 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking-while-speaking: A Controlled, Interleaved Reasoning Method for Real-Time Speech Generation
May 20, 2026The thinking-while-speaking paradigm aims to make AI communication more human. A key challenge is maintaining fluent speech while performing deep reasoning. Our method, InterRS, tackles this by inserting reasoning steps only during natural speech generation. This requires high-quality data where reasoning and speech are precisely aligned, and the length ratio are under controlled. We introduce a novel pipeline to generate such seamlessly interleaved audio data. To train our model, we combine interleaved SFT with refined data and reinforcement learning with two new rewards: a TA-Balance Reward to manage timing and thinking-answer ratio, and a Linguistic Quality Reward to refine expression. Experiments show our approach achieves 13% better performance on mathmatical and logic benchmarks while generating instant response like a spoken-language instruct model which outputs fast CoT response. Furthermore, our method generates more natural and fluent answers than prior methods.
Multimodal Latent Reasoning via Hierarchical Visual Cues Injection
Feb 05, 2026The advancement of multimodal large language models (MLLMs) has enabled impressive perception capabilities. However, their reasoning process often remains a "fast thinking" paradigm, reliant on end-to-end generation or explicit, language-centric chains of thought (CoT), which can be inefficient, verbose, and prone to hallucination. This work posits that robust reasoning should evolve within a latent space, integrating multimodal signals seamlessly. We propose multimodal latent reasoning via HIerarchical Visual cuEs injection (\emph{HIVE}), a novel framework that instills deliberate, "slow thinking" without depending on superficial textual rationales. Our method recursively extends transformer blocks, creating an internal loop for iterative reasoning refinement. Crucially, it injectively grounds this process with hierarchical visual cues from global scene context to fine-grained regional details directly into the model's latent representations. This enables the model to perform grounded, multi-step inference entirely in the aligned latent space. Extensive evaluations demonstrate that test-time scaling is effective when incorporating vision knowledge, and that integrating hierarchical information significantly enhances the model's understanding of complex scenes.
Towards Lossless Ultimate Vision Token Compression for VLMs
Dec 09, 2025Visual language models encounter challenges in computational efficiency and latency, primarily due to the substantial redundancy in the token representations of high-resolution images and videos. Current attention/similarity-based compression algorithms suffer from either position bias or class imbalance, leading to significant accuracy degradation. They also fail to generalize to shallow LLM layers, which exhibit weaker cross-modal interactions. To address this, we extend token compression to the visual encoder through an effective iterative merging scheme that is orthogonal in spatial axes to accelerate the computation across the entire VLM. Furthermoer, we integrate a spectrum pruning unit into LLM through an attention/similarity-free low-pass filter, which gradually prunes redundant visual tokens and is fully compatible to modern FlashAttention. On this basis, we propose Lossless Ultimate Vision tokens Compression (LUVC) framework. LUVC systematically compresses visual tokens until complete elimination at the final layer of LLM, so that the high-dimensional visual features are gradually fused into the multimodal queries. The experiments show that LUVC achieves a 2 speedup inference in language model with negligible accuracy degradation, and the training-free characteristic enables immediate deployment across multiple VLMs.
Positional Preservation Embedding for Multimodal Large Language Models
Oct 27, 2025Multimodal large language models (MLLMs) have achieved strong performance on vision-language tasks, yet often suffer from inefficiencies due to redundant visual tokens. Existing token merging methods reduce sequence length but frequently disrupt spatial layouts and temporal continuity by disregarding positional relationships. In this work, we propose a novel encoding operator dubbed as \textbf{P}ositional \textbf{P}reservation \textbf{E}mbedding (\textbf{PPE}), which has the main hallmark of preservation of spatiotemporal structure during visual token compression. PPE explicitly introduces the disentangled encoding of 3D positions in the token dimension, enabling each compressed token to encapsulate different positions from multiple original tokens. Furthermore, we show that PPE can effectively support cascade clustering -- a progressive token compression strategy that leads to better performance retention. PPE is a parameter-free and generic operator that can be seamlessly integrated into existing token merging methods without any adjustments. Applied to state-of-the-art token merging framework, PPE achieves consistent improvements of $2\%\sim5\%$ across multiple vision-language benchmarks, including MMBench (general vision understanding), TextVQA (layout understanding) and VideoMME (temporal understanding). These results demonstrate that preserving positional cues is critical for efficient and effective MLLM reasoning.
OmniEval: A Benchmark for Evaluating Omni-modal Models with Visual, Auditory, and Textual Inputs
Jun 26, 2025In this paper, we introduce OmniEval, a benchmark for evaluating omni-modality models like MiniCPM-O 2.6, which encompasses visual, auditory, and textual inputs. Compared with existing benchmarks, our OmniEval has several distinctive features: (i) Full-modal collaboration: We design evaluation tasks that highlight the strong coupling between audio and video, requiring models to effectively leverage the collaborative perception of all modalities; (ii) Diversity of videos: OmniEval includes 810 audio-visual synchronized videos, 285 Chinese videos and 525 English videos; (iii) Diversity and granularity of tasks: OmniEval contains 2617 question-answer pairs, comprising 1412 open-ended questions and 1205 multiple-choice questions. These questions are divided into 3 major task types and 12 sub-task types to achieve comprehensive evaluation. Among them, we introduce a more granular video localization task named Grounding. Then we conduct experiments on OmniEval with several omni-modality models. We hope that our OmniEval can provide a platform for evaluating the ability to construct and understand coherence from the context of all modalities. Codes and data could be found at https://omnieval.github.io/.
Single Domain Generalization for Few-Shot Counting via Universal Representation Matching
May 22, 2025



Few-shot counting estimates the number of target objects in an image using only a few annotated exemplars. However, domain shift severely hinders existing methods to generalize to unseen scenarios. This falls into the realm of single domain generalization that remains unexplored in few-shot counting. To solve this problem, we begin by analyzing the main limitations of current methods, which typically follow a standard pipeline that extract the object prototypes from exemplars and then match them with image feature to construct the correlation map. We argue that existing methods overlook the significance of learning highly generalized prototypes. Building on this insight, we propose the first single domain generalization few-shot counting model, Universal Representation Matching, termed URM. Our primary contribution is the discovery that incorporating universal vision-language representations distilled from a large scale pretrained vision-language model into the correlation construction process substantially improves robustness to domain shifts without compromising in domain performance. As a result, URM achieves state-of-the-art performance on both in domain and the newly introduced domain generalization setting.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025



Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
Deep High-Resolution Representation Learning for Visual Recognition
Aug 20, 2019
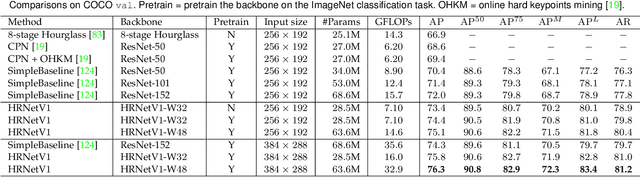

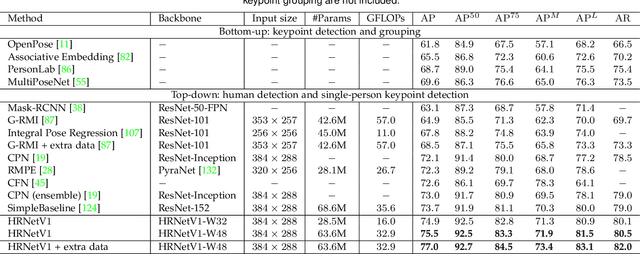
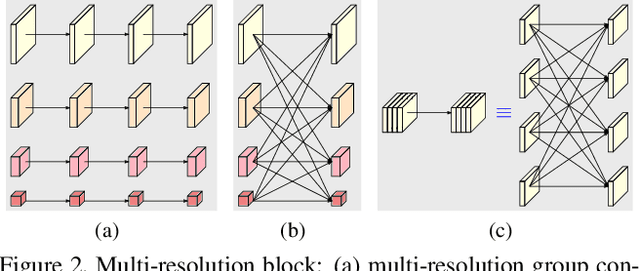
High-resolution representations are essential for position-sensitive vision problems, such as human pose estimation, semantic segmentation, and object detection. Existing state-of-the-art frameworks first encode the input image as a low-resolution representation through a subnetwork that is formed by connecting high-to-low resolution convolutions \emph{in series} (e.g., ResNet, VGGNet), and then recover the high-resolution representation from the encoded low-resolution representation. Instead, our proposed network, named as High-Resolution Network (HRNet), maintains high-resolution representations through the whole process. There are two key characteristics: (i) Connect the high-to-low resolution convolution streams \emph{in parallel}; (ii) Repeatedly exchange the information across resolutions. The benefit is that the resulting representation is semantically richer and spatially more precise. We show the superiority of the proposed HRNet in a wide range of applications, including human pose estimation, semantic segmentation, and object detection, suggesting that the HRNet is a stronger backbone for computer vision problems. All the codes are available at~{\url{https://github.com/HRNet}}.
High-Resolution Representations for Labeling Pixels and Regions
Apr 09, 2019
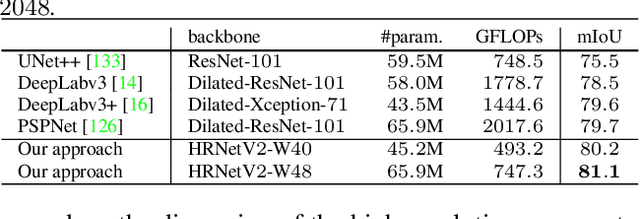
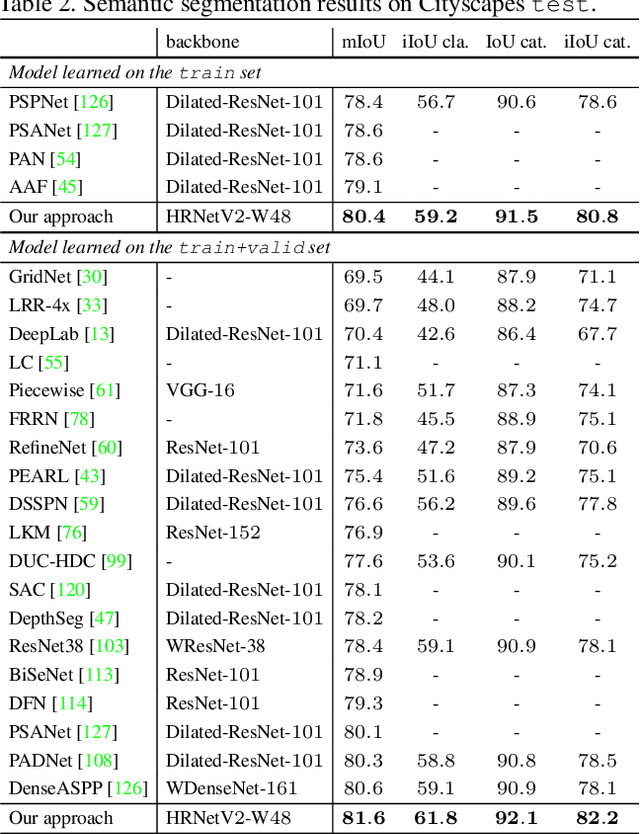
High-resolution representation learning plays an essential role in many vision problems, e.g., pose estimation and semantic segmentation. The high-resolution network (HRNet)~\cite{SunXLW19}, recently developed for human pose estimation, maintains high-resolution representations through the whole process by connecting high-to-low resolution convolutions in \emph{parallel} and produces strong high-resolution representations by repeatedly conducting fusions across parallel convolutions. In this paper, we conduct a further study on high-resolution representations by introducing a simple yet effective modification and apply it to a wide range of vision tasks. We augment the high-resolution representation by aggregating the (upsampled) representations from all the parallel convolutions rather than only the representation from the high-resolution convolution as done in~\cite{SunXLW19}. This simple modification leads to stronger representations, evidenced by superior results. We show top results in semantic segmentation on Cityscapes, LIP, and PASCAL Context, and facial landmark detection on AFLW, COFW, $300$W, and WFLW. In addition, we build a multi-level representation from the high-resolution representation and apply it to the Faster R-CNN object detection framework and the extended frameworks. The proposed approach achieves superior results to existing single-model networks on COCO object detection. The code and models have been publicly available at \url{https://github.com/HRNet}.
Acquisition of Localization Confidence for Accurate Object Detection
Jul 30, 2018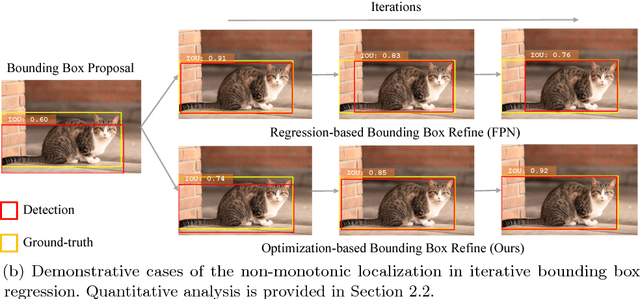
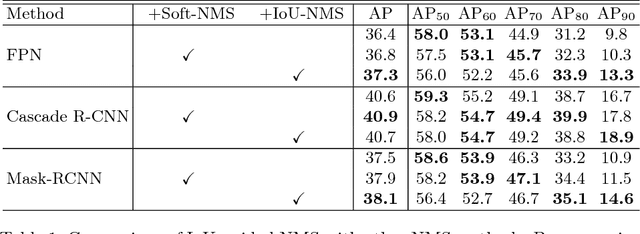
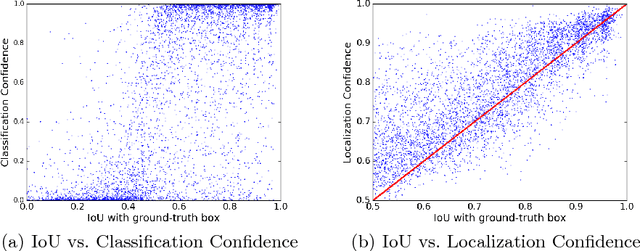
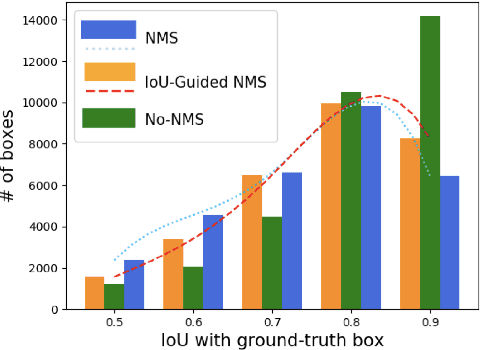
Modern CNN-based object detectors rely on bounding box regression and non-maximum suppression to localize objects. While the probabilities for class labels naturally reflect classification confidence, localization confidence is absent. This makes properly localized bounding boxes degenerate during iterative regression or even suppressed during NMS. In the paper we propose IoU-Net learning to predict the IoU between each detected bounding box and the matched ground-truth. The network acquires this confidence of localization, which improves the NMS procedure by preserving accurately localized bounding boxes. Furthermore, an optimization-based bounding box refinement method is proposed, where the predicted IoU is formulated as the objective. Extensive experiments on the MS-COCO dataset show the effectiveness of IoU-Net, as well as its compatibility with and adaptivity to several state-of-the-art object detectors.