 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbductive Logical Reasoning on Knowledge Graphs
Dec 25, 2023



Abductive reasoning is logical reasoning that makes educated guesses to infer the most likely reasons to explain the observations. However, the abductive logical reasoning over knowledge graphs (KGs) is underexplored in KG literature. In this paper, we initially and formally raise the task of abductive logical reasoning over KGs, which involves inferring the most probable logic hypothesis from the KGs to explain an observed entity set. Traditional approaches use symbolic methods, like searching, to tackle the knowledge graph problem. However, the symbolic methods are unsuitable for this task, because the KGs are naturally incomplete, and the logical hypotheses can be complex with multiple variables and relations. To address these issues, we propose a generative approach to create logical expressions based on observations. First, we sample hypothesis-observation pairs from the KG and use supervised training to train a generative model that generates hypotheses from observations. Since supervised learning only minimizes structural differences between generated and reference hypotheses, higher structural similarity does not guarantee a better explanation for observations. To tackle this issue, we introduce the Reinforcement Learning from the Knowledge Graph (RLF-KG) method, which minimizes the differences between observations and conclusions drawn from the generated hypotheses according to the KG. Experimental results demonstrate that transformer-based generative models can generate logical explanations robustly and efficiently. Moreover, with the assistance of RLF-KG, the generated hypothesis can provide better explanations for the observations, and the method of supervised learning with RLF-KG achieves state-of-the-art results on abductive knowledge graph reasoning on three widely used KGs.
Unsupervised Candidate Answer Extraction through Differentiable Masker-Reconstructor Model
Oct 19, 2023


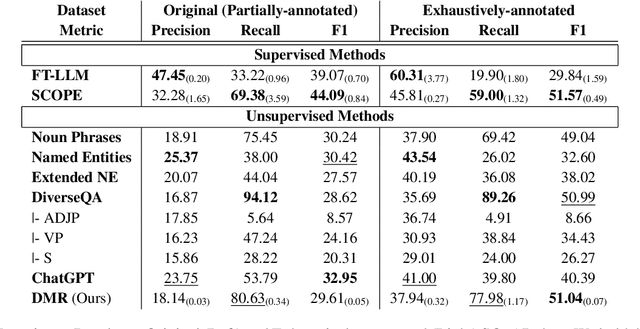
Question generation is a widely used data augmentation approach with extensive applications, and extracting qualified candidate answers from context passages is a critical step for most question generation systems. However, existing methods for candidate answer extraction are reliant on linguistic rules or annotated data that face the partial annotation issue and challenges in generalization. To overcome these limitations, we propose a novel unsupervised candidate answer extraction approach that leverages the inherent structure of context passages through a Differentiable Masker-Reconstructor (DMR) Model with the enforcement of self-consistency for picking up salient information tokens. We curated two datasets with exhaustively-annotated answers and benchmark a comprehensive set of supervised and unsupervised candidate answer extraction methods. We demonstrate the effectiveness of the DMR model by showing its performance is superior among unsupervised methods and comparable to supervised methods.
Beyond Fairness: Age-Harmless Parkinson's Detection via Voice
Sep 23, 2023



Parkinson's disease (PD), a neurodegenerative disorder, often manifests as speech and voice dysfunction. While utilizing voice data for PD detection has great potential in clinical applications, the widely used deep learning models currently have fairness issues regarding different ages of onset. These deep models perform well for the elderly group (age $>$ 55) but are less accurate for the young group (age $\leq$ 55). Through our investigation, the discrepancy between the elderly and the young arises due to 1) an imbalanced dataset and 2) the milder symptoms often seen in early-onset patients. However, traditional debiasing methods are impractical as they typically impair the prediction accuracy for the majority group while minimizing the discrepancy. To address this issue, we present a new debiasing method using GradCAM-based feature masking combined with ensemble models, ensuring that neither fairness nor accuracy is compromised. Specifically, the GradCAM-based feature masking selectively obscures age-related features in the input voice data while preserving essential information for PD detection. The ensemble models further improve the prediction accuracy for the minority (young group). Our approach effectively improves detection accuracy for early-onset patients without sacrificing performance for the elderly group. Additionally, we propose a two-step detection strategy for the young group, offering a practical risk assessment for potential early-onset PD patients.
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022



Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.
MSSPN: Automatic First Arrival Picking using Multi-Stage Segmentation Picking Network
Sep 07, 2022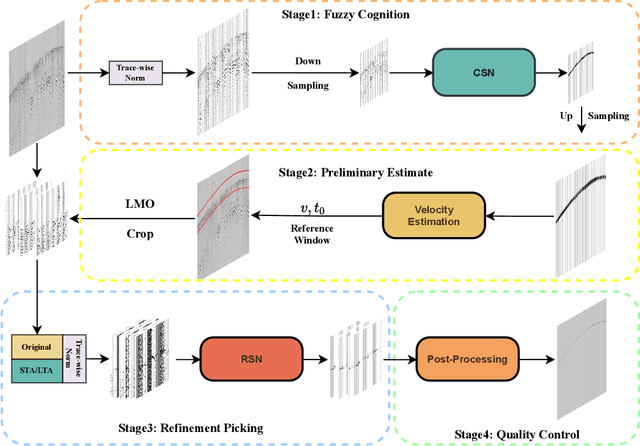

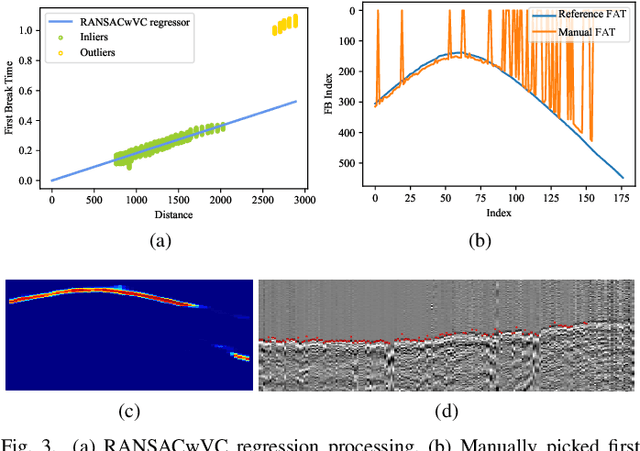
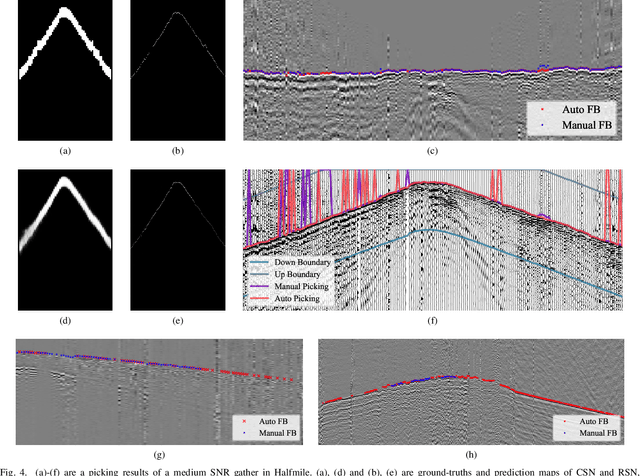
Picking the first arrival times of prestack gathers is called First Arrival Time (FAT) picking, which is an indispensable step in seismic data processing, and is mainly solved manually in the past. With the current increasing density of seismic data collection, the efficiency of manual picking has been unable to meet the actual needs. Therefore, automatic picking methods have been greatly developed in recent decades, especially those based on deep learning. However, few of the current supervised deep learning-based method can avoid the dependence on labeled samples. Besides, since the gather data is a set of signals which are greatly different from the natural images, it is difficult for the current method to solve the FAT picking problem in case of a low Signal to Noise Ratio (SNR). In this paper, for hard rock seismic gather data, we propose a Multi-Stage Segmentation Pickup Network (MSSPN), which solves the generalization problem across worksites and the picking problem in the case of low SNR. In MSSPN, there are four sub-models to simulate the manually picking processing, which is assumed to four stages from coarse to fine. Experiments on seven field datasets with different qualities show that our MSSPN outperforms benchmarks by a large margin.Particularly, our method can achieve more than 90\% accurate picking across worksites in the case of medium and high SNRs, and even fine-tuned model can achieve 88\% accurate picking of the dataset with low SNR.
Auto-PINN: Understanding and Optimizing Physics-Informed Neural Architecture
May 27, 2022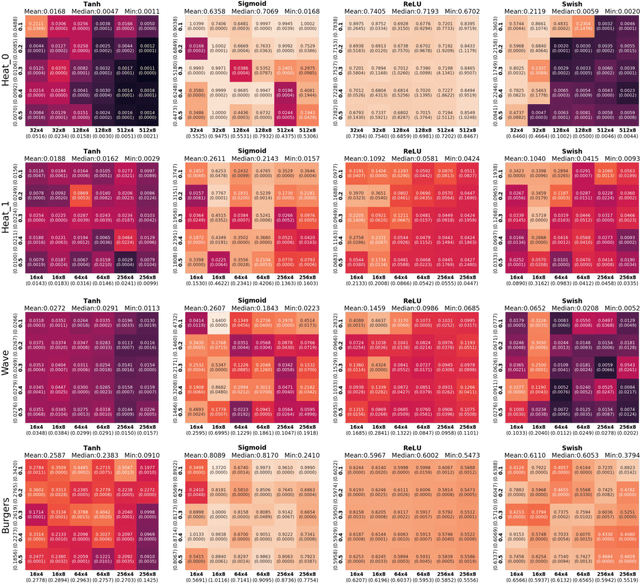
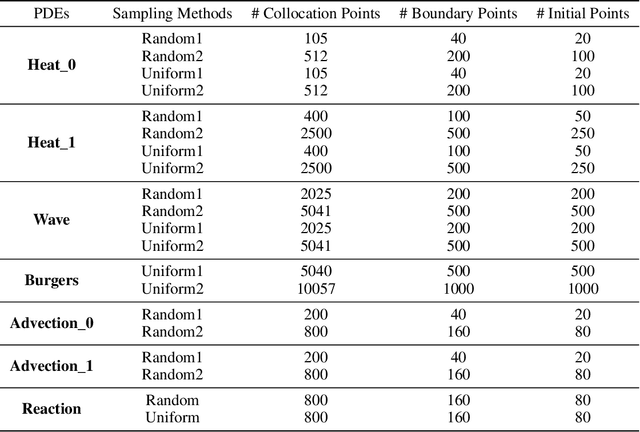
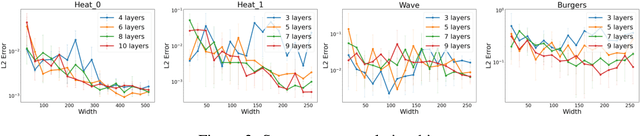

Physics-informed neural networks (PINNs) are revolutionizing science and engineering practice by bringing together the power of deep learning to bear on scientific computation. In forward modeling problems, PINNs are meshless partial differential equation (PDE) solvers that can handle irregular, high-dimensional physical domains. Naturally, the neural architecture hyperparameters have a large impact on the efficiency and accuracy of the PINN solver. However, this remains an open and challenging problem because of the large search space and the difficulty of identifying a proper search objective for PDEs. Here, we propose Auto-PINN, the first systematic, automated hyperparameter optimization approach for PINNs, which employs Neural Architecture Search (NAS) techniques to PINN design. Auto-PINN avoids manually or exhaustively searching the hyperparameter space associated with PINNs. A comprehensive set of pre-experiments using standard PDE benchmarks allows us to probe the structure-performance relationship in PINNs. We find that the different hyperparameters can be decoupled, and that the training loss function of PINNs is a good search objective. Comparison experiments with baseline methods demonstrate that Auto-PINN produces neural architectures with superior stability and accuracy over alternative baselines.
House Price Valuation Model Based on Geographically Neural Network Weighted Regression: The Case Study of Shenzhen, China
Feb 09, 2022
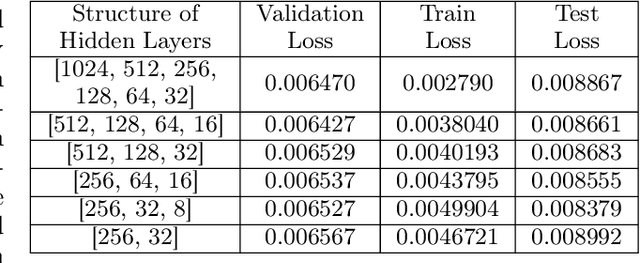
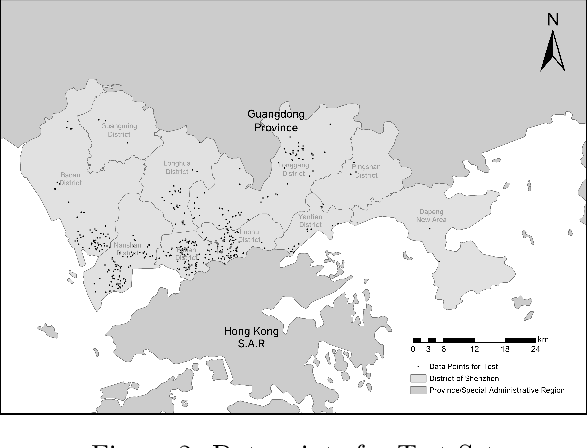

Confronted with the spatial heterogeneity of real estate market, some traditional research utilized Geographically Weighted Regression (GWR) to estimate the house price. However, its kernel function is non-linear, elusive, and complex to opt bandwidth, the predictive power could also be improved. Consequently, a novel technique, Geographical Neural Network Weighted Regression (GNNWR), has been applied to improve the accuracy of real estate appraisal with the help of neural networks. Based on Shenzhen house price dataset, this work conspicuously captures the weight distribution of different variants at Shenzhen real estate market, which GWR is difficult to materialize. Moreover, we focus on the performance of GNNWR, verify its robustness and superiority, refine the experiment process with 10-fold cross-validation, extend its application area from natural to socioeconomic geospatial data. It's a practical and trenchant way to assess house price, and we demonstrate the effectiveness of GNNWR on a complex socioeconomic dataset.
AutoVideo: An Automated Video Action Recognition System
Aug 10, 2021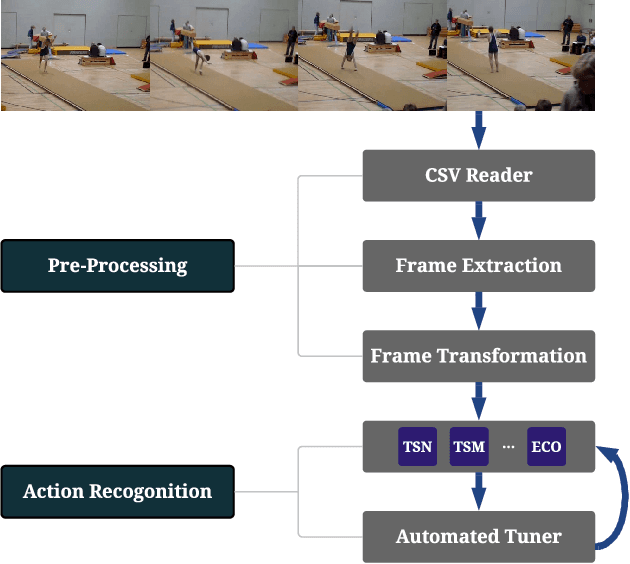

Action recognition is a crucial task for video understanding. In this paper, we present AutoVideo, a Python system for automated video action recognition. It currently supports seven action recognition algorithms and various pre-processing modules. Unlike the existing libraries that only provide model zoos, AutoVideo is built with the standard pipeline language. The basic building block is primitive, which wraps a pre-processing module or an algorithm with some hyperparameters. AutoVideo is highly modular and extendable. It can be easily combined with AutoML searchers. The pipeline language is quite general so that we can easily enrich AutoVideo with algorithms for various other video-related tasks in the future. AutoVideo is released under MIT license at https://github.com/datamllab/autovideo
Fast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021

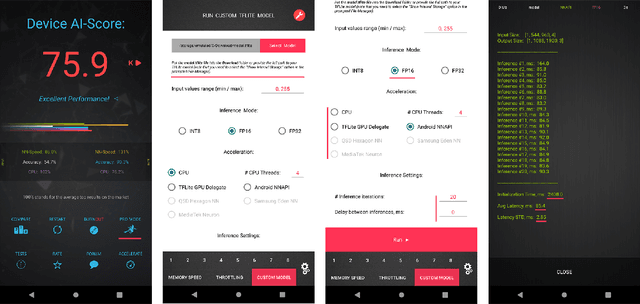

Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.
MFIF-GAN: A New Generative Adversarial Network for Multi-Focus Image Fusion
Sep 22, 2020
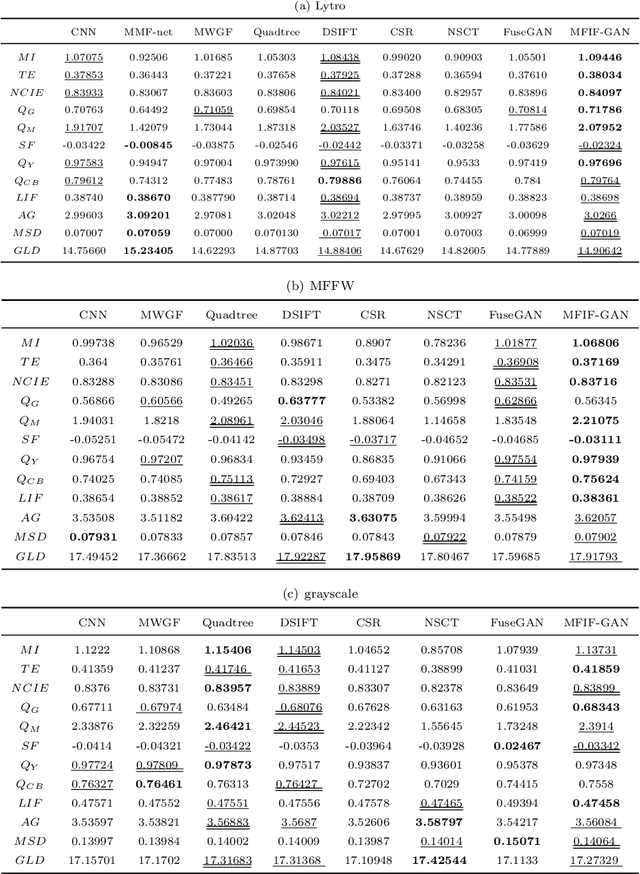

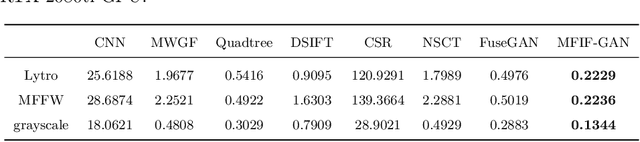
Multi-Focus Image Fusion (MFIF) is one of the promising techniques to obtain all-in-focus images to meet people's visual needs and it is a precondition of other computer vision tasks. One of the research trends of MFIF is to solve the defocus spread effect (DSE) around the focus/defocus boundary (FDB). In this paper, we present a novel generative adversarial network termed MFIF-GAN to translate multi-focus images into focus maps and to get the all-in-focus images further. The Squeeze and Excitation Residual Network (SE-ResNet) module as an attention mechanism is employed in the network. During the training, we propose reconstruction and gradient regularization loss functions to guarantee the accuracy of generated focus maps. In addition, by combining the prior knowledge of training conditon, this network is trained on a synthetic dataset with DSE based on an {\alpha}-matte model. A series of experimental results demonstrate that the MFIF-GAN is superior to several representative state-of-the-art (SOTA) algorithms in visual perception, quantitative analysis as well as efficiency.