy. This limitation frequently causes high-frequency detail loss in complex surface microstructures when relying solely on routine strategies. To address this limitation, we propose GSM-GS: a synergistic optimization framework integrating single-view adaptive sub-region weighting constraints and multi-view spatial structure refinement. For single-view optimization, we leverage image gradient features to partition scenes into texture-rich and texture-less sub-regions. The reconstruction quality is enhanced through adaptive filtering mechanisms guided by depth discrepancy features. This preserves high-weight regions while implementing a dual-branch constraint strategy tailored to regional texture variations, thereby improving geometric detail characterization. For multi-view optimization, we introduce a geometry-guided cross-view point cloud association method combined with a dynamic weight sampling strategy. This constructs 3D structural normal constraints across adjacent point cloud frames, effectively reinforcing multi-view consistency and reconstruction fidelity. Extensive experiments on public datasets demonstrate that our method achieves both competitive rendering quality and geometric reconstruction. See our interactive project page
Pentest-R1: Towards Autonomous Penetration Testing Reasoning Optimized via Two-Stage Reinforcement Learning
Aug 10, 2025Automating penetration testing is crucial for enhancing cybersecurity, yet current Large Language Models (LLMs) face significant limitations in this domain, including poor error handling, inefficient reasoning, and an inability to perform complex end-to-end tasks autonomously. To address these challenges, we introduce Pentest-R1, a novel framework designed to optimize LLM reasoning capabilities for this task through a two-stage reinforcement learning pipeline. We first construct a dataset of over 500 real-world, multi-step walkthroughs, which Pentest-R1 leverages for offline reinforcement learning (RL) to instill foundational attack logic. Subsequently, the LLM is fine-tuned via online RL in an interactive Capture The Flag (CTF) environment, where it learns directly from environmental feedback to develop robust error self-correction and adaptive strategies. Our extensive experiments on the Cybench and AutoPenBench benchmarks demonstrate the framework's effectiveness. On AutoPenBench, Pentest-R1 achieves a 24.2\% success rate, surpassing most state-of-the-art models and ranking second only to Gemini 2.5 Flash. On Cybench, it attains a 15.0\% success rate in unguided tasks, establishing a new state-of-the-art for open-source LLMs and matching the performance of top proprietary models. Ablation studies confirm that the synergy of both training stages is critical to its success.
Intention-Aware Diffusion Model for Pedestrian Trajectory Prediction
Aug 10, 2025



Predicting pedestrian motion trajectories is critical for the path planning and motion control of autonomous vehicles. Recent diffusion-based models have shown promising results in capturing the inherent stochasticity of pedestrian behavior for trajectory prediction. However, the absence of explicit semantic modelling of pedestrian intent in many diffusion-based methods may result in misinterpreted behaviors and reduced prediction accuracy. To address the above challenges, we propose a diffusion-based pedestrian trajectory prediction framework that incorporates both short-term and long-term motion intentions. Short-term intent is modelled using a residual polar representation, which decouples direction and magnitude to capture fine-grained local motion patterns. Long-term intent is estimated through a learnable, token-based endpoint predictor that generates multiple candidate goals with associated probabilities, enabling multimodal and context-aware intention modelling. Furthermore, we enhance the diffusion process by incorporating adaptive guidance and a residual noise predictor that dynamically refines denoising accuracy. The proposed framework is evaluated on the widely used ETH, UCY, and SDD benchmarks, demonstrating competitive results against state-of-the-art methods.
Intention Enhanced Diffusion Model for Multimodal Pedestrian Trajectory Prediction
Aug 06, 2025



Predicting pedestrian motion trajectories is critical for path planning and motion control of autonomous vehicles. However, accurately forecasting crowd trajectories remains a challenging task due to the inherently multimodal and uncertain nature of human motion. Recent diffusion-based models have shown promising results in capturing the stochasticity of pedestrian behavior for trajectory prediction. However, few diffusion-based approaches explicitly incorporate the underlying motion intentions of pedestrians, which can limit the interpretability and precision of prediction models. In this work, we propose a diffusion-based multimodal trajectory prediction model that incorporates pedestrians' motion intentions into the prediction framework. The motion intentions are decomposed into lateral and longitudinal components, and a pedestrian intention recognition module is introduced to enable the model to effectively capture these intentions. Furthermore, we adopt an efficient guidance mechanism that facilitates the generation of interpretable trajectories. The proposed framework is evaluated on two widely used human trajectory prediction benchmarks, ETH and UCY, on which it is compared against state-of-the-art methods. The experimental results demonstrate that our method achieves competitive performance.
Observability-Aware Active Calibration of Multi-Sensor Extrinsics for Ground Robots via Online Trajectory Optimization
Jun 16, 2025Accurate calibration of sensor extrinsic parameters for ground robotic systems (i.e., relative poses) is crucial for ensuring spatial alignment and achieving high-performance perception. However, existing calibration methods typically require complex and often human-operated processes to collect data. Moreover, most frameworks neglect acoustic sensors, thereby limiting the associated systems' auditory perception capabilities. To alleviate these issues, we propose an observability-aware active calibration method for ground robots with multimodal sensors, including a microphone array, a LiDAR (exteroceptive sensors), and wheel encoders (proprioceptive sensors). Unlike traditional approaches, our method enables active trajectory optimization for online data collection and calibration, contributing to the development of more intelligent robotic systems. Specifically, we leverage the Fisher information matrix (FIM) to quantify parameter observability and adopt its minimum eigenvalue as an optimization metric for trajectory generation via B-spline curves. Through planning and replanning of robot trajectory online, the method enhances the observability of multi-sensor extrinsic parameters. The effectiveness and advantages of our method have been demonstrated through numerical simulations and real-world experiments. For the benefit of the community, we have also open-sourced our code and data at https://github.com/AISLAB-sustech/Multisensor-Calibration.
TGRPO :Fine-tuning Vision-Language-Action Model via Trajectory-wise Group Relative Policy Optimization
Jun 11, 2025



Recent advances in Vision-Language-Action (VLA) model have demonstrated strong generalization capabilities across diverse scenes, tasks, and robotic platforms when pretrained at large-scale datasets. However, these models still require task-specific fine-tuning in novel environments, a process that relies almost exclusively on supervised fine-tuning (SFT) using static trajectory datasets. Such approaches neither allow robot to interact with environment nor do they leverage feedback from live execution. Also, their success is critically dependent on the size and quality of the collected trajectories. Reinforcement learning (RL) offers a promising alternative by enabling closed-loop interaction and aligning learned policies directly with task objectives. In this work, we draw inspiration from the ideas of GRPO and propose the Trajectory-wise Group Relative Policy Optimization (TGRPO) method. By fusing step-level and trajectory-level advantage signals, this method improves GRPO's group-level advantage estimation, thereby making the algorithm more suitable for online reinforcement learning training of VLA. Experimental results on ten manipulation tasks from the libero-object benchmark demonstrate that TGRPO consistently outperforms various baseline methods, capable of generating more robust and efficient policies across multiple tested scenarios. Our source codes are available at: https://github.com/hahans/TGRPO
Listen to Extract: Onset-Prompted Target Speaker Extraction
May 08, 2025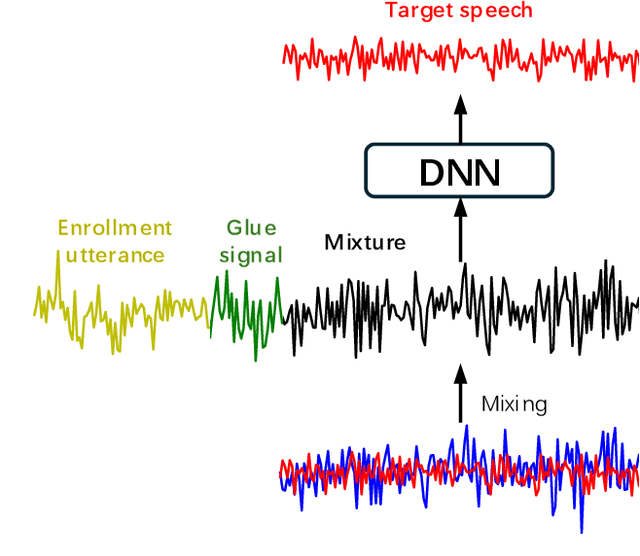
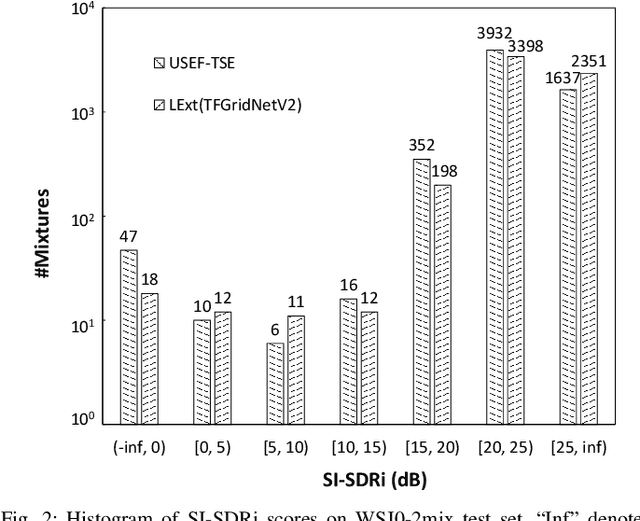
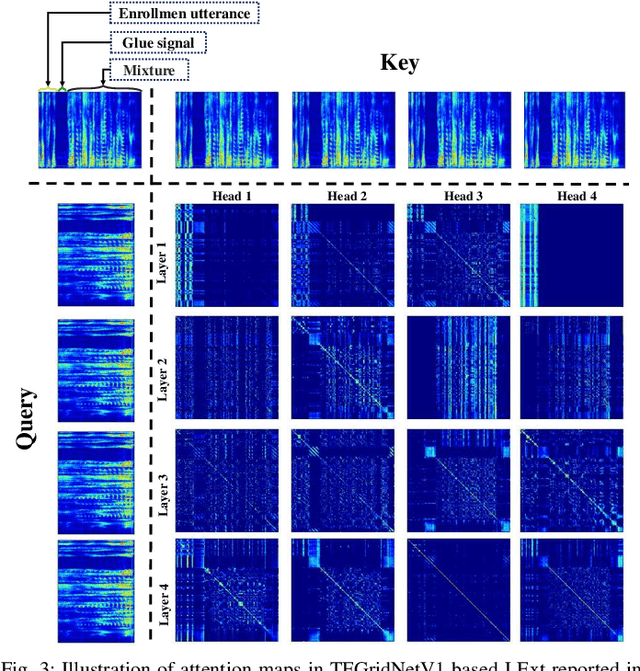
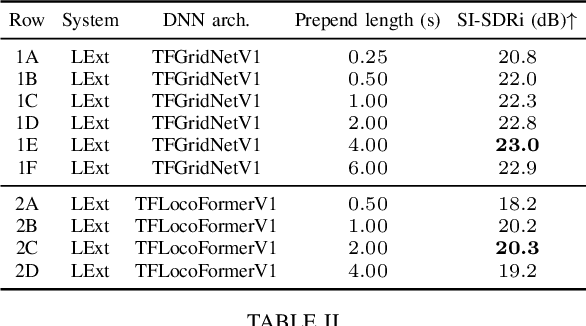
We propose $\textit{listen to extract}$ (LExt), a highly-effective while extremely-simple algorithm for monaural target speaker extraction (TSE). Given an enrollment utterance of a target speaker, LExt aims at extracting the target speaker from the speaker's mixed speech with other speakers. For each mixture, LExt concatenates an enrollment utterance of the target speaker to the mixture signal at the waveform level, and trains deep neural networks (DNN) to extract the target speech based on the concatenated mixture signal. The rationale is that, this way, an artificial speech onset is created for the target speaker and it could prompt the DNN (a) which speaker is the target to extract; and (b) spectral-temporal patterns of the target speaker that could help extraction. This simple approach produces strong TSE performance on multiple public TSE datasets including WSJ0-2mix, WHAM! and WHAMR!.