 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalkCuts: A Large-Scale Dataset for Multi-Shot Human Speech Video Generation
Oct 08, 2025In this work, we present TalkCuts, a large-scale dataset designed to facilitate the study of multi-shot human speech video generation. Unlike existing datasets that focus on single-shot, static viewpoints, TalkCuts offers 164k clips totaling over 500 hours of high-quality human speech videos with diverse camera shots, including close-up, half-body, and full-body views. The dataset includes detailed textual descriptions, 2D keypoints and 3D SMPL-X motion annotations, covering over 10k identities, enabling multimodal learning and evaluation. As a first attempt to showcase the value of the dataset, we present Orator, an LLM-guided multi-modal generation framework as a simple baseline, where the language model functions as a multi-faceted director, orchestrating detailed specifications for camera transitions, speaker gesticulations, and vocal modulation. This architecture enables the synthesis of coherent long-form videos through our integrated multi-modal video generation module. Extensive experiments in both pose-guided and audio-driven settings show that training on TalkCuts significantly enhances the cinematographic coherence and visual appeal of generated multi-shot speech videos. We believe TalkCuts provides a strong foundation for future work in controllable, multi-shot speech video generation and broader multimodal learning.
UniMuMo: Unified Text, Music and Motion Generation
Oct 06, 2024



We introduce UniMuMo, a unified multimodal model capable of taking arbitrary text, music, and motion data as input conditions to generate outputs across all three modalities. To address the lack of time-synchronized data, we align unpaired music and motion data based on rhythmic patterns to leverage existing large-scale music-only and motion-only datasets. By converting music, motion, and text into token-based representation, our model bridges these modalities through a unified encoder-decoder transformer architecture. To support multiple generation tasks within a single framework, we introduce several architectural improvements. We propose encoding motion with a music codebook, mapping motion into the same feature space as music. We introduce a music-motion parallel generation scheme that unifies all music and motion generation tasks into a single transformer decoder architecture with a single training task of music-motion joint generation. Moreover, the model is designed by fine-tuning existing pre-trained single-modality models, significantly reducing computational demands. Extensive experiments demonstrate that UniMuMo achieves competitive results on all unidirectional generation benchmarks across music, motion, and text modalities. Quantitative results are available in the \href{https://hanyangclarence.github.io/unimumo_demo/}{project page}.
RapVerse: Coherent Vocals and Whole-Body Motions Generations from Text
May 30, 2024



In this work, we introduce a challenging task for simultaneously generating 3D holistic body motions and singing vocals directly from textual lyrics inputs, advancing beyond existing works that typically address these two modalities in isolation. To facilitate this, we first collect the RapVerse dataset, a large dataset containing synchronous rapping vocals, lyrics, and high-quality 3D holistic body meshes. With the RapVerse dataset, we investigate the extent to which scaling autoregressive multimodal transformers across language, audio, and motion can enhance the coherent and realistic generation of vocals and whole-body human motions. For modality unification, a vector-quantized variational autoencoder is employed to encode whole-body motion sequences into discrete motion tokens, while a vocal-to-unit model is leveraged to obtain quantized audio tokens preserving content, prosodic information, and singer identity. By jointly performing transformer modeling on these three modalities in a unified way, our framework ensures a seamless and realistic blend of vocals and human motions. Extensive experiments demonstrate that our unified generation framework not only produces coherent and realistic singing vocals alongside human motions directly from textual inputs but also rivals the performance of specialized single-modality generation systems, establishing new benchmarks for joint vocal-motion generation. The project page is available for research purposes at https://vis-www.cs.umass.edu/RapVerse.
RoboDreamer: Learning Compositional World Models for Robot Imagination
Apr 18, 2024



Text-to-video models have demonstrated substantial potential in robotic decision-making, enabling the imagination of realistic plans of future actions as well as accurate environment simulation. However, one major issue in such models is generalization -- models are limited to synthesizing videos subject to language instructions similar to those seen at training time. This is heavily limiting in decision-making, where we seek a powerful world model to synthesize plans of unseen combinations of objects and actions in order to solve previously unseen tasks in new environments. To resolve this issue, we introduce RoboDreamer, an innovative approach for learning a compositional world model by factorizing the video generation. We leverage the natural compositionality of language to parse instructions into a set of lower-level primitives, which we condition a set of models on to generate videos. We illustrate how this factorization naturally enables compositional generalization, by allowing us to formulate a new natural language instruction as a combination of previously seen components. We further show how such a factorization enables us to add additional multimodal goals, allowing us to specify a video we wish to generate given both natural language instructions and a goal image. Our approach can successfully synthesize video plans on unseen goals in the RT-X, enables successful robot execution in simulation, and substantially outperforms monolithic baseline approaches to video generation.
SportsSloMo: A New Benchmark and Baselines for Human-centric Video Frame Interpolation
Aug 31, 2023



Human-centric video frame interpolation has great potential for improving people's entertainment experiences and finding commercial applications in the sports analysis industry, e.g., synthesizing slow-motion videos. Although there are multiple benchmark datasets available in the community, none of them is dedicated for human-centric scenarios. To bridge this gap, we introduce SportsSloMo, a benchmark consisting of more than 130K video clips and 1M video frames of high-resolution ($\geq$720p) slow-motion sports videos crawled from YouTube. We re-train several state-of-the-art methods on our benchmark, and the results show a decrease in their accuracy compared to other datasets. It highlights the difficulty of our benchmark and suggests that it poses significant challenges even for the best-performing methods, as human bodies are highly deformable and occlusions are frequent in sports videos. To improve the accuracy, we introduce two loss terms considering the human-aware priors, where we add auxiliary supervision to panoptic segmentation and human keypoints detection, respectively. The loss terms are model agnostic and can be easily plugged into any video frame interpolation approaches. Experimental results validate the effectiveness of our proposed loss terms, leading to consistent performance improvement over 5 existing models, which establish strong baseline models on our benchmark. The dataset and code can be found at: https://neu-vi.github.io/SportsSlomo/.
Revisiting Event-based Video Frame Interpolation
Jul 24, 2023



Dynamic vision sensors or event cameras provide rich complementary information for video frame interpolation. Existing state-of-the-art methods follow the paradigm of combining both synthesis-based and warping networks. However, few of those methods fully respect the intrinsic characteristics of events streams. Given that event cameras only encode intensity changes and polarity rather than color intensities, estimating optical flow from events is arguably more difficult than from RGB information. We therefore propose to incorporate RGB information in an event-guided optical flow refinement strategy. Moreover, in light of the quasi-continuous nature of the time signals provided by event cameras, we propose a divide-and-conquer strategy in which event-based intermediate frame synthesis happens incrementally in multiple simplified stages rather than in a single, long stage. Extensive experiments on both synthetic and real-world datasets show that these modifications lead to more reliable and realistic intermediate frame results than previous video frame interpolation methods. Our findings underline that a careful consideration of event characteristics such as high temporal density and elevated noise benefits interpolation accuracy.
Deceptive-NeRF: Enhancing NeRF Reconstruction using Pseudo-Observations from Diffusion Models
May 24, 2023



This paper introduces Deceptive-NeRF, a new method for enhancing the quality of reconstructed NeRF models using synthetically generated pseudo-observations, capable of handling sparse input and removing floater artifacts. Our proposed method involves three key steps: 1) reconstruct a coarse NeRF model from sparse inputs; 2) generate pseudo-observations based on the coarse model; 3) refine the NeRF model using pseudo-observations to produce a high-quality reconstruction. To generate photo-realistic pseudo-observations that faithfully preserve the identity of the reconstructed scene while remaining consistent with the sparse inputs, we develop a rectification latent diffusion model that generates images conditional on a coarse RGB image and depth map, which are derived from the coarse NeRF and latent text embedding from input images. Extensive experiments show that our method is effective and can generate perceptually high-quality NeRF even with very sparse inputs.
iQuery: Instruments as Queries for Audio-Visual Sound Separation
Dec 08, 2022



Current audio-visual separation methods share a standard architecture design where an audio encoder-decoder network is fused with visual encoding features at the encoder bottleneck. This design confounds the learning of multi-modal feature encoding with robust sound decoding for audio separation. To generalize to a new instrument: one must finetune the entire visual and audio network for all musical instruments. We re-formulate visual-sound separation task and propose Instrument as Query (iQuery) with a flexible query expansion mechanism. Our approach ensures cross-modal consistency and cross-instrument disentanglement. We utilize "visually named" queries to initiate the learning of audio queries and use cross-modal attention to remove potential sound source interference at the estimated waveforms. To generalize to a new instrument or event class, drawing inspiration from the text-prompt design, we insert an additional query as an audio prompt while freezing the attention mechanism. Experimental results on three benchmarks demonstrate that our iQuery improves audio-visual sound source separation performance.
Unsupervised Multi-View Object Segmentation Using Radiance Field Propagation
Oct 02, 2022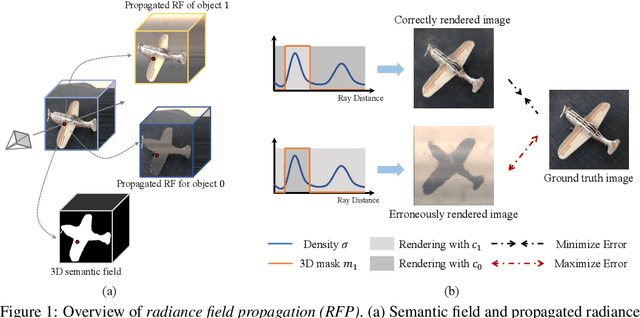
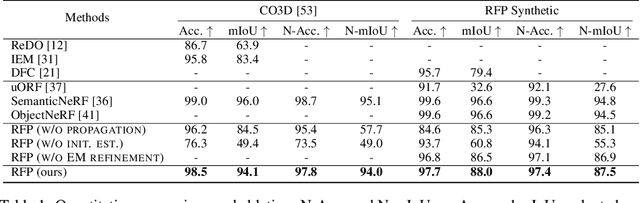

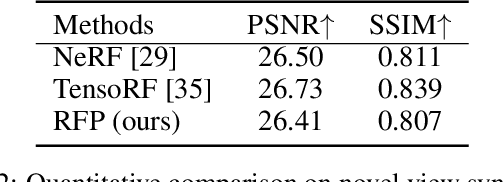
We present radiance field propagation (RFP), a novel approach to segmenting objects in 3D during reconstruction given only unlabeled multi-view images of a scene. RFP is derived from emerging neural radiance field-based techniques, which jointly encodes semantics with appearance and geometry. The core of our method is a novel propagation strategy for individual objects' radiance fields with a bidirectional photometric loss, enabling an unsupervised partitioning of a scene into salient or meaningful regions corresponding to different object instances. To better handle complex scenes with multiple objects and occlusions, we further propose an iterative expectation-maximization algorithm to refine object masks. To the best of our knowledge, RFP is the first unsupervised approach for tackling 3D scene object segmentation for neural radiance field (NeRF) without any supervision, annotations, or other cues such as 3D bounding boxes and prior knowledge of object class. Experiments demonstrate that RFP achieves feasible segmentation results that are more accurate than previous unsupervised image/scene segmentation approaches, and are comparable to existing supervised NeRF-based methods. The segmented object representations enable individual 3D object editing operations.
VECtor: A Versatile Event-Centric Benchmark for Multi-Sensor SLAM
Jul 04, 2022

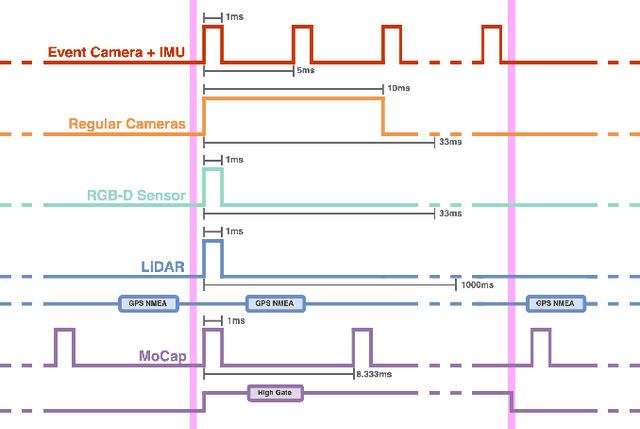
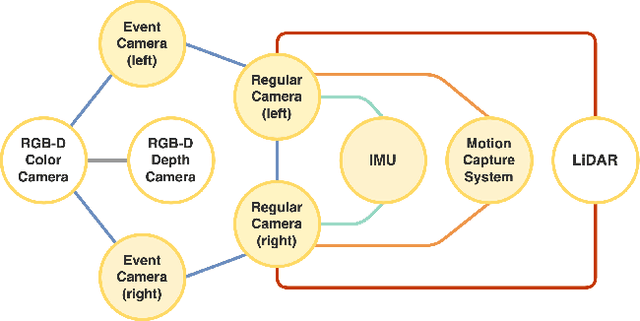
Event cameras have recently gained in popularity as they hold strong potential to complement regular cameras in situations of high dynamics or challenging illumination. An important problem that may benefit from the addition of an event camera is given by Simultaneous Localization And Mapping (SLAM). However, in order to ensure progress on event-inclusive multi-sensor SLAM, novel benchmark sequences are needed. Our contribution is the first complete set of benchmark datasets captured with a multi-sensor setup containing an event-based stereo camera, a regular stereo camera, multiple depth sensors, and an inertial measurement unit. The setup is fully hardware-synchronized and underwent accurate extrinsic calibration. All sequences come with ground truth data captured by highly accurate external reference devices such as a motion capture system. Individual sequences include both small and large-scale environments, and cover the specific challenges targeted by dynamic vision sensors.