 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Evidence Refinement for Open-domain Multimodal Retrieval Question Answering
Oct 15, 2023



Pre-trained multimodal models have achieved significant success in retrieval-based question answering. However, current multimodal retrieval question-answering models face two main challenges. Firstly, utilizing compressed evidence features as input to the model results in the loss of fine-grained information within the evidence. Secondly, a gap exists between the feature extraction of evidence and the question, which hinders the model from effectively extracting critical features from the evidence based on the given question. We propose a two-stage framework for evidence retrieval and question-answering to alleviate these issues. First and foremost, we propose a progressive evidence refinement strategy for selecting crucial evidence. This strategy employs an iterative evidence retrieval approach to uncover the logical sequence among the evidence pieces. It incorporates two rounds of filtering to optimize the solution space, thus further ensuring temporal efficiency. Subsequently, we introduce a semi-supervised contrastive learning training strategy based on negative samples to expand the scope of the question domain, allowing for a more thorough exploration of latent knowledge within known samples. Finally, in order to mitigate the loss of fine-grained information, we devise a multi-turn retrieval and question-answering strategy to handle multimodal inputs. This strategy involves incorporating multimodal evidence directly into the model as part of the historical dialogue and question. Meanwhile, we leverage a cross-modal attention mechanism to capture the underlying connections between the evidence and the question, and the answer is generated through a decoding generation approach. We validate the model's effectiveness through extensive experiments, achieving outstanding performance on WebQA and MultimodelQA benchmark tests.
Homogeneous Multi-modal Feature Fusion and Interaction for 3D Object Detection
Oct 18, 2022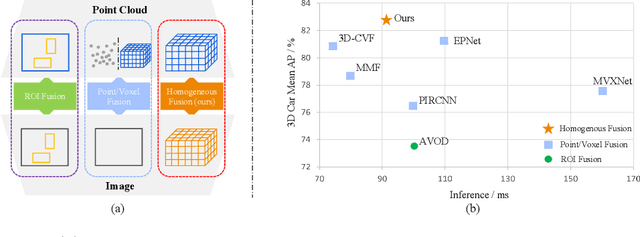
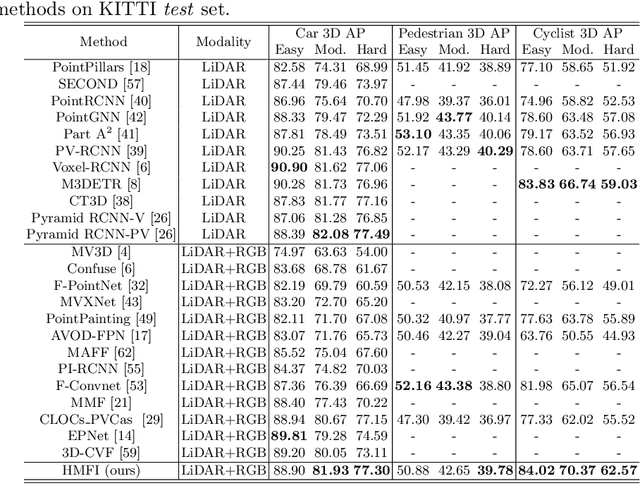
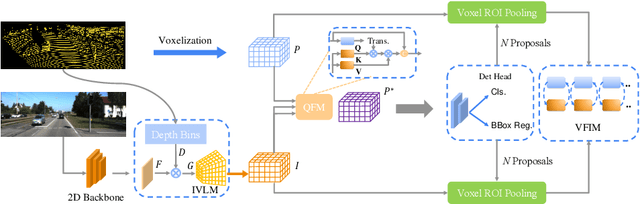
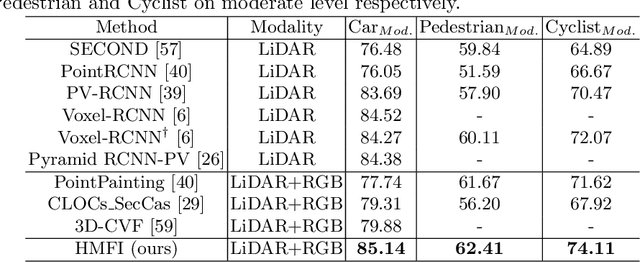
Multi-modal 3D object detection has been an active research topic in autonomous driving. Nevertheless, it is non-trivial to explore the cross-modal feature fusion between sparse 3D points and dense 2D pixels. Recent approaches either fuse the image features with the point cloud features that are projected onto the 2D image plane or combine the sparse point cloud with dense image pixels. These fusion approaches often suffer from severe information loss, thus causing sub-optimal performance. To address these problems, we construct the homogeneous structure between the point cloud and images to avoid projective information loss by transforming the camera features into the LiDAR 3D space. In this paper, we propose a homogeneous multi-modal feature fusion and interaction method (HMFI) for 3D object detection. Specifically, we first design an image voxel lifter module (IVLM) to lift 2D image features into the 3D space and generate homogeneous image voxel features. Then, we fuse the voxelized point cloud features with the image features from different regions by introducing the self-attention based query fusion mechanism (QFM). Next, we propose a voxel feature interaction module (VFIM) to enforce the consistency of semantic information from identical objects in the homogeneous point cloud and image voxel representations, which can provide object-level alignment guidance for cross-modal feature fusion and strengthen the discriminative ability in complex backgrounds. We conduct extensive experiments on the KITTI and Waymo Open Dataset, and the proposed HMFI achieves better performance compared with the state-of-the-art multi-modal methods. Particularly, for the 3D detection of cyclist on the KITTI benchmark, HMFI surpasses all the published algorithms by a large margin.
Progressive Scene Text Erasing with Self-Supervision
Jul 23, 2022


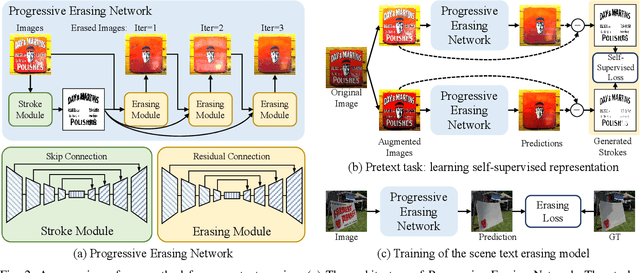
Scene text erasing seeks to erase text contents from scene images and current state-of-the-art text erasing models are trained on large-scale synthetic data. Although data synthetic engines can provide vast amounts of annotated training samples, there are differences between synthetic and real-world data. In this paper, we employ self-supervision for feature representation on unlabeled real-world scene text images. A novel pretext task is designed to keep consistent among text stroke masks of image variants. We design the Progressive Erasing Network in order to remove residual texts. The scene text is erased progressively by leveraging the intermediate generated results which provide the foundation for subsequent higher quality results. Experiments show that our method significantly improves the generalization of the text erasing task and achieves state-of-the-art performance on public benchmarks.
Cross-Domain Document Layout Analysis via Unsupervised Document Style Guide
Jan 24, 2022
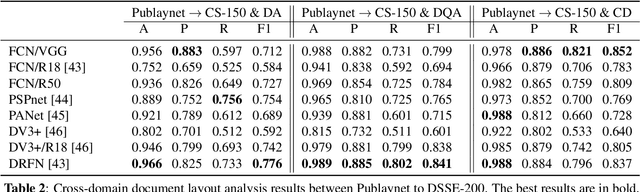
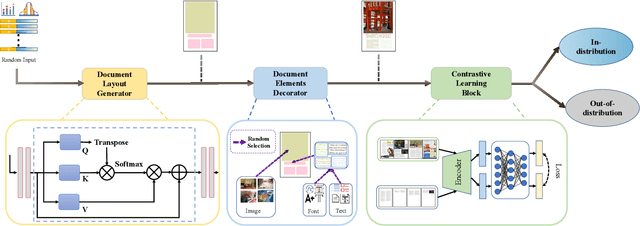
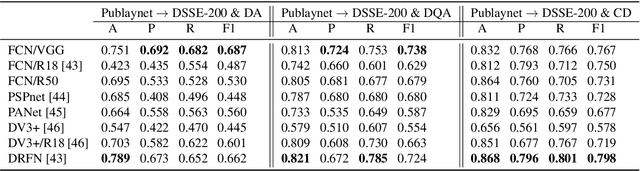
The document layout analysis (DLA) aims to decompose document images into high-level semantic areas (i.e., figures, tables, texts, and background). Creating a DLA framework with strong generalization capabilities is a challenge due to document objects are diversity in layout, size, aspect ratio, texture, etc. Many researchers devoted this challenge by synthesizing data to build large training sets. However, the synthetic training data has different styles and erratic quality. Besides, there is a large gap between the source data and the target data. In this paper, we propose an unsupervised cross-domain DLA framework based on document style guidance. We integrated the document quality assessment and the document cross-domain analysis into a unified framework. Our framework is composed of three components, Document Layout Generator (GLD), Document Elements Decorator(GED), and Document Style Discriminator(DSD). The GLD is used to document layout generates, the GED is used to document layout elements fill, and the DSD is used to document quality assessment and cross-domain guidance. First, we apply GLD to predict the positions of the generated document. Then, we design a novel algorithm based on aesthetic guidance to fill the document positions. Finally, we use contrastive learning to evaluate the quality assessment of the document. Besides, we design a new strategy to change the document quality assessment component into a document cross-domain style guide component. Our framework is an unsupervised document layout analysis framework. We have proved through numerous experiments that our proposed method has achieved remarkable performance.
Document Layout Analysis with Aesthetic-Guided Image Augmentation
Nov 27, 2021
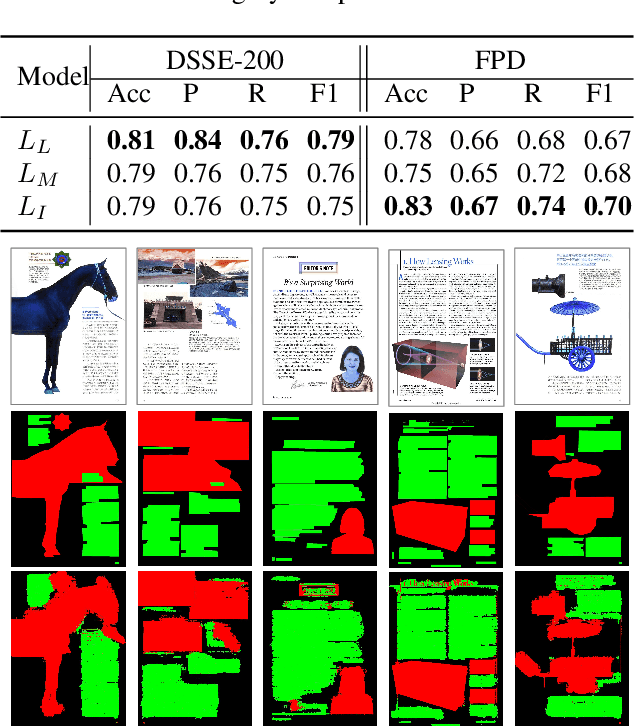
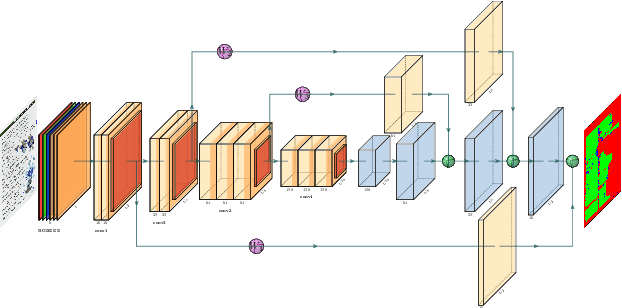
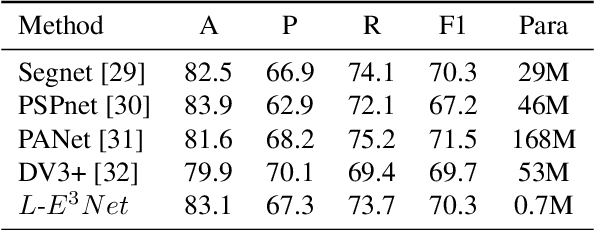
Document layout analysis (DLA) plays an important role in information extraction and document understanding. At present, document layout analysis has reached a milestone achievement, however, document layout analysis of non-Manhattan is still a challenge. In this paper, we propose an image layer modeling method to tackle this challenge. To measure the proposed image layer modeling method, we propose a manually-labeled non-Manhattan layout fine-grained segmentation dataset named FPD. As far as we know, FPD is the first manually-labeled non-Manhattan layout fine-grained segmentation dataset. To effectively extract fine-grained features of documents, we propose an edge embedding network named L-E^3Net. Experimental results prove that our proposed image layer modeling method can better deal with the fine-grained segmented document of the non-Manhattan layout.
Human-In-The-Loop Document Layout Analysis
Aug 04, 2021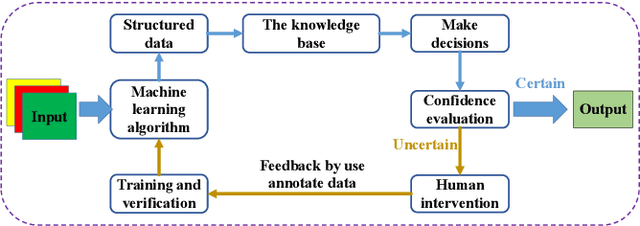
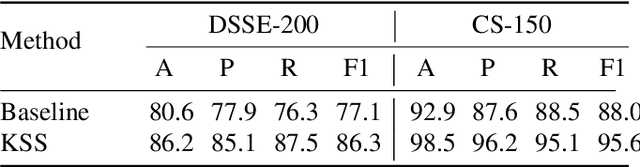
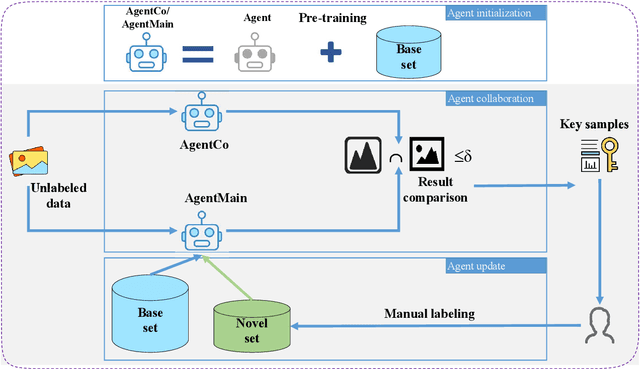
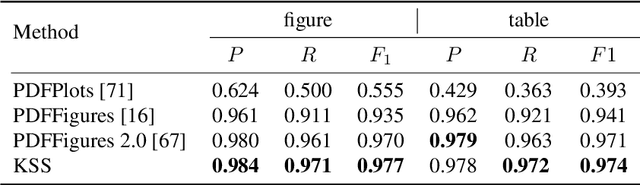
Document layout analysis (DLA) aims to divide a document image into different types of regions. DLA plays an important role in the document content understanding and information extraction systems. Exploring a method that can use less data for effective training contributes to the development of DLA. We consider a Human-in-the-loop (HITL) collaborative intelligence in the DLA. Our approach was inspired by the fact that the HITL push the model to learn from the unknown problems by adding a small amount of data based on knowledge. The HITL select key samples by using confidence. However, using confidence to find key samples is not suitable for DLA tasks. We propose the Key Samples Selection (KSS) method to find key samples in high-level tasks (semantic segmentation) more accurately through agent collaboration, effectively reducing costs. Once selected, these key samples are passed to human beings for active labeling, then the model will be updated with the labeled samples. Hence, we revisited the learning system from reinforcement learning and designed a sample-based agent update strategy, which effectively improves the agent's ability to accept new samples. It achieves significant improvement results in two benchmarks (DSSE-200 (from 77.1% to 86.3%) and CS-150 (from 88.0% to 95.6%)) by using 10% of labeled data.
A Survey of Human-in-the-loop for Machine Learning
Aug 02, 2021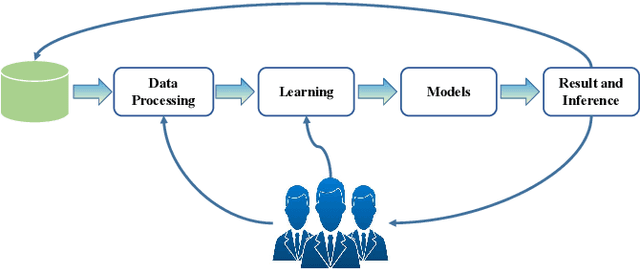
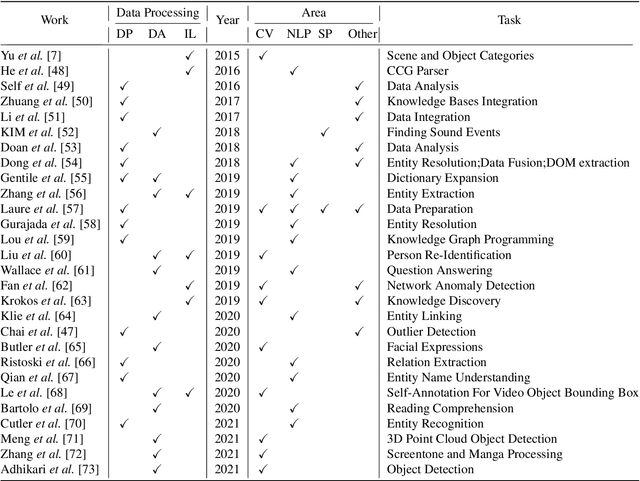
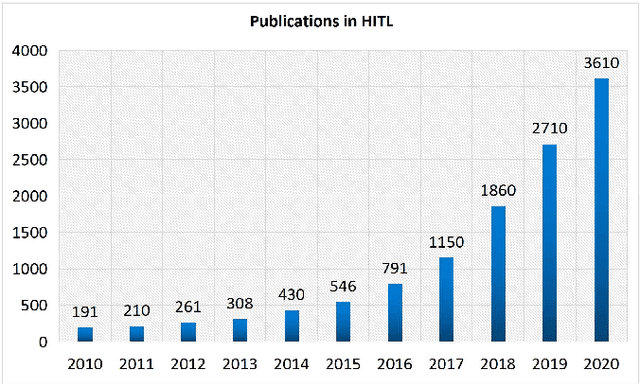

Human-in-the-loop aims to train an accurate prediction model with minimum cost by integrating human knowledge and experience. Humans can provide training data for machine learning applications and directly accomplish some tasks that are hard for computers in the pipeline with the help of machine-based approaches. In this paper, we survey existing works on human-in-the-loop from a data perspective and classify them into three categories with a progressive relationship: (1) the work of improving model performance from data processing, (2) the work of improving model performance through interventional model training, and (3) the design of the system independent human-in-the-loop. Using the above categorization, we summarize major approaches in the field, along with their technical strengths/ weaknesses, we have simple classification and discussion in natural language processing, computer vision, and others. Besides, we provide some open challenges and opportunities. This survey intends to provide a high-level summarization for human-in-the-loop and motivates interested readers to consider approaches for designing effective human-in-the-loop solutions.
Scene Text Recognition with Temporal Convolutional Encoder
Nov 04, 2019

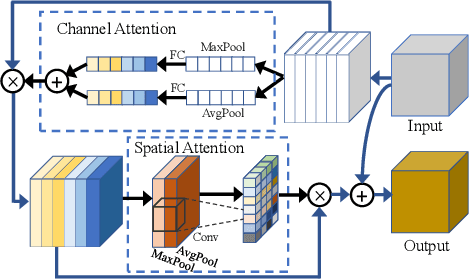
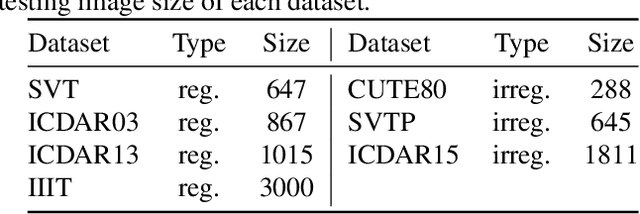
Texts from scene images typically consist of several characters and exhibit a characteristic sequence structure. Existing methods capture the structure with the sequence-to-sequence models by an encoder to have the visual representations and then a decoder to translate the features into the label sequence. In this paper, we study text recognition framework by considering the long-term temporal dependencies in the encoder stage. We demonstrate that the proposed Temporal Convolutional Encoder with increased sequential extents improves the accuracy of text recognition. We also study the impact of different attention modules in convolutional blocks for learning accurate text representations. We conduct comparisons on seven datasets and the experiments demonstrate the effectiveness of our proposed approach.