 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantaneous Risk Minimization for Secure Integrated Sensing and Communication
Jun 03, 2026To ensure worst-case physical layer security, this paper proposes a robust beamforming framework for secure integrated sensing and communication (ISAC) systems. Different from conventional designs that focus on maximizing the ergodic secrecy rate, the proposed method aims to minimize instantaneous information leakage risk. We formulate a multi-objective optimization problem that jointly suppresses the worst-case eavesdropper signal-to-interference-plus-noise ratio (SINR), improving sensing accuracy, and ensuring the quality of service (QoS) for legitimate users. To address the resulting non-convex problem, we develop a hierarchical iterative algorithm, in which the outer loop refines the continuous uncertainty regions based on the updated sensing performance, and the inner loop optimizes beamforming under the refined uncertainty regions. Theoretical analysis and simulation results demonstrate that the proposed method achieves per-transmission security guarantees with practical complexity.
SecCodeBench-V2 Technical Report
Feb 17, 2026We introduce SecCodeBench-V2, a publicly released benchmark for evaluating Large Language Model (LLM) copilots' capabilities of generating secure code. SecCodeBench-V2 comprises 98 generation and fix scenarios derived from Alibaba Group's industrial productions, where the underlying security issues span 22 common CWE (Common Weakness Enumeration) categories across five programming languages: Java, C, Python, Go, and Node.js. SecCodeBench-V2 adopts a function-level task formulation: each scenario provides a complete project scaffold and requires the model to implement or patch a designated target function under fixed interfaces and dependencies. For each scenario, SecCodeBench-V2 provides executable proof-of-concept (PoC) test cases for both functional validation and security verification. All test cases are authored and double-reviewed by security experts, ensuring high fidelity, broad coverage, and reliable ground truth. Beyond the benchmark itself, we build a unified evaluation pipeline that assesses models primarily via dynamic execution. For most scenarios, we compile and run model-generated artifacts in isolated environments and execute PoC test cases to validate both functional correctness and security properties. For scenarios where security issues cannot be adjudicated with deterministic test cases, we additionally employ an LLM-as-a-judge oracle. To summarize performance across heterogeneous scenarios and difficulty levels, we design a Pass@K-based scoring protocol with principled aggregation over scenarios and severity, enabling holistic and comparable evaluation across models. Overall, SecCodeBench-V2 provides a rigorous and reproducible foundation for assessing the security posture of AI coding assistants, with results and artifacts released at https://alibaba.github.io/sec-code-bench. The benchmark is publicly available at https://github.com/alibaba/sec-code-bench.
Learning from the Irrecoverable: Error-Localized Policy Optimization for Tool-Integrated LLM Reasoning
Feb 10, 2026Tool-integrated reasoning (TIR) enables LLM agents to solve tasks through planning, tool use, and iterative revision, but outcome-only reinforcement learning in this setting suffers from sparse, delayed rewards and weak step-level credit assignment. In long-horizon TIR trajectories, an early irrecoverable mistake can determine success or failure, making it crucial to localize the first irrecoverable step and leverage it for fine-grained credit assignment. We propose Error-Localized Policy Optimization (ELPO), which localizes the first irrecoverable step via binary-search rollout trees under a fixed rollout budget, converts the resulting tree into stable learning signals through hierarchical advantage attribution, and applies error-localized adaptive clipping to strengthen corrective updates on the critical step and its suffix. Across TIR benchmarks in math, science QA, and code execution, ELPO consistently outperforms strong Agentic RL baselines under comparable sampling budgets, with additional gains in Pass@K and Major@K scaling, rollout ranking quality, and tool-call efficiency. Our code will be publicly released soon.
Fast and Accurate Quantized Camera Scene Detection on Smartphones, Mobile AI 2021 Challenge: Report
May 17, 2021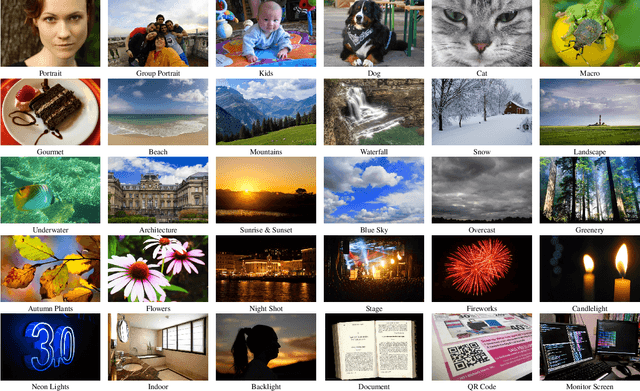
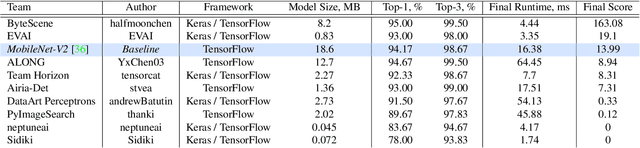

Camera scene detection is among the most popular computer vision problem on smartphones. While many custom solutions were developed for this task by phone vendors, none of the designed models were available publicly up until now. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop quantized deep learning-based camera scene classification solutions that can demonstrate a real-time performance on smartphones and IoT platforms. For this, the participants were provided with a large-scale CamSDD dataset consisting of more than 11K images belonging to the 30 most important scene categories. The runtime of all models was evaluated on the popular Apple Bionic A11 platform that can be found in many iOS devices. The proposed solutions are fully compatible with all major mobile AI accelerators and can demonstrate more than 100-200 FPS on the majority of recent smartphone platforms while achieving a top-3 accuracy of more than 98%. A detailed description of all models developed in the challenge is provided in this paper.
Fast and Accurate Single-Image Depth Estimation on Mobile Devices, Mobile AI 2021 Challenge: Report
May 17, 2021


Depth estimation is an important computer vision problem with many practical applications to mobile devices. While many solutions have been proposed for this task, they are usually very computationally expensive and thus are not applicable for on-device inference. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based depth estimation solutions that can demonstrate a nearly real-time performance on smartphones and IoT platforms. For this, the participants were provided with a new large-scale dataset containing RGB-depth image pairs obtained with a dedicated stereo ZED camera producing high-resolution depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the popular Raspberry Pi 4 platform with a mobile ARM-based Broadcom chipset. The proposed solutions can generate VGA resolution depth maps at up to 10 FPS on the Raspberry Pi 4 while achieving high fidelity results, and are compatible with any Android or Linux-based mobile devices. A detailed description of all models developed in the challenge is provided in this paper.