 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoSeR: Bridging Image and Language for Cognitive Super-Resolution
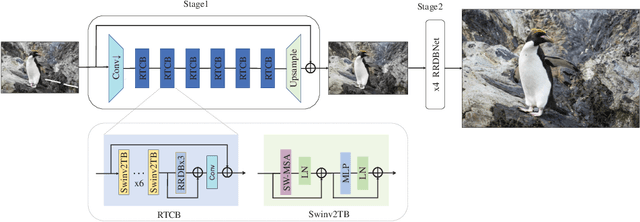
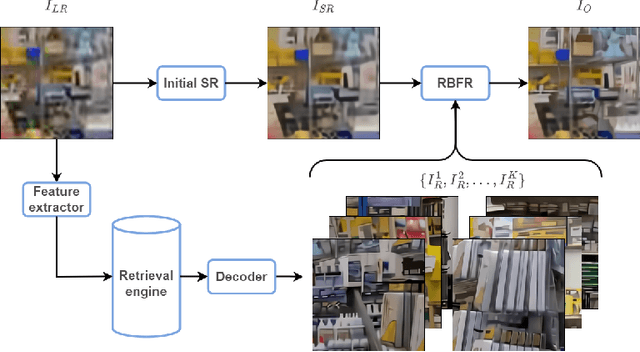
Dec 02, 2023Existing super-resolution (SR) models primarily focus on restoring local texture details, often neglecting the global semantic information within the scene. This oversight can lead to the omission of crucial semantic details or the introduction of inaccurate textures during the recovery process. In our work, we introduce the Cognitive Super-Resolution (CoSeR) framework, empowering SR models with the capacity to comprehend low-resolution images. We achieve this by marrying image appearance and language understanding to generate a cognitive embedding, which not only activates prior information from large text-to-image diffusion models but also facilitates the generation of high-quality reference images to optimize the SR process. To further improve image fidelity, we propose a novel condition injection scheme called "All-in-Attention", consolidating all conditional information into a single module. Consequently, our method successfully restores semantically correct and photorealistic details, demonstrating state-of-the-art performance across multiple benchmarks. Code: https://github.com/VINHYU/CoSeR
Learning Unorthogonalized Matrices for Rotation Estimation
Dec 01, 2023



Estimating 3D rotations is a common procedure for 3D computer vision. The accuracy depends heavily on the rotation representation. One form of representation -- rotation matrices -- is popular due to its continuity, especially for pose estimation tasks. The learning process usually incorporates orthogonalization to ensure orthonormal matrices. Our work reveals, through gradient analysis, that common orthogonalization procedures based on the Gram-Schmidt process and singular value decomposition will slow down training efficiency. To this end, we advocate removing orthogonalization from the learning process and learning unorthogonalized `Pseudo' Rotation Matrices (PRoM). An optimization analysis shows that PRoM converges faster and to a better solution. By replacing the orthogonalization incorporated representation with our proposed PRoM in various rotation-related tasks, we achieve state-of-the-art results on large-scale benchmarks for human pose estimation.
AsConvSR: Fast and Lightweight Super-Resolution Network with Assembled Convolutions
May 05, 2023



In recent years, videos and images in 720p (HD), 1080p (FHD) and 4K (UHD) resolution have become more popular for display devices such as TVs, mobile phones and VR. However, these high resolution images cannot achieve the expected visual effect due to the limitation of the internet bandwidth, and bring a great challenge for super-resolution networks to achieve real-time performance. Following this challenge, we explore multiple efficient network designs, such as pixel-unshuffle, repeat upscaling, and local skip connection removal, and propose a fast and lightweight super-resolution network. Furthermore, by analyzing the applications of the idea of divide-and-conquer in super-resolution, we propose assembled convolutions which can adapt convolution kernels according to the input features. Experiments suggest that our method outperforms all the state-of-the-art efficient super-resolution models, and achieves optimal results in terms of runtime and quality. In addition, our method also wins the first place in NTIRE 2023 Real-Time Super-Resolution - Track 1 ($\times$2). The code will be available at https://gitee.com/mindspore/models/tree/master/research/cv/AsConvSR
A Codec Information Assisted Framework for Efficient Compressed Video Super-Resolution
Oct 15, 2022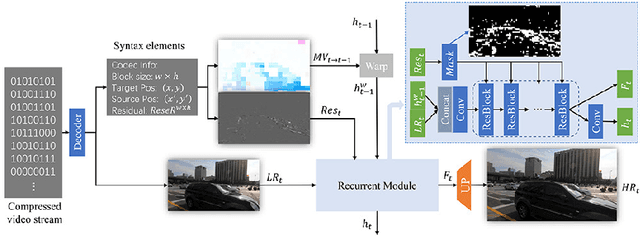

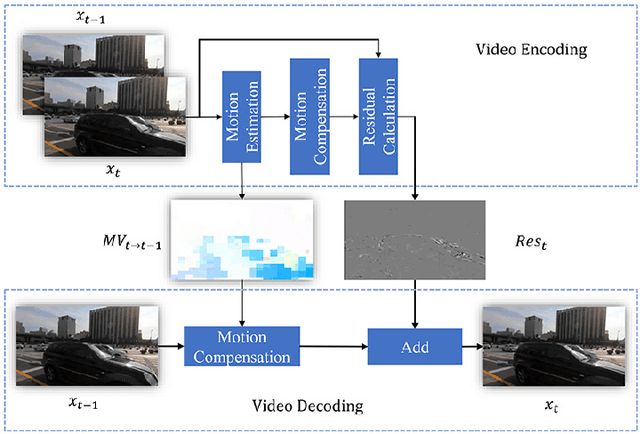
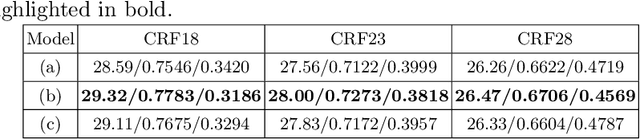
Online processing of compressed videos to increase their resolutions attracts increasing and broad attention. Video Super-Resolution (VSR) using recurrent neural network architecture is a promising solution due to its efficient modeling of long-range temporal dependencies. However, state-of-the-art recurrent VSR models still require significant computation to obtain a good performance, mainly because of the complicated motion estimation for frame/feature alignment and the redundant processing of consecutive video frames. In this paper, considering the characteristics of compressed videos, we propose a Codec Information Assisted Framework (CIAF) to boost and accelerate recurrent VSR models for compressed videos. Firstly, the framework reuses the coded video information of Motion Vectors to model the temporal relationships between adjacent frames. Experiments demonstrate that the models with Motion Vector based alignment can significantly boost the performance with negligible additional computation, even comparable to those using more complex optical flow based alignment. Secondly, by further making use of the coded video information of Residuals, the framework can be informed to skip the computation on redundant pixels. Experiments demonstrate that the proposed framework can save up to 70% of the computation without performance drop on the REDS4 test videos encoded by H.264 when CRF is 23.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022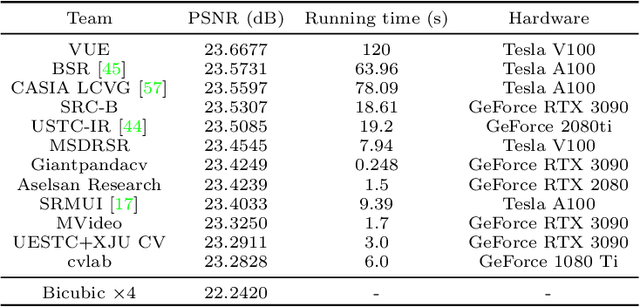

This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
CLIFF: Carrying Location Information in Full Frames into Human Pose and Shape Estimation
Aug 01, 2022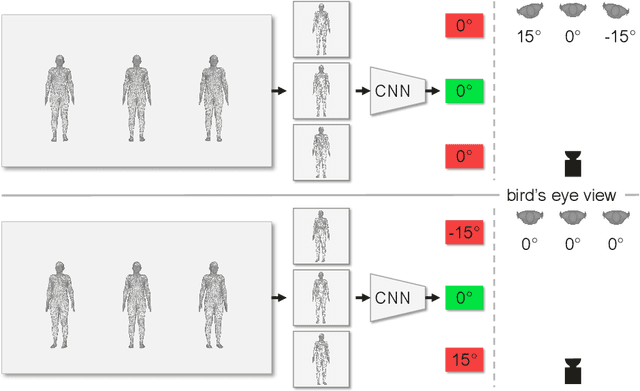
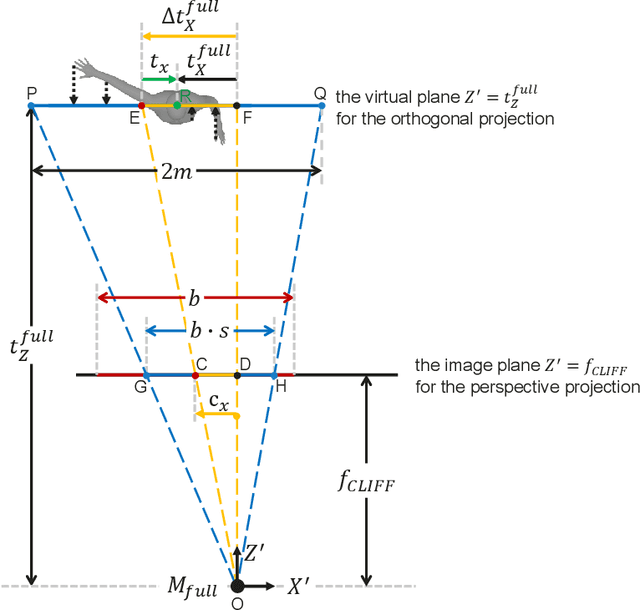
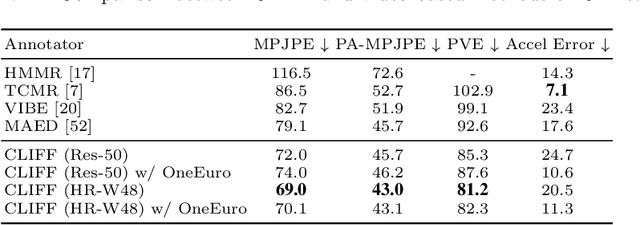
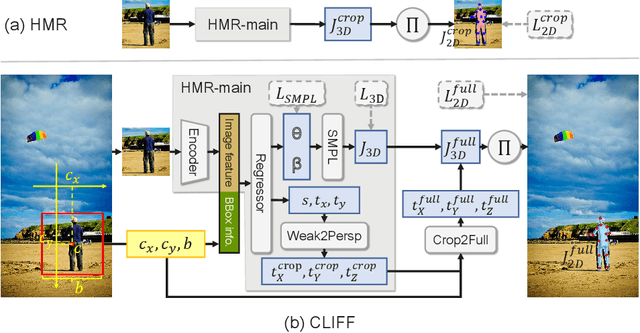
Top-down methods dominate the field of 3D human pose and shape estimation, because they are decoupled from human detection and allow researchers to focus on the core problem. However, cropping, their first step, discards the location information from the very beginning, which makes themselves unable to accurately predict the global rotation in the original camera coordinate system. To address this problem, we propose to Carry Location Information in Full Frames (CLIFF) into this task. Specifically, we feed more holistic features to CLIFF by concatenating the cropped-image feature with its bounding box information. We calculate the 2D reprojection loss with a broader view of the full frame, taking a projection process similar to that of the person projected in the image. Fed and supervised by global-location-aware information, CLIFF directly predicts the global rotation along with more accurate articulated poses. Besides, we propose a pseudo-ground-truth annotator based on CLIFF, which provides high-quality 3D annotations for in-the-wild 2D datasets and offers crucial full supervision for regression-based methods. Extensive experiments on popular benchmarks show that CLIFF outperforms prior arts by a significant margin, and reaches the first place on the AGORA leaderboard (the SMPL-Algorithms track). The code and data are available at https://github.com/huawei-noah/noah-research/tree/master/CLIFF.
Unsupervised Flow-Aligned Sequence-to-Sequence Learning for Video Restoration
May 20, 2022
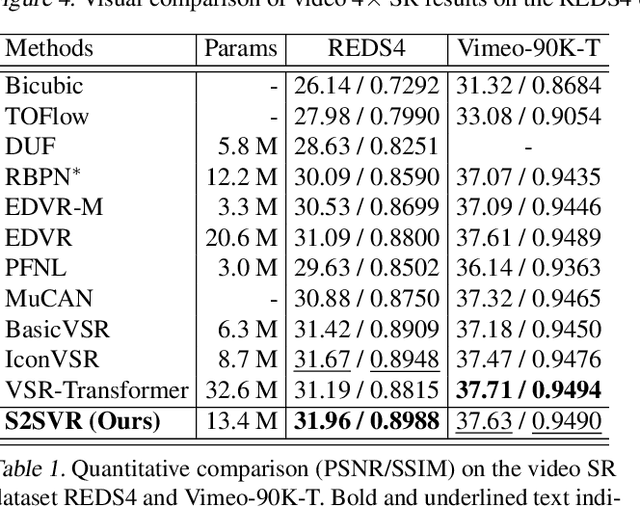
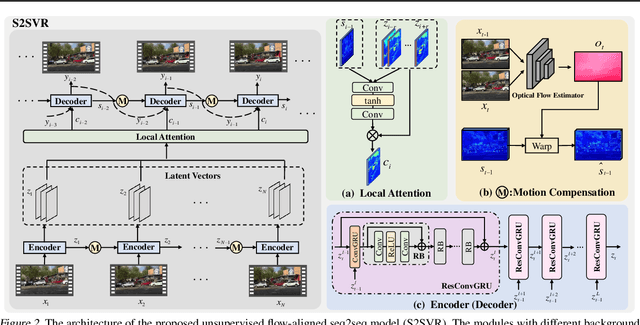
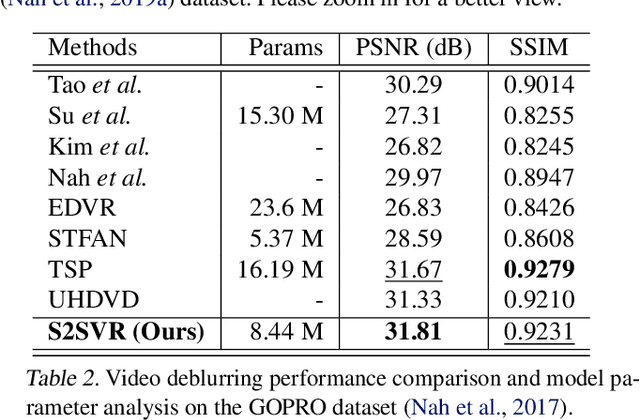
How to properly model the inter-frame relation within the video sequence is an important but unsolved challenge for video restoration (VR). In this work, we propose an unsupervised flow-aligned sequence-to-sequence model (S2SVR) to address this problem. On the one hand, the sequence-to-sequence model, which has proven capable of sequence modeling in the field of natural language processing, is explored for the first time in VR. Optimized serialization modeling shows potential in capturing long-range dependencies among frames. On the other hand, we equip the sequence-to-sequence model with an unsupervised optical flow estimator to maximize its potential. The flow estimator is trained with our proposed unsupervised distillation loss, which can alleviate the data discrepancy and inaccurate degraded optical flow issues of previous flow-based methods. With reliable optical flow, we can establish accurate correspondence among multiple frames, narrowing the domain difference between 1D language and 2D misaligned frames and improving the potential of the sequence-to-sequence model. S2SVR shows superior performance in multiple VR tasks, including video deblurring, video super-resolution, and compressed video quality enhancement. Code and models are publicly available at https://github.com/linjing7/VR-Baseline
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022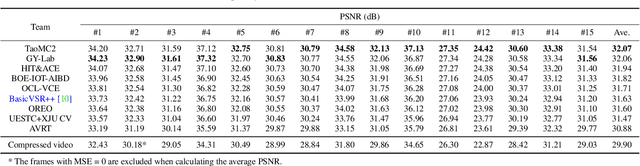
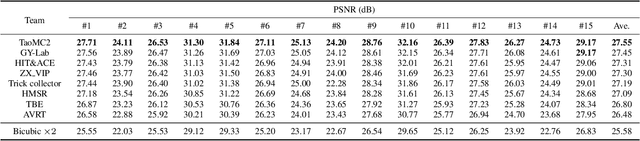

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Flow-Guided Sparse Transformer for Video Deblurring
Jan 06, 2022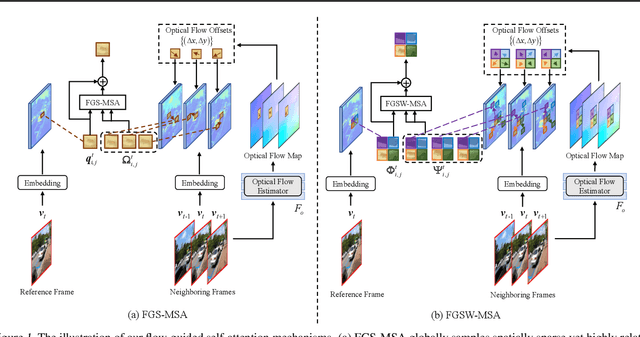
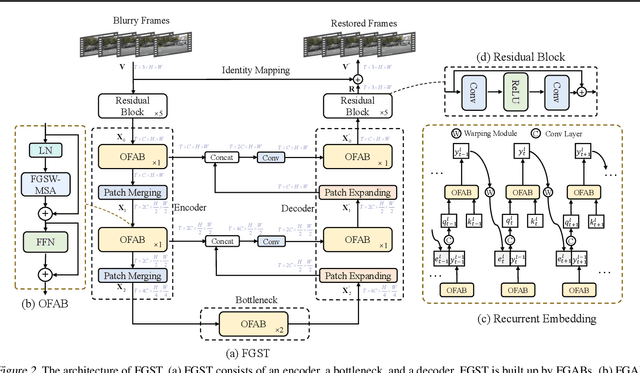

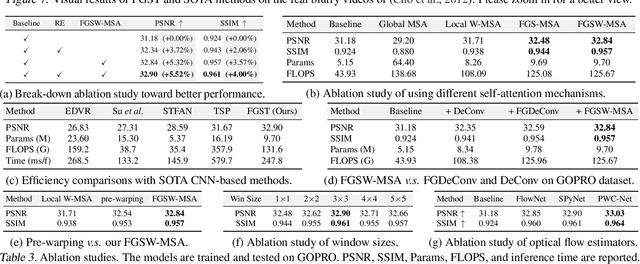
Exploiting similar and sharper scene patches in spatio-temporal neighborhoods is critical for video deblurring. However, CNN-based methods show limitations in capturing long-range dependencies and modeling non-local self-similarity. In this paper, we propose a novel framework, Flow-Guided Sparse Transformer (FGST), for video deblurring. In FGST, we customize a self-attention module, Flow-Guided Sparse Window-based Multi-head Self-Attention (FGSW-MSA). For each $query$ element on the blurry reference frame, FGSW-MSA enjoys the guidance of the estimated optical flow to globally sample spatially sparse yet highly related $key$ elements corresponding to the same scene patch in neighboring frames. Besides, we present a Recurrent Embedding (RE) mechanism to transfer information from past frames and strengthen long-range temporal dependencies. Comprehensive experiments demonstrate that our proposed FGST outperforms state-of-the-art (SOTA) methods on both DVD and GOPRO datasets and even yields more visually pleasing results in real video deblurring. Code and models will be released to the public.
SiamTrans: Zero-Shot Multi-Frame Image Restoration with Pre-Trained Siamese Transformers
Dec 17, 2021
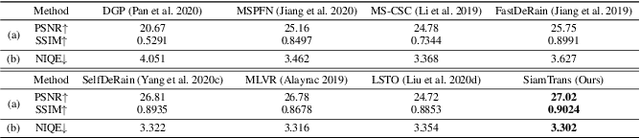
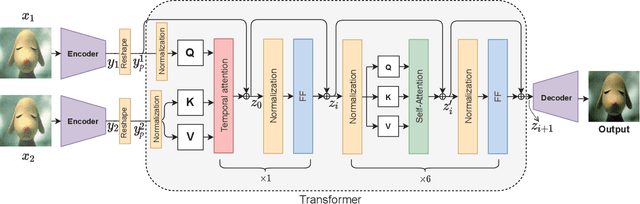
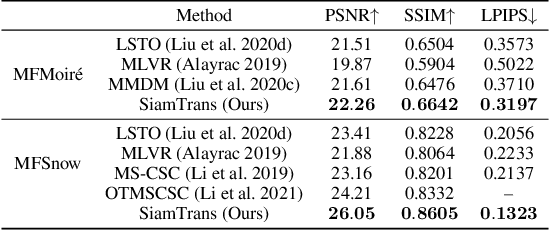
We propose a novel zero-shot multi-frame image restoration method for removing unwanted obstruction elements (such as rains, snow, and moire patterns) that vary in successive frames. It has three stages: transformer pre-training, zero-shot restoration, and hard patch refinement. Using the pre-trained transformers, our model is able to tell the motion difference between the true image information and the obstructing elements. For zero-shot image restoration, we design a novel model, termed SiamTrans, which is constructed by Siamese transformers, encoders, and decoders. Each transformer has a temporal attention layer and several self-attention layers, to capture both temporal and spatial information of multiple frames. Only pre-trained (self-supervised) on the denoising task, SiamTrans is tested on three different low-level vision tasks (deraining, demoireing, and desnowing). Compared with related methods, ours achieves the best performances, even outperforming those with supervised learning.