 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Latent Reasoning via Hierarchical Visual Cues Injection
Feb 05, 2026The advancement of multimodal large language models (MLLMs) has enabled impressive perception capabilities. However, their reasoning process often remains a "fast thinking" paradigm, reliant on end-to-end generation or explicit, language-centric chains of thought (CoT), which can be inefficient, verbose, and prone to hallucination. This work posits that robust reasoning should evolve within a latent space, integrating multimodal signals seamlessly. We propose multimodal latent reasoning via HIerarchical Visual cuEs injection (\emph{HIVE}), a novel framework that instills deliberate, "slow thinking" without depending on superficial textual rationales. Our method recursively extends transformer blocks, creating an internal loop for iterative reasoning refinement. Crucially, it injectively grounds this process with hierarchical visual cues from global scene context to fine-grained regional details directly into the model's latent representations. This enables the model to perform grounded, multi-step inference entirely in the aligned latent space. Extensive evaluations demonstrate that test-time scaling is effective when incorporating vision knowledge, and that integrating hierarchical information significantly enhances the model's understanding of complex scenes.
SRAW-Attack: Space-Reweighted Adversarial Warping Attack for SAR Target Recognition
Jan 15, 2026Synthetic aperture radar (SAR) imagery exhibits intrinsic information sparsity due to its unique electromagnetic scattering mechanism. Despite the widespread adoption of deep neural network (DNN)-based SAR automatic target recognition (SAR-ATR) systems, they remain vulnerable to adversarial examples and tend to over-rely on background regions, leading to degraded adversarial robustness. Existing adversarial attacks for SAR-ATR often require visually perceptible distortions to achieve effective performance, thereby necessitating an attack method that balances effectiveness and stealthiness. In this paper, a novel attack method termed Space-Reweighted Adversarial Warping (SRAW) is proposed, which generates adversarial examples through optimized spatial deformation with reweighted budgets across foreground and background regions. Extensive experiments demonstrate that SRAW significantly degrades the performance of state-of-the-art SAR-ATR models and consistently outperforms existing methods in terms of imperceptibility and adversarial transferability. Code is made available at https://github.com/boremycin/SAR-ATR-TransAttack.
Learning to Decode in Parallel: Self-Coordinating Neural Network for Real-Time Quantum Error Correction
Jan 14, 2026Fast, reliable decoders are pivotal components for enabling fault-tolerant quantum computation (FTQC). Neural network decoders like AlphaQubit have demonstrated potential, achieving higher accuracy than traditional human-designed decoding algorithms. However, existing implementations of neural network decoders lack the parallelism required to decode the syndrome stream generated by a superconducting logical qubit in real time. Moreover, integrating AlphaQubit with sliding window-based parallel decoding schemes presents non-trivial challenges: AlphaQubit is trained solely to output a single bit corresponding to the global logical correction for an entire memory experiment, rather than local physical corrections that can be easily integrated. We address this issue by training a recurrent, transformer-based neural network specifically tailored for parallel window decoding. While it still outputs a single bit, we derive training labels from a consistent set of local corrections and train on various types of decoding windows simultaneously. This approach enables the network to self-coordinate across neighboring windows, facilitating high-accuracy parallel decoding of arbitrarily long memory experiments. As a result, we overcome the throughput bottleneck that previously precluded the use of AlphaQubit-type decoders in FTQC. Our work presents the first scalable, neural-network-based parallel decoding framework that simultaneously achieves SOTA accuracy and the stringent throughput required for real-time quantum error correction. Using an end-to-end experimental workflow, we benchmark our decoder on the Zuchongzhi 3.2 superconducting quantum processor on surface codes with distances up to 7, demonstrating its superior accuracy. Moreover, we demonstrate that, using our approach, a single TPU v6e is capable of decoding surface codes with distances up to 25 within 1us per decoding round.
LinguaGame: A Linguistically Grounded Game-Theoretic Paradigm for Multi-Agent Dialogue Generation
Jan 08, 2026Large Language Models (LLMs) have enabled Multi-Agent Systems (MASs) where agents interact through natural language to solve complex tasks or simulate multi-party dialogues. Recent work on LLM-based MASs has mainly focused on architecture design, such as role assignment and workflow orchestration. In contrast, this paper targets the interaction process itself, aiming to improve agents' communication efficiency by helping them convey their intended meaning more effectively through language. To this end, we propose LinguaGame, a linguistically-grounded game-theoretic paradigm for multi-agent dialogue generation. Our approach models dialogue as a signalling game over communicative intents and strategies, solved with a training-free equilibrium approximation algorithm for inference-time decision adjustment. Unlike prior game-theoretic MASs, whose game designs are often tightly coupled with task-specific objectives, our framework relies on linguistically informed reasoning with minimal task-specific coupling. Specifically, it treats dialogue as intentional and strategic communication, requiring agents to infer what others aim to achieve (intents) and how they pursue those goals (strategies). We evaluate our framework in simulated courtroom proceedings and debates, with human expert assessments showing significant gains in communication efficiency.
Improving Few-Shot Change Detection Visual Question Answering via Decision-Ambiguity-guided Reinforcement Fine-Tuning
Dec 31, 2025Change detection visual question answering (CDVQA) requires answering text queries by reasoning about semantic changes in bi-temporal remote sensing images. A straightforward approach is to boost CDVQA performance with generic vision-language models via supervised fine-tuning (SFT). Despite recent progress, we observe that a significant portion of failures do not stem from clearly incorrect predictions, but from decision ambiguity, where the model assigns similar confidence to the correct answer and strong distractors. To formalize this challenge, we define Decision-Ambiguous Samples (DAS) as instances with a small probability margin between the ground-truth answer and the most competitive alternative. We argue that explicitly optimizing DAS is crucial for improving the discriminability and robustness of CDVQA models. To this end, we propose DARFT, a Decision-Ambiguity-guided Reinforcement Fine-Tuning framework that first mines DAS using an SFT-trained reference policy and then applies group-relative policy optimization on the mined subset. By leveraging multi-sample decoding and intra-group relative advantages, DARFT suppresses strong distractors and sharpens decision boundaries without additional supervision. Extensive experiments demonstrate consistent gains over SFT baselines, particularly under few-shot settings.
A Dual-Branch Local-Global Framework for Cross-Resolution Land Cover Mapping
Dec 23, 2025Cross-resolution land cover mapping aims to produce high-resolution semantic predictions from coarse or low-resolution supervision, yet the severe resolution mismatch makes effective learning highly challenging. Existing weakly supervised approaches often struggle to align fine-grained spatial structures with coarse labels, leading to noisy supervision and degraded mapping accuracy. To tackle this problem, we propose DDTM, a dual-branch weakly supervised framework that explicitly decouples local semantic refinement from global contextual reasoning. Specifically, DDTM introduces a diffusion-based branch to progressively refine fine-scale local semantics under coarse supervision, while a transformer-based branch enforces long-range contextual consistency across large spatial extents. In addition, we design a pseudo-label confidence evaluation module to mitigate noise induced by cross-resolution inconsistencies and to selectively exploit reliable supervisory signals. Extensive experiments demonstrate that DDTM establishes a new state-of-the-art on the Chesapeake Bay benchmark, achieving 66.52\% mIoU and substantially outperforming prior weakly supervised methods. The code is available at https://github.com/gpgpgp123/DDTM.
Achieving Olympia-Level Geometry Large Language Model Agent via Complexity Boosting Reinforcement Learning
Dec 12, 2025Large language model (LLM) agents exhibit strong mathematical problem-solving abilities and can even solve International Mathematical Olympiad (IMO) level problems with the assistance of formal proof systems. However, due to weak heuristics for auxiliary constructions, AI for geometry problem solving remains dominated by expert models such as AlphaGeometry 2, which rely heavily on large-scale data synthesis and search for both training and evaluation. In this work, we make the first attempt to build a medalist-level LLM agent for geometry and present InternGeometry. InternGeometry overcomes the heuristic limitations in geometry by iteratively proposing propositions and auxiliary constructions, verifying them with a symbolic engine, and reflecting on the engine's feedback to guide subsequent proposals. A dynamic memory mechanism enables InternGeometry to conduct more than two hundred interactions with the symbolic engine per problem. To further accelerate learning, we introduce Complexity-Boosting Reinforcement Learning (CBRL), which gradually increases the complexity of synthesized problems across training stages. Built on InternThinker-32B, InternGeometry solves 44 of 50 IMO geometry problems (2000-2024), exceeding the average gold medalist score (40.9), using only 13K training examples, just 0.004% of the data used by AlphaGeometry 2, demonstrating the potential of LLM agents on expert-level geometry tasks. InternGeometry can also propose novel auxiliary constructions for IMO problems that do not appear in human solutions. We will release the model, data, and symbolic engine to support future research.
Collaborative QA using Interacting LLMs. Impact of Network Structure, Node Capability and Distributed Data
Nov 18, 2025In this paper, we model and analyze how a network of interacting LLMs performs collaborative question-answering (CQA) in order to estimate a ground truth given a distributed set of documents. This problem is interesting because LLMs often hallucinate when direct evidence to answer a question is lacking, and these effects become more pronounced in a network of interacting LLMs. The hallucination spreads, causing previously accurate LLMs to hallucinate. We study interacting LLMs and their hallucination by combining novel ideas of mean-field dynamics (MFD) from network science and the randomized utility model from economics to construct a useful generative model. We model the LLM with a latent state that indicates if it is truthful or not with respect to the ground truth, and extend a tractable analytical model considering an MFD to model the diffusion of information in a directed network of LLMs. To specify the probabilities that govern the dynamics of the MFD, we propose a randomized utility model. For a network of LLMs, where each LLM has two possible latent states, we posit sufficient conditions for the existence and uniqueness of a fixed point and analyze the behavior of the fixed point in terms of the incentive (e.g., test-time compute) given to individual LLMs. We experimentally study and analyze the behavior of a network of $100$ open-source LLMs with respect to data heterogeneity, node capability, network structure, and sensitivity to framing on multiple semi-synthetic datasets.
VFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
Oct 29, 2025Visual effects (VFX) are crucial to the expressive power of digital media, yet their creation remains a major challenge for generative AI. Prevailing methods often rely on the one-LoRA-per-effect paradigm, which is resource-intensive and fundamentally incapable of generalizing to unseen effects, thus limiting scalability and creation. To address this challenge, we introduce VFXMaster, the first unified, reference-based framework for VFX video generation. It recasts effect generation as an in-context learning task, enabling it to reproduce diverse dynamic effects from a reference video onto target content. In addition, it demonstrates remarkable generalization to unseen effect categories. Specifically, we design an in-context conditioning strategy that prompts the model with a reference example. An in-context attention mask is designed to precisely decouple and inject the essential effect attributes, allowing a single unified model to master the effect imitation without information leakage. In addition, we propose an efficient one-shot effect adaptation mechanism to boost generalization capability on tough unseen effects from a single user-provided video rapidly. Extensive experiments demonstrate that our method effectively imitates various categories of effect information and exhibits outstanding generalization to out-of-domain effects. To foster future research, we will release our code, models, and a comprehensive dataset to the community.
InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models
Sep 26, 2025


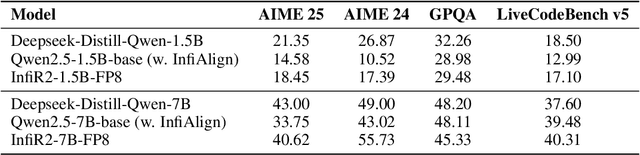
The immense computational cost of training Large Language Models (LLMs) presents a major barrier to innovation. While FP8 training offers a promising solution with significant theoretical efficiency gains, its widespread adoption has been hindered by the lack of a comprehensive, open-source training recipe. To bridge this gap, we introduce an end-to-end FP8 training recipe that seamlessly integrates continual pre-training and supervised fine-tuning. Our methodology employs a fine-grained, hybrid-granularity quantization strategy to maintain numerical fidelity while maximizing computational efficiency. Through extensive experiments, including the continue pre-training of models on a 160B-token corpus, we demonstrate that our recipe is not only remarkably stable but also essentially lossless, achieving performance on par with the BF16 baseline across a suite of reasoning benchmarks. Crucially, this is achieved with substantial efficiency improvements, including up to a 22% reduction in training time, a 14% decrease in peak memory usage, and a 19% increase in throughput. Our results establish FP8 as a practical and robust alternative to BF16, and we will release the accompanying code to further democratize large-scale model training.