 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenMotion: Decoupled Motion Control via Token Disentanglement for Human-centric Video Generation
Apr 11, 2025Human-centric motion control in video generation remains a critical challenge, particularly when jointly controlling camera movements and human poses in scenarios like the iconic Grammy Glambot moment. While recent video diffusion models have made significant progress, existing approaches struggle with limited motion representations and inadequate integration of camera and human motion controls. In this work, we present TokenMotion, the first DiT-based video diffusion framework that enables fine-grained control over camera motion, human motion, and their joint interaction. We represent camera trajectories and human poses as spatio-temporal tokens to enable local control granularity. Our approach introduces a unified modeling framework utilizing a decouple-and-fuse strategy, bridged by a human-aware dynamic mask that effectively handles the spatially-and-temporally varying nature of combined motion signals. Through extensive experiments, we demonstrate TokenMotion's effectiveness across both text-to-video and image-to-video paradigms, consistently outperforming current state-of-the-art methods in human-centric motion control tasks. Our work represents a significant advancement in controllable video generation, with particular relevance for creative production applications.
Catch Missing Details: Image Reconstruction with Frequency Augmented Variational Autoencoder
May 04, 2023The popular VQ-VAE models reconstruct images through learning a discrete codebook but suffer from a significant issue in the rapid quality degradation of image reconstruction as the compression rate rises. One major reason is that a higher compression rate induces more loss of visual signals on the higher frequency spectrum which reflect the details on pixel space. In this paper, a Frequency Complement Module (FCM) architecture is proposed to capture the missing frequency information for enhancing reconstruction quality. The FCM can be easily incorporated into the VQ-VAE structure, and we refer to the new model as Frequency Augmented VAE (FA-VAE). In addition, a Dynamic Spectrum Loss (DSL) is introduced to guide the FCMs to balance between various frequencies dynamically for optimal reconstruction. FA-VAE is further extended to the text-to-image synthesis task, and a Cross-attention Autoregressive Transformer (CAT) is proposed to obtain more precise semantic attributes in texts. Extensive reconstruction experiments with different compression rates are conducted on several benchmark datasets, and the results demonstrate that the proposed FA-VAE is able to restore more faithfully the details compared to SOTA methods. CAT also shows improved generation quality with better image-text semantic alignment.
VideoXum: Cross-modal Visual and Textural Summarization of Videos
Mar 21, 2023



Video summarization aims to distill the most important information from a source video to produce either an abridged clip or a textual narrative. Traditionally, different methods have been proposed depending on whether the output is a video or text, thus ignoring the correlation between the two semantically related tasks of visual summarization and textual summarization. We propose a new joint video and text summarization task. The goal is to generate both a shortened video clip along with the corresponding textual summary from a long video, collectively referred to as a cross-modal summary. The generated shortened video clip and text narratives should be semantically well aligned. To this end, we first build a large-scale human-annotated dataset -- VideoXum (X refers to different modalities). The dataset is reannotated based on ActivityNet. After we filter out the videos that do not meet the length requirements, 14,001 long videos remain in our new dataset. Each video in our reannotated dataset has human-annotated video summaries and the corresponding narrative summaries. We then design a novel end-to-end model -- VTSUM-BILP to address the challenges of our proposed task. Moreover, we propose a new metric called VT-CLIPScore to help evaluate the semantic consistency of cross-modality summary. The proposed model achieves promising performance on this new task and establishes a benchmark for future research.
ROIFormer: Semantic-Aware Region of Interest Transformer for Efficient Self-Supervised Monocular Depth Estimation
Dec 16, 2022The exploration of mutual-benefit cross-domains has shown great potential toward accurate self-supervised depth estimation. In this work, we revisit feature fusion between depth and semantic information and propose an efficient local adaptive attention method for geometric aware representation enhancement. Instead of building global connections or deforming attention across the feature space without restraint, we bound the spatial interaction within a learnable region of interest. In particular, we leverage geometric cues from semantic information to learn local adaptive bounding boxes to guide unsupervised feature aggregation. The local areas preclude most irrelevant reference points from attention space, yielding more selective feature learning and faster convergence. We naturally extend the paradigm into a multi-head and hierarchic way to enable the information distillation in different semantic levels and improve the feature discriminative ability for fine-grained depth estimation. Extensive experiments on the KITTI dataset show that our proposed method establishes a new state-of-the-art in self-supervised monocular depth estimation task, demonstrating the effectiveness of our approach over former Transformer variants.
A Dual Modality Approach For Multi-Label Classification
Aug 19, 2022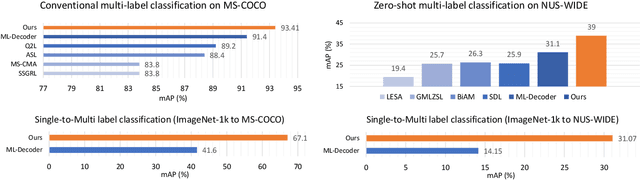
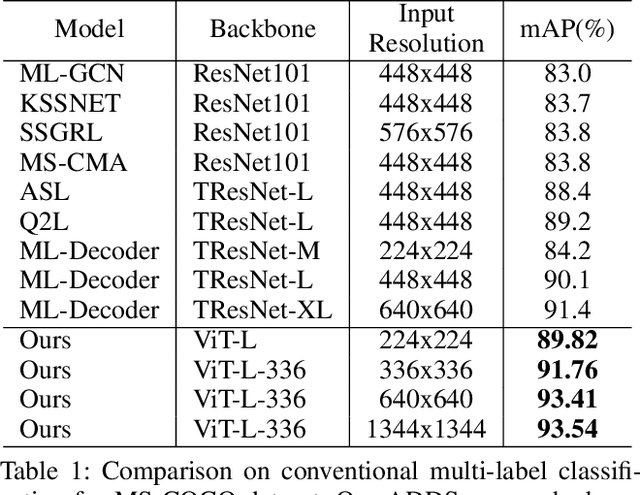
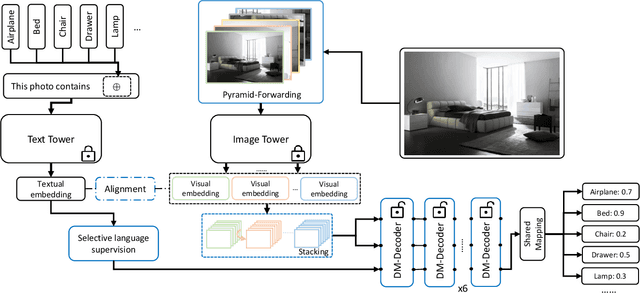
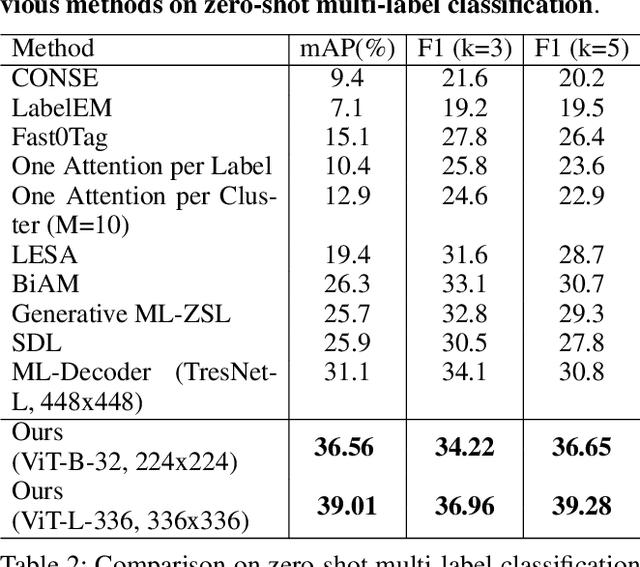
In computer vision, multi-label classification, including zero-shot multi-label classification are important tasks with many real-world applications. In this paper, we propose a novel algorithm, Aligned Dual moDality ClaSsifier (ADDS), which includes a Dual-Modal decoder (DM-decoder) with alignment between visual and textual features, for multi-label classification tasks. Moreover, we design a simple and yet effective method called Pyramid-Forwarding to enhance the performance for inputs with high resolutions. Extensive experiments conducted on standard multi-label benchmark datasets, MS-COCO and NUS-WIDE, demonstrate that our approach significantly outperforms previous methods and provides state-of-the-art performance for conventional multi-label classification, zero-shot multi-label classification, and an extreme case called single-to-multi label classification where models trained on single-label datasets (ImageNet-1k, ImageNet-21k) are tested on multi-label ones (MS-COCO and NUS-WIDE). We also analyze how visual-textual alignment contributes to the proposed approach, validate the significance of the DM-decoder, and demonstrate the effectiveness of Pyramid-Forwarding on vision transformer.
Dual-Flattening Transformers through Decomposed Row and Column Queries for Semantic Segmentation
Jan 22, 2022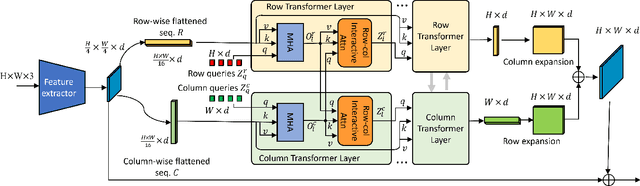

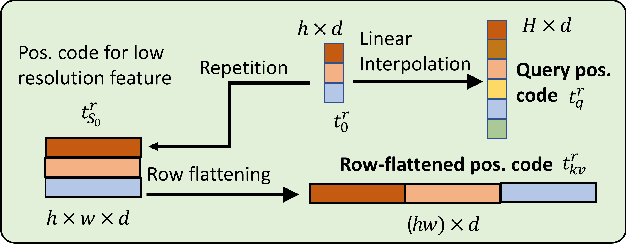
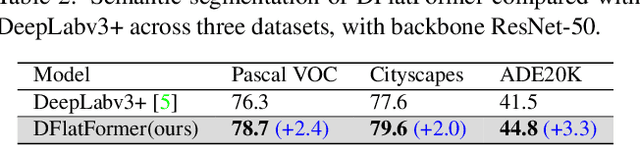
It is critical to obtain high resolution features with long range dependency for dense prediction tasks such as semantic segmentation. To generate high-resolution output of size $H\times W$ from a low-resolution feature map of size $h\times w$ ($hw\ll HW$), a naive dense transformer incurs an intractable complexity of $\mathcal{O}(hwHW)$, limiting its application on high-resolution dense prediction. We propose a Dual-Flattening Transformer (DFlatFormer) to enable high-resolution output by reducing complexity to $\mathcal{O}(hw(H+W))$ that is multiple orders of magnitude smaller than the naive dense transformer. Decomposed queries are presented to retrieve row and column attentions tractably through separate transformers, and their outputs are combined to form a dense feature map at high resolution. To this end, the input sequence fed from an encoder is row-wise and column-wise flattened to align with decomposed queries by preserving their row and column structures, respectively. Row and column transformers also interact with each other to capture their mutual attentions with the spatial crossings between rows and columns. We also propose to perform attentions through efficient grouping and pooling to further reduce the model complexity. Extensive experiments on ADE20K and Cityscapes datasets demonstrate the superiority of the proposed dual-flattening transformer architecture with higher mIoUs.
GCF-Net: Gated Clip Fusion Network for Video Action Recognition
Feb 02, 2021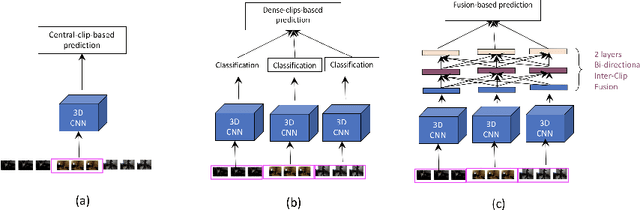
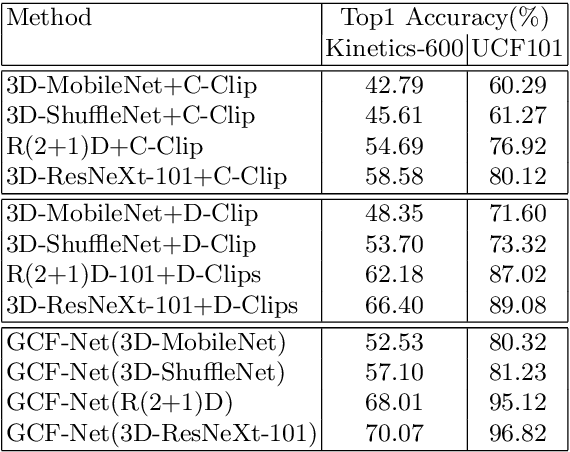
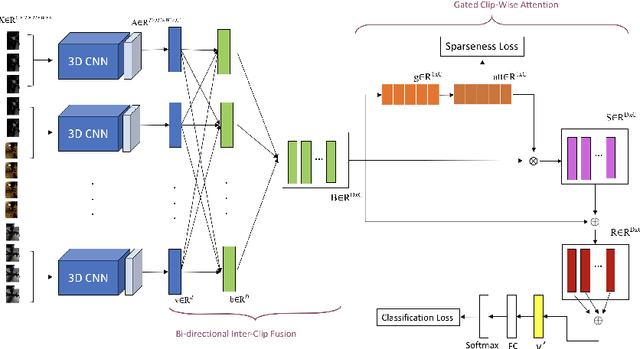

In recent years, most of the accuracy gains for video action recognition have come from the newly designed CNN architectures (e.g., 3D-CNNs). These models are trained by applying a deep CNN on single clip of fixed temporal length. Since each video segment are processed by the 3D-CNN module separately, the corresponding clip descriptor is local and the inter-clip relationships are inherently implicit. Common method that directly averages the clip-level outputs as a video-level prediction is prone to fail due to the lack of mechanism that can extract and integrate relevant information to represent the video. In this paper, we introduce the Gated Clip Fusion Network (GCF-Net) that can greatly boost the existing video action classifiers with the cost of a tiny computation overhead. The GCF-Net explicitly models the inter-dependencies between video clips to strengthen the receptive field of local clip descriptors. Furthermore, the importance of each clip to an action event is calculated and a relevant subset of clips is selected accordingly for a video-level analysis. On a large benchmark dataset (Kinetics-600), the proposed GCF-Net elevates the accuracy of existing action classifiers by 11.49% (based on central clip) and 3.67% (based on densely sampled clips) respectively.