 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni3D: A Unified Baseline for Multi-dataset 3D Object Detection
Mar 13, 2023Current 3D object detection models follow a single dataset-specific training and testing paradigm, which often faces a serious detection accuracy drop when they are directly deployed in another dataset. In this paper, we study the task of training a unified 3D detector from multiple datasets. We observe that this appears to be a challenging task, which is mainly due to that these datasets present substantial data-level differences and taxonomy-level variations caused by different LiDAR types and data acquisition standards. Inspired by such observation, we present a Uni3D which leverages a simple data-level correction operation and a designed semantic-level coupling-and-recoupling module to alleviate the unavoidable data-level and taxonomy-level differences, respectively. Our method is simple and easily combined with many 3D object detection baselines such as PV-RCNN and Voxel-RCNN, enabling them to effectively learn from multiple off-the-shelf 3D datasets to obtain more discriminative and generalizable representations. Experiments are conducted on many dataset consolidation settings including Waymo-nuScenes, nuScenes-KITTI, Waymo-KITTI, and Waymo-nuScenes-KITTI consolidations. Their results demonstrate that Uni3D exceeds a series of individual detectors trained on a single dataset, with a 1.04x parameter increase over a selected baseline detector. We expect this work will inspire the research of 3D generalization since it will push the limits of perceptual performance.
SCPNet: Semantic Scene Completion on Point Cloud
Mar 13, 2023Training deep models for semantic scene completion (SSC) is challenging due to the sparse and incomplete input, a large quantity of objects of diverse scales as well as the inherent label noise for moving objects. To address the above-mentioned problems, we propose the following three solutions: 1) Redesigning the completion sub-network. We design a novel completion sub-network, which consists of several Multi-Path Blocks (MPBs) to aggregate multi-scale features and is free from the lossy downsampling operations. 2) Distilling rich knowledge from the multi-frame model. We design a novel knowledge distillation objective, dubbed Dense-to-Sparse Knowledge Distillation (DSKD). It transfers the dense, relation-based semantic knowledge from the multi-frame teacher to the single-frame student, significantly improving the representation learning of the single-frame model. 3) Completion label rectification. We propose a simple yet effective label rectification strategy, which uses off-the-shelf panoptic segmentation labels to remove the traces of dynamic objects in completion labels, greatly improving the performance of deep models especially for those moving objects. Extensive experiments are conducted in two public SSC benchmarks, i.e., SemanticKITTI and SemanticPOSS. Our SCPNet ranks 1st on SemanticKITTI semantic scene completion challenge and surpasses the competitive S3CNet by 7.2 mIoU. SCPNet also outperforms previous completion algorithms on the SemanticPOSS dataset. Besides, our method also achieves competitive results on SemanticKITTI semantic segmentation tasks, showing that knowledge learned in the scene completion is beneficial to the segmentation task.
Bi3D: Bi-domain Active Learning for Cross-domain 3D Object Detection
Mar 10, 2023



Unsupervised Domain Adaptation (UDA) technique has been explored in 3D cross-domain tasks recently. Though preliminary progress has been made, the performance gap between the UDA-based 3D model and the supervised one trained with fully annotated target domain is still large. This motivates us to consider selecting partial-yet-important target data and labeling them at a minimum cost, to achieve a good trade-off between high performance and low annotation cost. To this end, we propose a Bi-domain active learning approach, namely Bi3D, to solve the cross-domain 3D object detection task. The Bi3D first develops a domainness-aware source sampling strategy, which identifies target-domain-like samples from the source domain to avoid the model being interfered by irrelevant source data. Then a diversity-based target sampling strategy is developed, which selects the most informative subset of target domain to improve the model adaptability to the target domain using as little annotation budget as possible. Experiments are conducted on typical cross-domain adaptation scenarios including cross-LiDAR-beam, cross-country, and cross-sensor, where Bi3D achieves a promising target-domain detection accuracy (89.63% on KITTI) compared with UDAbased work (84.29%), even surpassing the detector trained on the full set of the labeled target domain (88.98%). Our code is available at: https://github.com/PJLabADG/3DTrans.
Dynamic Scenario Representation Learning for Motion Forecasting with Heterogeneous Graph Convolutional Recurrent Networks
Mar 08, 2023Due to the complex and changing interactions in dynamic scenarios, motion forecasting is a challenging problem in autonomous driving. Most existing works exploit static road graphs to characterize scenarios and are limited in modeling evolving spatio-temporal dependencies in dynamic scenarios. In this paper, we resort to dynamic heterogeneous graphs to model the scenario. Various scenario components including vehicles (agents) and lanes, multi-type interactions, and their changes over time are jointly encoded. Furthermore, we design a novel heterogeneous graph convolutional recurrent network, aggregating diverse interaction information and capturing their evolution, to learn to exploit intrinsic spatio-temporal dependencies in dynamic graphs and obtain effective representations of dynamic scenarios. Finally, with a motion forecasting decoder, our model predicts realistic and multi-modal future trajectories of agents and outperforms state-of-the-art published works on several motion forecasting benchmarks.
Bringing Diversity to Autonomous Vehicles: An Interpretable Multi-vehicle Decision-making and Planning Framework
Feb 14, 2023



With the development of autonomous driving, it is becoming increasingly common for autonomous vehicles (AVs) and human-driven vehicles (HVs) to travel on the same roads. Existing single-vehicle planning algorithms on board struggle to handle sophisticated social interactions in the real world. Decisions made by these methods are difficult to understand for humans, raising the risk of crashes and making them unlikely to be applied in practice. Moreover, vehicle flows produced by open-source traffic simulators suffer from being overly conservative and lacking behavioral diversity. We propose a hierarchical multi-vehicle decision-making and planning framework with several advantages. The framework jointly makes decisions for all vehicles within the flow and reacts promptly to the dynamic environment through a high-frequency planning module. The decision module produces interpretable action sequences that can explicitly communicate self-intent to the surrounding HVs. We also present the cooperation factor and trajectory weight set, bringing diversity to autonomous vehicles in traffic at both the social and individual levels. The superiority of our proposed framework is validated through experiments with multiple scenarios, and the diverse behaviors in the generated vehicle trajectories are demonstrated through closed-loop simulations.
SensorX2car: Sensors-to-car calibration for autonomous driving in road scenarios
Jan 18, 2023The performance of sensors in the autonomous driving system is fundamentally limited by the quality of sensor calibration. Sensors must be well-located with respect to the car-body frame before they can provide meaningful localization and environmental perception. However, while many online methods are proposed to calibrate the extrinsic parameters between sensors, few studies focus on the calibration between sensor and vehicle coordinate system. To this end, we present SensorX2car, a calibration toolbox for the online calibration of sensor-to-car coordinate systems in road scenes. It contains four commonly used sensors: IMU (Inertial Measurement Unit), GNSS (Global Navigation Satellite System), LiDAR (Light Detection and Ranging), Camera, and millimeter-wave Radar. We design a method for each sensor respectively and mainly calibrate its rotation to the car-body. Real-world and simulated experiments demonstrate the accuracy and generalization capabilities of the proposed method. Meanwhile, the related codes have been open-sourced to benefit the community. To the best of our knowledge, SensorX2car is the first open-source sensor-to-car calibration toolbox. The code is available at https://github.com/OpenCalib/SensorX2car.
CLIP2Scene: Towards Label-efficient 3D Scene Understanding by CLIP
Jan 12, 2023Contrastive language-image pre-training (CLIP) achieves promising results in 2D zero-shot and few-shot learning. Despite the impressive performance in 2D tasks, applying CLIP to help the learning in 3D scene understanding has yet to be explored. In this paper, we make the first attempt to investigate how CLIP knowledge benefits 3D scene understanding. To this end, we propose CLIP2Scene, a simple yet effective framework that transfers CLIP knowledge from 2D image-text pre-trained models to a 3D point cloud network. We show that the pre-trained 3D network yields impressive performance on various downstream tasks, i.e., annotation-free and fine-tuning with labelled data for semantic segmentation. Specifically, built upon CLIP, we design a Semantic-driven Cross-modal Contrastive Learning framework that pre-trains a 3D network via semantic and spatial-temporal consistency regularization. For semantic consistency regularization, we first leverage CLIP's text semantics to select the positive and negative point samples and then employ the contrastive loss to train the 3D network. In terms of spatial-temporal consistency regularization, we force the consistency between the temporally coherent point cloud features and their corresponding image features. We conduct experiments on the nuScenes and SemanticKITTI datasets. For the first time, our pre-trained network achieves annotation-free 3D semantic segmentation with 20.8\% mIoU. When fine-tuned with 1\% or 100\% labelled data, our method significantly outperforms other self-supervised methods, with improvements of 8\% and 1\% mIoU, respectively. Furthermore, we demonstrate its generalization capability for handling cross-domain datasets.
LWSIS: LiDAR-guided Weakly Supervised Instance Segmentation for Autonomous Driving
Dec 07, 2022



Image instance segmentation is a fundamental research topic in autonomous driving, which is crucial for scene understanding and road safety. Advanced learning-based approaches often rely on the costly 2D mask annotations for training. In this paper, we present a more artful framework, LiDAR-guided Weakly Supervised Instance Segmentation (LWSIS), which leverages the off-the-shelf 3D data, i.e., Point Cloud, together with the 3D boxes, as natural weak supervisions for training the 2D image instance segmentation models. Our LWSIS not only exploits the complementary information in multimodal data during training, but also significantly reduces the annotation cost of the dense 2D masks. In detail, LWSIS consists of two crucial modules, Point Label Assignment (PLA) and Graph-based Consistency Regularization (GCR). The former module aims to automatically assign the 3D point cloud as 2D point-wise labels, while the latter further refines the predictions by enforcing geometry and appearance consistency of the multimodal data. Moreover, we conduct a secondary instance segmentation annotation on the nuScenes, named nuInsSeg, to encourage further research on multimodal perception tasks. Extensive experiments on the nuInsSeg, as well as the large-scale Waymo, show that LWSIS can substantially improve existing weakly supervised segmentation models by only involving 3D data during training. Additionally, LWSIS can also be incorporated into 3D object detectors like PointPainting to boost the 3D detection performance for free. The code and dataset are available at https://github.com/Serenos/LWSIS.
Analyzing Infrastructure LiDAR Placement with Realistic LiDAR
Nov 29, 2022



Recently, Vehicle-to-Everything(V2X) cooperative perception has attracted increasing attention. Infrastructure sensors play a critical role in this research field, however, how to find the optimal placement of infrastructure sensors is rarely studied. In this paper, we investigate the problem of infrastructure sensor placement and propose a pipeline that can efficiently and effectively find optimal installation positions for infrastructure sensors in a realistic simulated environment. To better simulate and evaluate LiDAR placement, we establish a Realistic LiDAR Simulation library that can simulate the unique characteristics of different popular LiDARs and produce high-fidelity LiDAR point clouds in the CARLA simulator. Through simulating point cloud data in different LiDAR placements, we can evaluate the perception accuracy of these placements using multiple detection models. Then, we analyze the correlation between the point cloud distribution and perception accuracy by calculating the density and uniformity of regions of interest. Experiments show that the placement of infrastructure LiDAR can heavily affect the accuracy of perception. We also analyze the correlation between perception performance in the region of interest and LiDAR point cloud distribution and validate that density and uniformity can be indicators of performance.
Online LiDAR-Camera Extrinsic Parameters Self-checking
Oct 19, 2022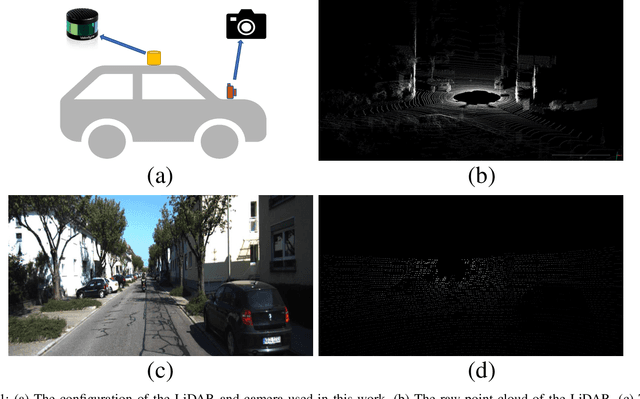
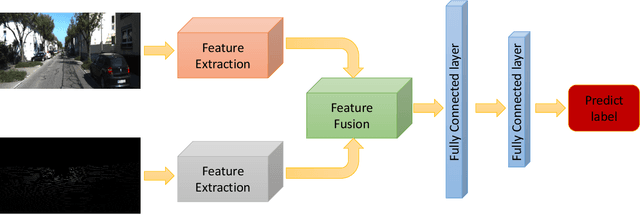

With the development of neural networks and the increasing popularity of automatic driving, the calibration of the LiDAR and the camera has attracted more and more attention. This calibration task is multi-modal, where the rich color and texture information captured by the camera and the accurate three-dimensional spatial information from the LiDAR is incredibly significant for downstream tasks. Current research interests mainly focus on obtaining accurate calibration results through information fusion. However, they seldom analyze whether the calibrated results are correct or not, which could be of significant importance in real-world applications. For example, in large-scale production, the LiDARs and the cameras of each smart car have to get well-calibrated as the car leaves the production line, while in the rest of the car life period, the poses of the LiDARs and cameras should also get continually supervised to ensure the security. To this end, this paper proposes a self-checking algorithm to judge whether the extrinsic parameters are well-calibrated by introducing a binary classification network based on the fused information from the camera and the LiDAR. Moreover, since there is no such dataset for the task in this work, we further generate a new dataset branch from the KITTI dataset tailored for the task. Our experiments on the proposed dataset branch demonstrate the performance of our method. To the best of our knowledge, this is the first work to address the significance of continually checking the calibrated extrinsic parameters for autonomous driving. The code is open-sourced on the Github website at https://github.com/OpenCalib/LiDAR2camera_self-check.