 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStill Camouflage, Moving Illusion: View-Induced Trajectory Manipulation in Autonomous Driving
May 12, 2026Existing physical adversarial attacks on vision-based autonomous driving induce time-evolving perception errors, including biased object tracking or trajectory prediction, through (i) sophisticated physical patch inducing detection box drift when entering the view distance, or (ii) dynamically changing patches that cause different perception errors at different time. In both cases, viewing-angle variation is treated as a challenge, requiring adversarial patches to remain effective across frames under varying views, leading to complex multi-view optimization. In contrast, we show that viewing-angle variation itself can be turned into an attack tool. We design a new attack paradigm where a static, passive adversarial camouflage is mounted on a vehicle whose view-dependent appearance naturally evolves with relative motion, inducing consistent feature drift across frames. This causes the system to infer a physically plausible but incorrect trajectory, such as a false cut-in, which propagates to downstream decision-making and triggers unnecessary braking. Unlike prior approaches that require multi-view robustness or active intervention, our attack emerges from normal driving dynamics and is easy to deploy: a parked vehicle with a natural camouflage can induce hard braking in passing autonomous vehicles. We demonstrate the novel attack on nuScenes dataset, showing the effectiveness with an end-to-end success rate of up to 87.5%, measured by hard-braking events, and robustness across different scene backgrounds, victim vehicle speeds, and perception models.
Denoise and Align: Diffusion-Driven Foreground Knowledge Prompting for Open-Vocabulary Temporal Action Detection
Apr 20, 2026Open-Vocabulary Temporal Action Detection (OV-TAD) aims to localize and classify action segments of unseen categories in untrimmed videos, where effective alignment between action semantics and video representations is critical for accurate detection. However, existing methods struggle to mitigate the semantic imbalance between concise, abstract action labels and rich, complex video contents, inevitably introducing semantic noise and misleading cross-modal alignment. To address this challenge, we propose DFAlign, the first framework that leverages diffusion-based denoising to generate foreground knowledge for the guidance of action-video alignment. Following the 'conditioning, denoising and aligning' manner, we first introduce the Semantic-Unify Conditioning (SUC) module, which unifies action-shared and action-specific semantics as conditions for diffusion denoising. Then, the Background-Suppress Denoising (BSD) module generates foreground knowledge by progressively removing background redundancy from videos through denoising process. This foreground knowledge serves as effective intermediate semantic anchor between video and text representations, mitigating the semantic gap and enhancing the discriminability of action-relevant segments. Furthermore, we introduce the Foreground-Prompt Alignment (FPA) module to inject extracted foreground knowledge as prompt tokens into text representations, guiding model's attention towards action-relevant segments and enabling precise cross-modal alignment. Extensive experiments demonstrate that our method achieves state-of-the-art performance on two OV-TAD benchmarks. The code repository is provided as follows: https://anonymous.4open.science/r/Code-2114/.
Decompose and Transfer: CoT-Prompting Enhanced Alignment for Open-Vocabulary Temporal Action Detection
Mar 25, 2026Open-Vocabulary Temporal Action Detection (OV-TAD) aims to classify and localize action segments in untrimmed videos for unseen categories. Previous methods rely solely on global alignment between label-level semantics and visual features, which is insufficient to transfer temporal consistent visual knowledge from seen to unseen classes. To address this, we propose a Phase-wise Decomposition and Alignment (PDA) framework, which enables fine-grained action pattern learning for effective prior knowledge transfer. Specifically, we first introduce the CoT-Prompting Semantic Decomposition (CSD) module, which leverages the chain-of-thought (CoT) reasoning ability of large language models to automatically decompose action labels into coherent phase-level descriptions, emulating human cognitive processes. Then, Text-infused Foreground Filtering (TIF) module is introduced to adaptively filter action-relevant segments for each phase leveraging phase-wise semantic cues, producing semantically aligned visual representations. Furthermore, we propose the Adaptive Phase-wise Alignment (APA) module to perform phase-level visual-textual matching, and adaptively aggregates alignment results across phases for final prediction. This adaptive phase-wise alignment facilitates the capture of transferable action patterns and significantly enhances generalization to unseen actions. Extensive experiments on two OV-TAD benchmarks demonstrated the superiority of the proposed method.
RealEra: Semantic-level Concept Erasure via Neighbor-Concept Mining
Oct 11, 2024



The remarkable development of text-to-image generation models has raised notable security concerns, such as the infringement of portrait rights and the generation of inappropriate content. Concept erasure has been proposed to remove the model's knowledge about protected and inappropriate concepts. Although many methods have tried to balance the efficacy (erasing target concepts) and specificity (retaining irrelevant concepts), they can still generate abundant erasure concepts under the steering of semantically related inputs. In this work, we propose RealEra to address this "concept residue" issue. Specifically, we first introduce the mechanism of neighbor-concept mining, digging out the associated concepts by adding random perturbation into the embedding of erasure concept, thus expanding the erasing range and eliminating the generations even through associated concept inputs. Furthermore, to mitigate the negative impact on the generation of irrelevant concepts caused by the expansion of erasure scope, RealEra preserves the specificity through the beyond-concept regularization. This makes irrelevant concepts maintain their corresponding spatial position, thereby preserving their normal generation performance. We also employ the closed-form solution to optimize weights of U-Net for the cross-attention alignment, as well as the prediction noise alignment with the LoRA module. Extensive experiments on multiple benchmarks demonstrate that RealEra outperforms previous concept erasing methods in terms of superior erasing efficacy, specificity, and generality. More details are available on our project page https://realerasing.github.io/RealEra/ .
XNN: Paradigm Shift in Mitigating Identity Leakage within Cloud-Enabled Deep Learning
Aug 09, 2024



In the domain of cloud-based deep learning, the imperative for external computational resources coexists with acute privacy concerns, particularly identity leakage. To address this challenge, we introduce XNN and XNN-d, pioneering methodologies that infuse neural network features with randomized perturbations, striking a harmonious balance between utility and privacy. XNN, designed for the training phase, ingeniously blends random permutation with matrix multiplication techniques to obfuscate feature maps, effectively shielding private data from potential breaches without compromising training integrity. Concurrently, XNN-d, devised for the inference phase, employs adversarial training to integrate generative adversarial noise. This technique effectively counters black-box access attacks aimed at identity extraction, while a distilled face recognition network adeptly processes the perturbed features, ensuring accurate identification. Our evaluation demonstrates XNN's effectiveness, significantly outperforming existing methods in reducing identity leakage while maintaining a high model accuracy.
Prediction Exposes Your Face: Black-box Model Inversion via Prediction Alignment
Jul 11, 2024



Model inversion (MI) attack reconstructs the private training data of a target model given its output, posing a significant threat to deep learning models and data privacy. On one hand, most of existing MI methods focus on searching for latent codes to represent the target identity, yet this iterative optimization-based scheme consumes a huge number of queries to the target model, making it unrealistic especially in black-box scenario. On the other hand, some training-based methods launch an attack through a single forward inference, whereas failing to directly learn high-level mappings from prediction vectors to images. Addressing these limitations, we propose a novel Prediction-to-Image (P2I) method for black-box MI attack. Specifically, we introduce the Prediction Alignment Encoder to map the target model's output prediction into the latent code of StyleGAN. In this way, prediction vector space can be well aligned with the more disentangled latent space, thus establishing a connection between prediction vectors and the semantic facial features. During the attack phase, we further design the Aligned Ensemble Attack scheme to integrate complementary facial attributes of target identity for better reconstruction. Experimental results show that our method outperforms other SOTAs, e.g.,compared with RLB-MI, our method improves attack accuracy by 8.5% and reduces query numbers by 99% on dataset CelebA.
Disrupting Diffusion: Token-Level Attention Erasure Attack against Diffusion-based Customization
May 31, 2024



With the development of diffusion-based customization methods like DreamBooth, individuals now have access to train the models that can generate their personalized images. Despite the convenience, malicious users have misused these techniques to create fake images, thereby triggering a privacy security crisis. In light of this, proactive adversarial attacks are proposed to protect users against customization. The adversarial examples are trained to distort the customization model's outputs and thus block the misuse. In this paper, we propose DisDiff (Disrupting Diffusion), a novel adversarial attack method to disrupt the diffusion model outputs. We first delve into the intrinsic image-text relationships, well-known as cross-attention, and empirically find that the subject-identifier token plays an important role in guiding image generation. Thus, we propose the Cross-Attention Erasure module to explicitly "erase" the indicated attention maps and disrupt the text guidance. Besides,we analyze the influence of the sampling process of the diffusion model on Projected Gradient Descent (PGD) attack and introduce a novel Merit Sampling Scheduler to adaptively modulate the perturbation updating amplitude in a step-aware manner. Our DisDiff outperforms the state-of-the-art methods by 12.75% of FDFR scores and 7.25% of ISM scores across two facial benchmarks and two commonly used prompts on average.
MixGen: A New Multi-Modal Data Augmentation
Jun 16, 2022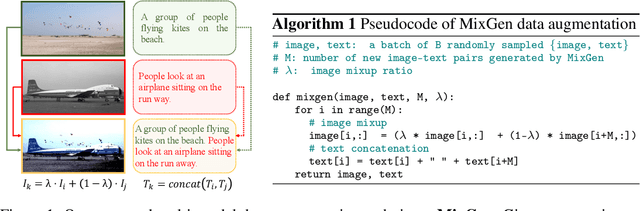

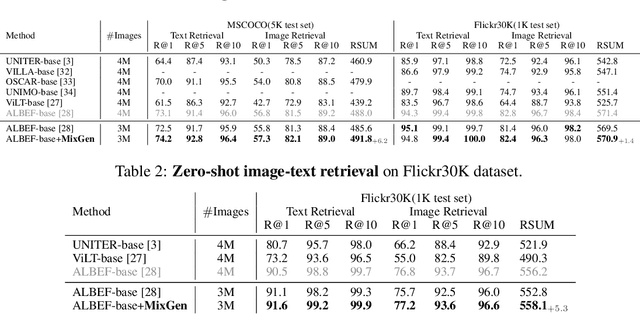
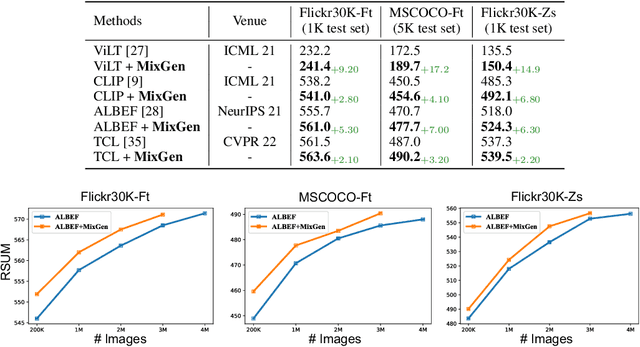
Data augmentation is a necessity to enhance data efficiency in deep learning. For vision-language pre-training, data is only augmented either for images or for text in previous works. In this paper, we present MixGen: a joint data augmentation for vision-language representation learning to further improve data efficiency. It generates new image-text pairs with semantic relationships preserved by interpolating images and concatenating text. It's simple, and can be plug-and-played into existing pipelines. We evaluate MixGen on four architectures, including CLIP, ViLT, ALBEF and TCL, across five downstream vision-language tasks to show its versatility and effectiveness. For example, adding MixGen in ALBEF pre-training leads to absolute performance improvements on downstream tasks: image-text retrieval (+6.2% on COCO fine-tuned and +5.3% on Flicker30K zero-shot), visual grounding (+0.9% on RefCOCO+), visual reasoning (+0.9% on NLVR$^{2}$), visual question answering (+0.3% on VQA2.0), and visual entailment (+0.4% on SNLI-VE).
Imagine by Reasoning: A Reasoning-Based Implicit Semantic Data Augmentation for Long-Tailed Classification
Dec 15, 2021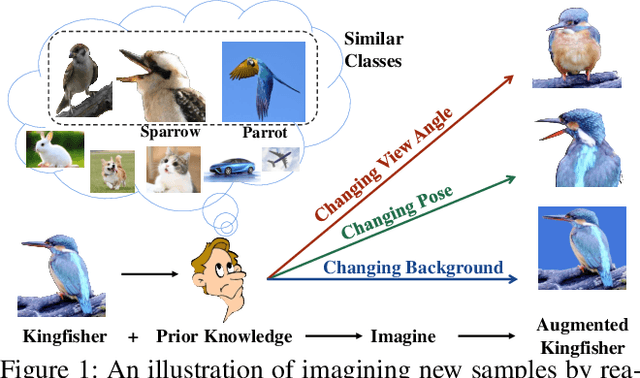
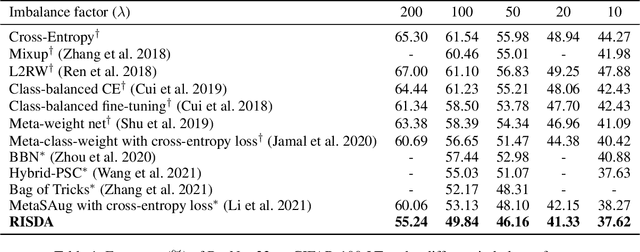
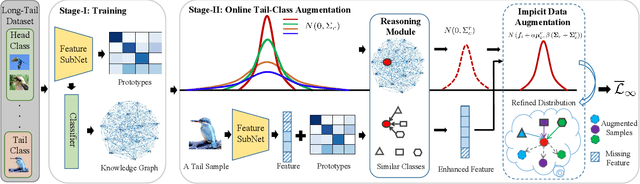
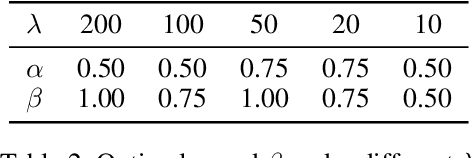
Real-world data often follows a long-tailed distribution, which makes the performance of existing classification algorithms degrade heavily. A key issue is that samples in tail categories fail to depict their intra-class diversity. Humans can imagine a sample in new poses, scenes, and view angles with their prior knowledge even if it is the first time to see this category. Inspired by this, we propose a novel reasoning-based implicit semantic data augmentation method to borrow transformation directions from other classes. Since the covariance matrix of each category represents the feature transformation directions, we can sample new directions from similar categories to generate definitely different instances. Specifically, the long-tailed distributed data is first adopted to train a backbone and a classifier. Then, a covariance matrix for each category is estimated, and a knowledge graph is constructed to store the relations of any two categories. Finally, tail samples are adaptively enhanced via propagating information from all the similar categories in the knowledge graph. Experimental results on CIFAR-100-LT, ImageNet-LT, and iNaturalist 2018 have demonstrated the effectiveness of our proposed method compared with the state-of-the-art methods.