 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompt Tuning for Test-time Domain Adaptation
Oct 10, 2022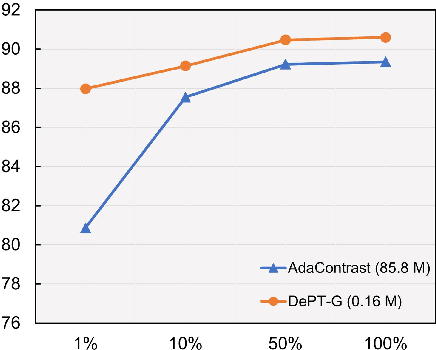
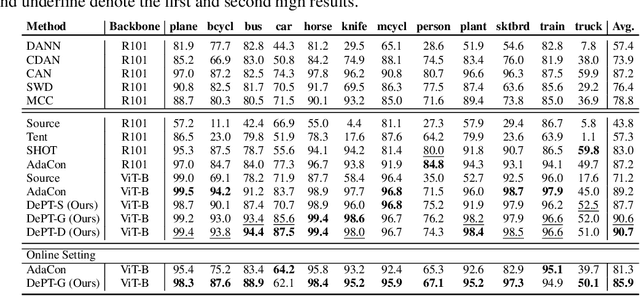
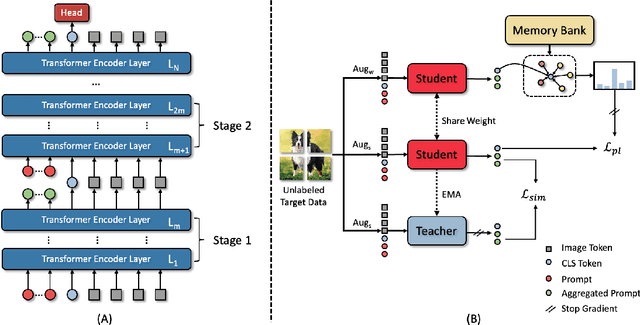
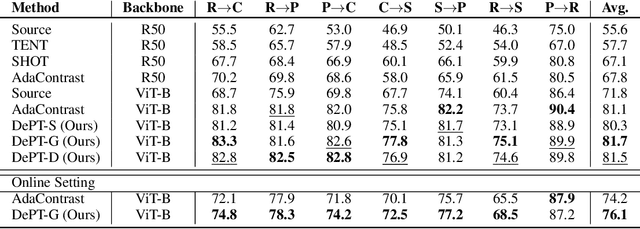
Models should have the ability to adapt to unseen data during test-time to avoid performance drop caused by inevitable distribution shifts in real-world deployment scenarios. In this work, we tackle the practical yet challenging test-time adaptation (TTA) problem, where a model adapts to the target domain without accessing the source data. We propose a simple recipe called data-efficient prompt tuning (DePT) with two key ingredients. First, DePT plugs visual prompts into the vision Transformer and only tunes these source-initialized prompts during adaptation. We find such parameter-efficient finetuning can efficiently adapt the model representation to the target domain without overfitting to the noise in the learning objective. Second, DePT bootstraps the source representation to the target domain by memory bank-based online pseudo labeling. A hierarchical self-supervised regularization specially designed for prompts is jointly optimized to alleviate error accumulation during self-training. With much fewer tunable parameters, DePT demonstrates not only state-of-the-art performance on major adaptation benchmarks, but also superior data efficiency, i.e., adaptation with only 1\% or 10\% data without much performance degradation compared to 100\% data. In addition, DePT is also versatile to be extended to online or multi-source TTA settings.
Weak Collocation Regression method: fast reveal hidden stochastic dynamics from high-dimensional aggregate data
Sep 07, 2022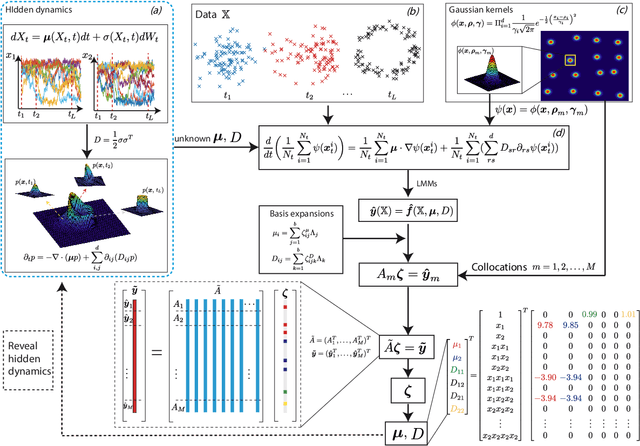

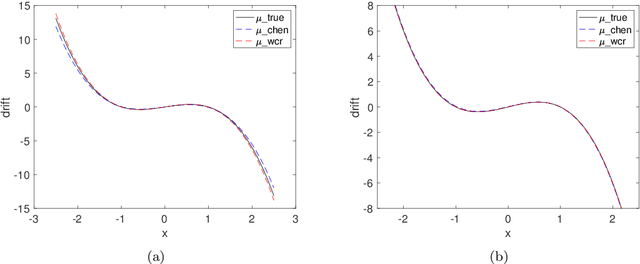
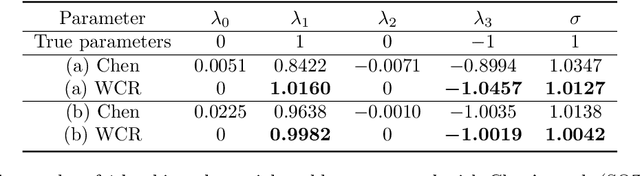
Revealing hidden dynamics from the stochastic data is a challenging problem as randomness takes part in the evolution of the data. The problem becomes exceedingly complex when the trajectories of the stochastic data are absent in many scenarios. Here we present an approach to effectively modeling the dynamics of the stochastic data without trajectories based on the weak form of the Fokker-Planck (FP) equation, which governs the evolution of the density function in the Brownian process. Taking the collocations of Gaussian functions as the test functions in the weak form of the FP equation, we transfer the derivatives to the Gaussian functions and thus approximate the weak form by the expectational sum of the data. With a dictionary representation of the unknown terms, a linear system is built and then solved by the regression, revealing the unknown dynamics of the data. Hence, we name the method with the Weak Collocation Regression (WCR) method for its three key components: weak form, collocation of Gaussian kernels, and regression. The numerical experiments show that our method is flexible and fast, which reveals the dynamics within seconds in multi-dimensional problems and can be easily extended to high-dimensional data such as 20 dimensions. WCR can also correctly identify the hidden dynamics of the complex tasks with variable-dependent diffusion and coupled drift, and the performance is robust, achieving high accuracy in the case with noise added.
Earthformer: Exploring Space-Time Transformers for Earth System Forecasting
Jul 12, 2022
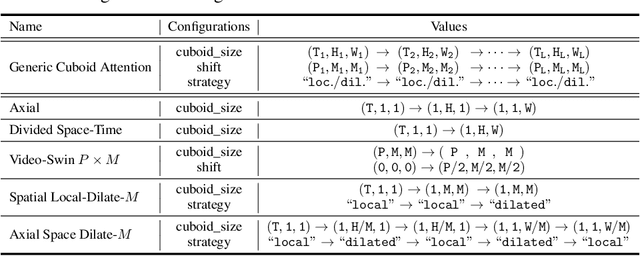
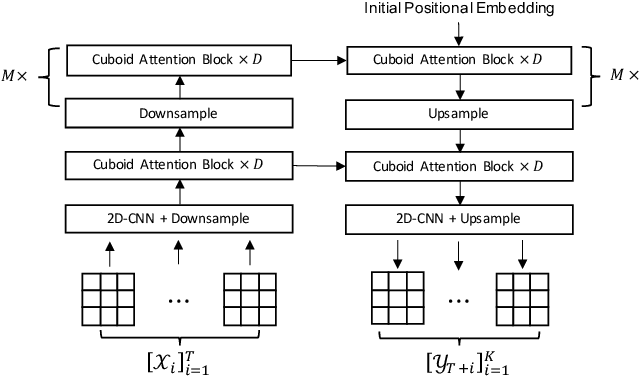
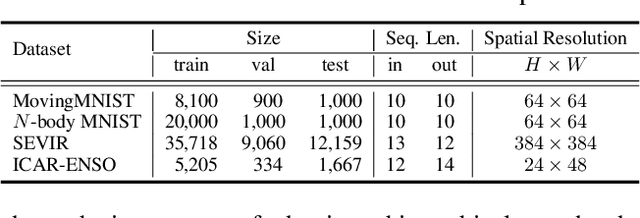
Conventionally, Earth system (e.g., weather and climate) forecasting relies on numerical simulation with complex physical models and are hence both expensive in computation and demanding on domain expertise. With the explosive growth of the spatiotemporal Earth observation data in the past decade, data-driven models that apply Deep Learning (DL) are demonstrating impressive potential for various Earth system forecasting tasks. The Transformer as an emerging DL architecture, despite its broad success in other domains, has limited adoption in this area. In this paper, we propose Earthformer, a space-time Transformer for Earth system forecasting. Earthformer is based on a generic, flexible and efficient space-time attention block, named Cuboid Attention. The idea is to decompose the data into cuboids and apply cuboid-level self-attention in parallel. These cuboids are further connected with a collection of global vectors. We conduct experiments on the MovingMNIST dataset and a newly proposed chaotic N-body MNIST dataset to verify the effectiveness of cuboid attention and figure out the best design of Earthformer. Experiments on two real-world benchmarks about precipitation nowcasting and El Nino/Southern Oscillation (ENSO) forecasting show Earthformer achieves state-of-the-art performance.
Unsupervised Semantic Segmentation with Self-supervised Object-centric Representations
Jul 11, 2022

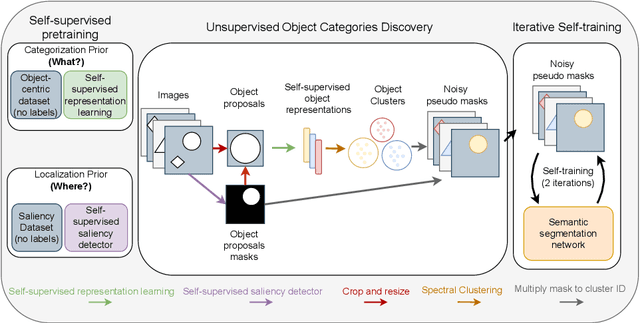
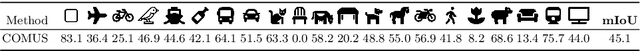
In this paper, we show that recent advances in self-supervised feature learning enable unsupervised object discovery and semantic segmentation with a performance that matches the state of the field on supervised semantic segmentation 10 years ago. We propose a methodology based on unsupervised saliency masks and self-supervised feature clustering to kickstart object discovery followed by training a semantic segmentation network on pseudo-labels to bootstrap the system on images with multiple objects. We present results on PASCAL VOC that go far beyond the current state of the art (47.3 mIoU), and we report for the first time results on MS COCO for the whole set of 81 classes: our method discovers 34 categories with more than $20\%$ IoU, while obtaining an average IoU of 19.6 for all 81 categories.
Pixel-level Correspondence for Self-Supervised Learning from Video
Jul 08, 2022
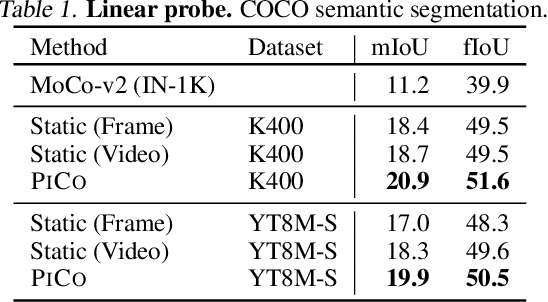


While self-supervised learning has enabled effective representation learning in the absence of labels, for vision, video remains a relatively untapped source of supervision. To address this, we propose Pixel-level Correspondence (PiCo), a method for dense contrastive learning from video. By tracking points with optical flow, we obtain a correspondence map which can be used to match local features at different points in time. We validate PiCo on standard benchmarks, outperforming self-supervised baselines on multiple dense prediction tasks, without compromising performance on image classification.
Partial and Asymmetric Contrastive Learning for Out-of-Distribution Detection in Long-Tailed Recognition
Jul 04, 2022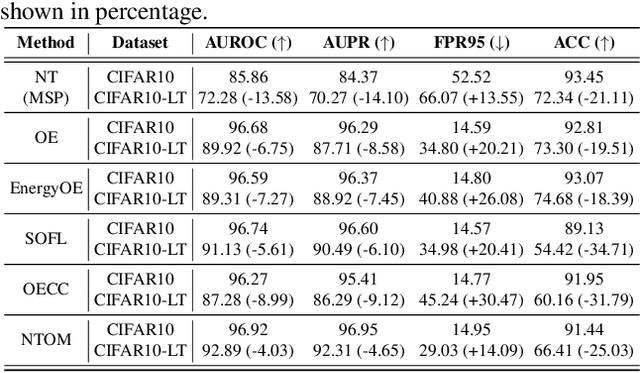
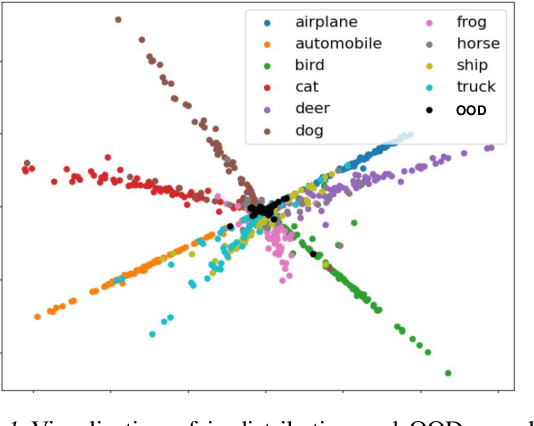
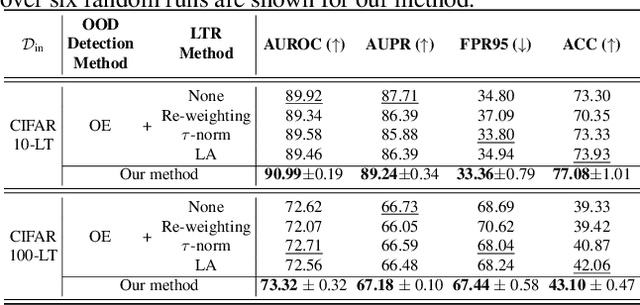
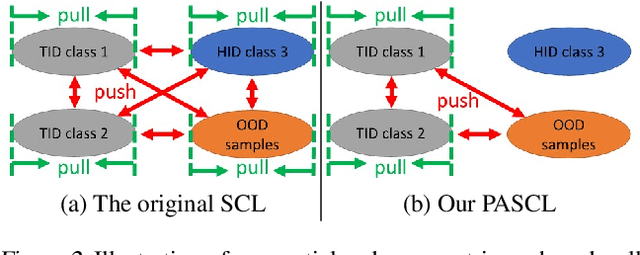
Existing out-of-distribution (OOD) detection methods are typically benchmarked on training sets with balanced class distributions. However, in real-world applications, it is common for the training sets to have long-tailed distributions. In this work, we first demonstrate that existing OOD detection methods commonly suffer from significant performance degradation when the training set is long-tail distributed. Through analysis, we posit that this is because the models struggle to distinguish the minority tail-class in-distribution samples, from the true OOD samples, making the tail classes more prone to be falsely detected as OOD. To solve this problem, we propose Partial and Asymmetric Supervised Contrastive Learning (PASCL), which explicitly encourages the model to distinguish between tail-class in-distribution samples and OOD samples. To further boost in-distribution classification accuracy, we propose Auxiliary Branch Finetuning, which uses two separate branches of BN and classification layers for anomaly detection and in-distribution classification, respectively. The intuition is that in-distribution and OOD anomaly data have different underlying distributions. Our method outperforms previous state-of-the-art method by $1.29\%$, $1.45\%$, $0.69\%$ anomaly detection false positive rate (FPR) and $3.24\%$, $4.06\%$, $7.89\%$ in-distribution classification accuracy on CIFAR10-LT, CIFAR100-LT, and ImageNet-LT, respectively. Code and pre-trained models are available at https://github.com/amazon-research/long-tailed-ood-detection.
MixGen: A New Multi-Modal Data Augmentation
Jun 16, 2022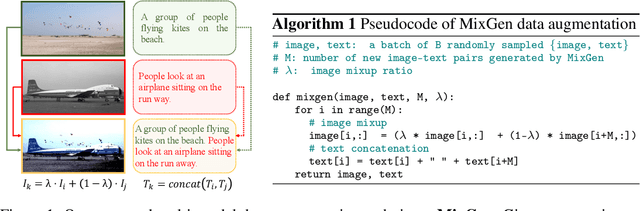

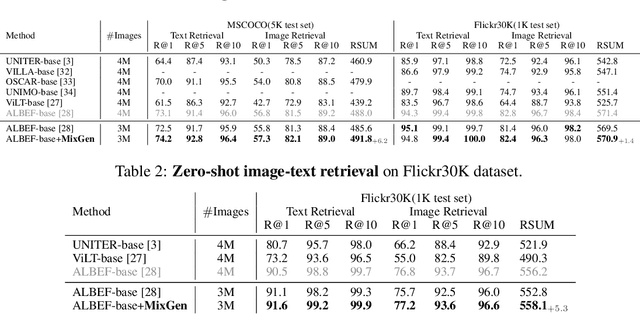
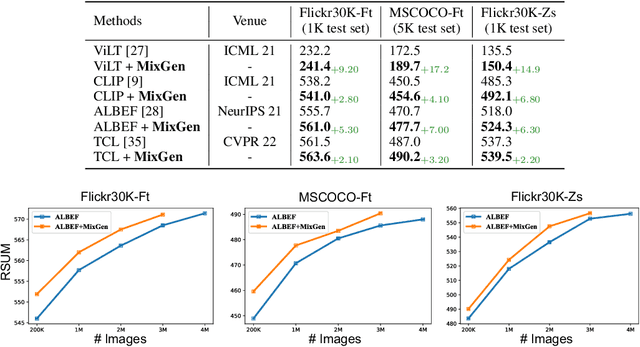
Data augmentation is a necessity to enhance data efficiency in deep learning. For vision-language pre-training, data is only augmented either for images or for text in previous works. In this paper, we present MixGen: a joint data augmentation for vision-language representation learning to further improve data efficiency. It generates new image-text pairs with semantic relationships preserved by interpolating images and concatenating text. It's simple, and can be plug-and-played into existing pipelines. We evaluate MixGen on four architectures, including CLIP, ViLT, ALBEF and TCL, across five downstream vision-language tasks to show its versatility and effectiveness. For example, adding MixGen in ALBEF pre-training leads to absolute performance improvements on downstream tasks: image-text retrieval (+6.2% on COCO fine-tuned and +5.3% on Flicker30K zero-shot), visual grounding (+0.9% on RefCOCO+), visual reasoning (+0.9% on NLVR$^{2}$), visual question answering (+0.3% on VQA2.0), and visual entailment (+0.4% on SNLI-VE).
ADAPT: Vision-Language Navigation with Modality-Aligned Action Prompts
May 31, 2022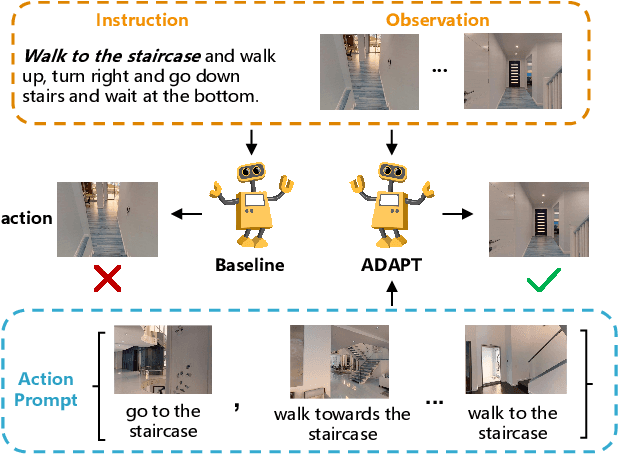

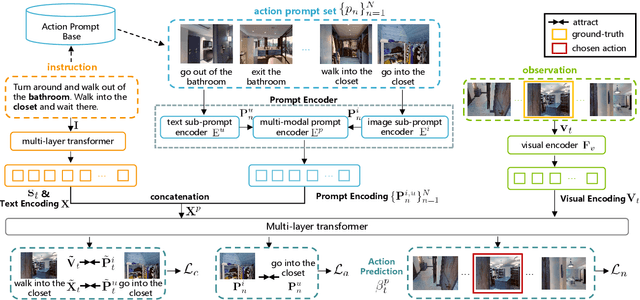
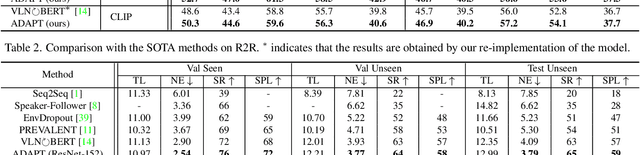
Vision-Language Navigation (VLN) is a challenging task that requires an embodied agent to perform action-level modality alignment, i.e., make instruction-asked actions sequentially in complex visual environments. Most existing VLN agents learn the instruction-path data directly and cannot sufficiently explore action-level alignment knowledge inside the multi-modal inputs. In this paper, we propose modAlity-aligneD Action PrompTs (ADAPT), which provides the VLN agent with action prompts to enable the explicit learning of action-level modality alignment to pursue successful navigation. Specifically, an action prompt is defined as a modality-aligned pair of an image sub-prompt and a text sub-prompt, where the former is a single-view observation and the latter is a phrase like ''walk past the chair''. When starting navigation, the instruction-related action prompt set is retrieved from a pre-built action prompt base and passed through a prompt encoder to obtain the prompt feature. Then the prompt feature is concatenated with the original instruction feature and fed to a multi-layer transformer for action prediction. To collect high-quality action prompts into the prompt base, we use the Contrastive Language-Image Pretraining (CLIP) model which has powerful cross-modality alignment ability. A modality alignment loss and a sequential consistency loss are further introduced to enhance the alignment of the action prompt and enforce the agent to focus on the related prompt sequentially. Experimental results on both R2R and RxR show the superiority of ADAPT over state-of-the-art methods.
NTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022



This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Chinese Idiom Paraphrasing
Apr 20, 2022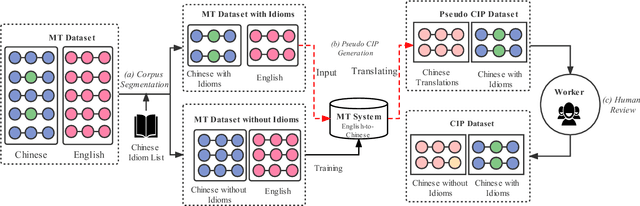
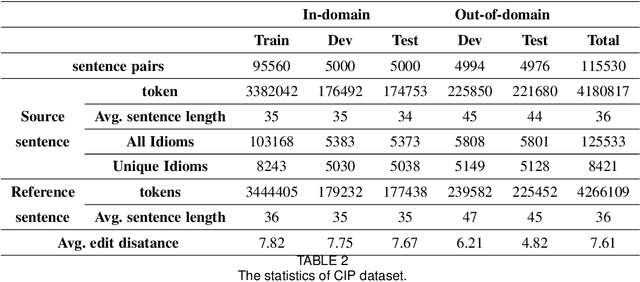
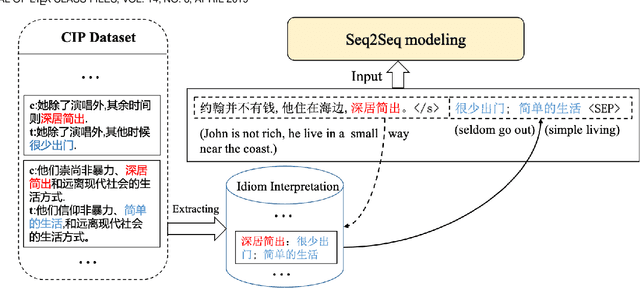

Idioms, are a kind of idiomatic expression in Chinese, most of which consist of four Chinese characters. Due to the properties of non-compositionality and metaphorical meaning, Chinese Idioms are hard to be understood by children and non-native speakers. This study proposes a novel task, denoted as Chinese Idiom Paraphrasing (CIP). CIP aims to rephrase idioms-included sentences to non-idiomatic ones under the premise of preserving the original sentence's meaning. Since the sentences without idioms are easier handled by Chinese NLP systems, CIP can be used to pre-process Chinese datasets, thereby facilitating and improving the performance of Chinese NLP tasks, e.g., machine translation system, Chinese idiom cloze, and Chinese idiom embeddings. In this study, CIP task is treated as a special paraphrase generation task. To circumvent difficulties in acquiring annotations, we first establish a large-scale CIP dataset based on human and machine collaboration, which consists of 115,530 sentence pairs. We further deploy three baselines and two novel CIP approaches to deal with CIP problems. The results show that the proposed methods have better performances than the baselines based on the established CIP dataset.