 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTLDM: Spatio-Temporal Latent Diffusion Model for Precipitation Nowcasting
Dec 24, 2025Precipitation nowcasting is a critical spatio-temporal prediction task for society to prevent severe damage owing to extreme weather events. Despite the advances in this field, the complex and stochastic nature of this task still poses challenges to existing approaches. Specifically, deterministic models tend to produce blurry predictions while generative models often struggle with poor accuracy. In this paper, we present a simple yet effective model architecture termed STLDM, a diffusion-based model that learns the latent representation from end to end alongside both the Variational Autoencoder and the conditioning network. STLDM decomposes this task into two stages: a deterministic forecasting stage handled by the conditioning network, and an enhancement stage performed by the latent diffusion model. Experimental results on multiple radar datasets demonstrate that STLDM achieves superior performance compared to the state of the art, while also improving inference efficiency. The code is available in https://github.com/sqfoo/stldm_official.
PreDiff: Precipitation Nowcasting with Latent Diffusion Models
Jul 19, 2023



Earth system forecasting has traditionally relied on complex physical models that are computationally expensive and require significant domain expertise. In the past decade, the unprecedented increase in spatiotemporal Earth observation data has enabled data-driven forecasting models using deep learning techniques. These models have shown promise for diverse Earth system forecasting tasks but either struggle with handling uncertainty or neglect domain-specific prior knowledge, resulting in averaging possible futures to blurred forecasts or generating physically implausible predictions. To address these limitations, we propose a two-stage pipeline for probabilistic spatiotemporal forecasting: 1) We develop PreDiff, a conditional latent diffusion model capable of probabilistic forecasts. 2) We incorporate an explicit knowledge control mechanism to align forecasts with domain-specific physical constraints. This is achieved by estimating the deviation from imposed constraints at each denoising step and adjusting the transition distribution accordingly. We conduct empirical studies on two datasets: N-body MNIST, a synthetic dataset with chaotic behavior, and SEVIR, a real-world precipitation nowcasting dataset. Specifically, we impose the law of conservation of energy in N-body MNIST and anticipated precipitation intensity in SEVIR. Experiments demonstrate the effectiveness of PreDiff in handling uncertainty, incorporating domain-specific prior knowledge, and generating forecasts that exhibit high operational utility.
Forecasting localized weather impacts on vegetation as seen from space with meteo-guided video prediction
Mar 28, 2023



We present a novel approach for modeling vegetation response to weather in Europe as measured by the Sentinel 2 satellite. Existing satellite imagery forecasting approaches focus on photorealistic quality of the multispectral images, while derived vegetation dynamics have not yet received as much attention. We leverage both spatial and temporal context by extending state-of-the-art video prediction methods with weather guidance. We extend the EarthNet2021 dataset to be suitable for vegetation modeling by introducing a learned cloud mask and an appropriate evaluation scheme. Qualitative and quantitative experiments demonstrate superior performance of our approach over a wide variety of baseline methods, including leading approaches to satellite imagery forecasting. Additionally, we show how our modeled vegetation dynamics can be leveraged in a downstream task: inferring gross primary productivity for carbon monitoring. To the best of our knowledge, this work presents the first models for continental-scale vegetation modeling at fine resolution able to capture anomalies beyond the seasonal cycle, thereby paving the way for predictive assessments of vegetation status.
Earthformer: Exploring Space-Time Transformers for Earth System Forecasting
Jul 12, 2022
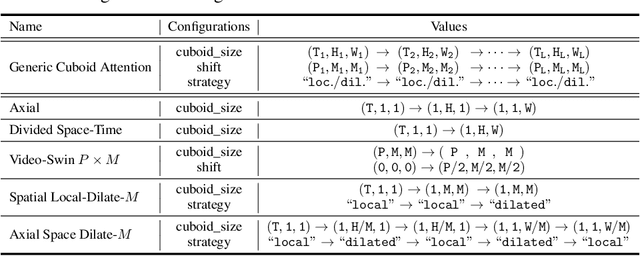
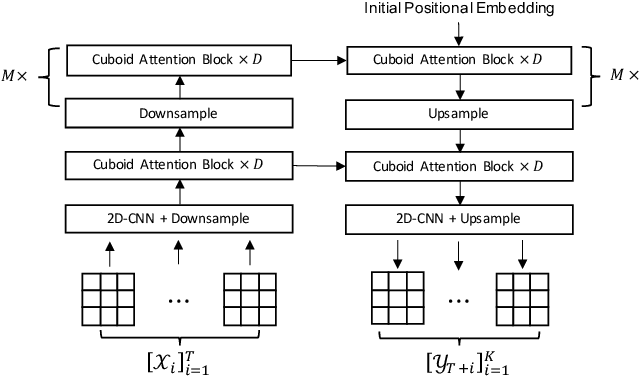
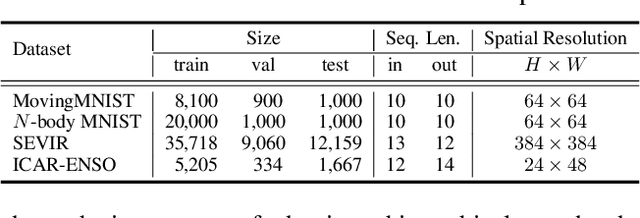
Conventionally, Earth system (e.g., weather and climate) forecasting relies on numerical simulation with complex physical models and are hence both expensive in computation and demanding on domain expertise. With the explosive growth of the spatiotemporal Earth observation data in the past decade, data-driven models that apply Deep Learning (DL) are demonstrating impressive potential for various Earth system forecasting tasks. The Transformer as an emerging DL architecture, despite its broad success in other domains, has limited adoption in this area. In this paper, we propose Earthformer, a space-time Transformer for Earth system forecasting. Earthformer is based on a generic, flexible and efficient space-time attention block, named Cuboid Attention. The idea is to decompose the data into cuboids and apply cuboid-level self-attention in parallel. These cuboids are further connected with a collection of global vectors. We conduct experiments on the MovingMNIST dataset and a newly proposed chaotic N-body MNIST dataset to verify the effectiveness of cuboid attention and figure out the best design of Earthformer. Experiments on two real-world benchmarks about precipitation nowcasting and El Nino/Southern Oscillation (ENSO) forecasting show Earthformer achieves state-of-the-art performance.
Fully Using Classifiers for Weakly Supervised Semantic Segmentation with Modified Cues
Apr 03, 2019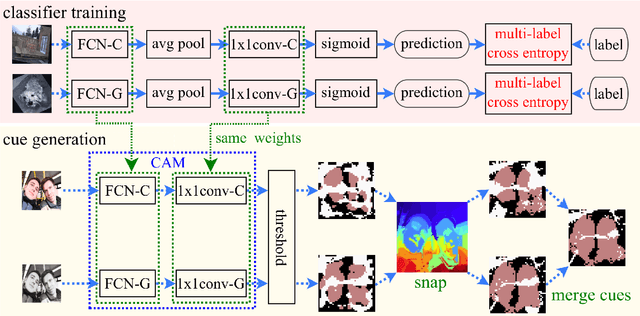
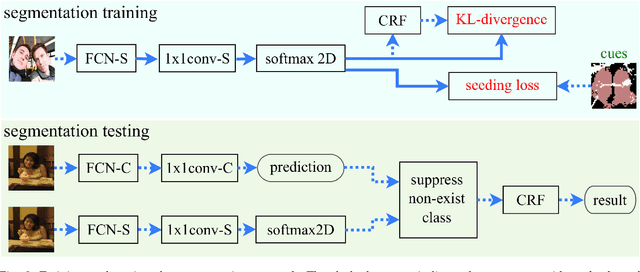
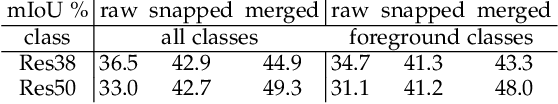
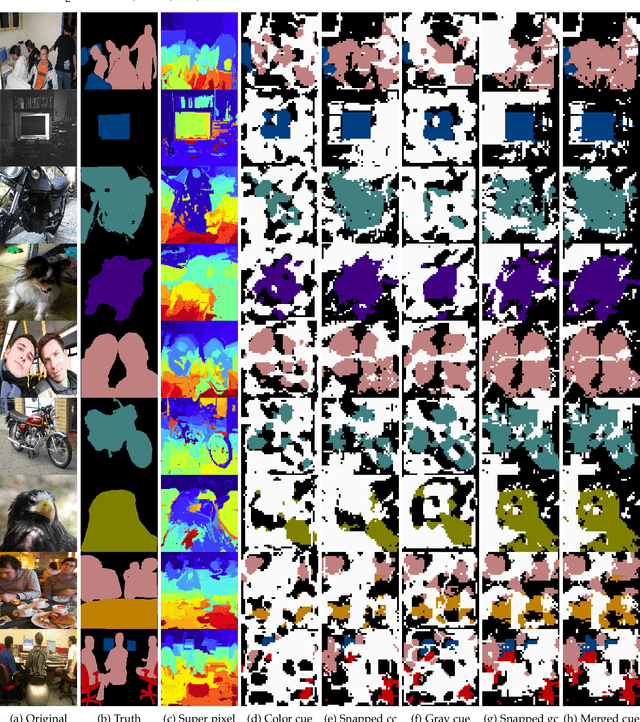
This paper proposes a novel weakly-supervised semantic segmentation method using image-level label only. The class-specific activation maps from the well-trained classifiers are used as cues to train a segmentation network. The well-known defects of these cues are coarseness and incompleteness. We use super-pixel to refine them, and fuse the cues extracted from both a color image trained classifier and a gray image trained classifier to compensate for their incompleteness. The conditional random field is adapted to regulate the training process and to refine the outputs further. Besides initializing the segmentation network, the previously trained classifier is also used in the testing phase to suppress the non-existing classes. Experimental results on the PASCAL VOC 2012 dataset illustrate the effectiveness of our method.
Deep Learning for Precipitation Nowcasting: A Benchmark and A New Model
Oct 05, 2017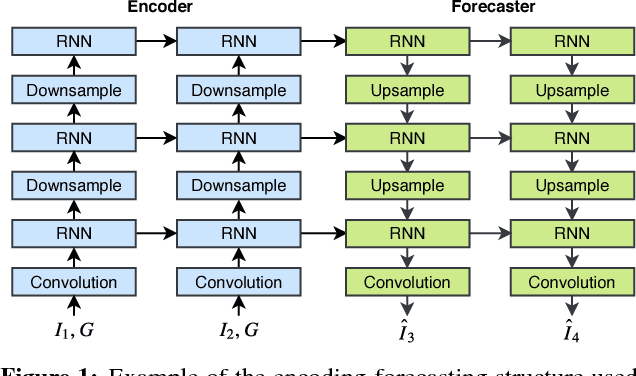

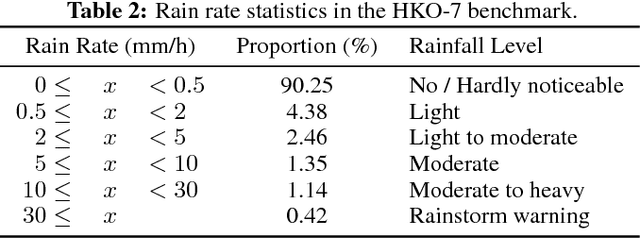
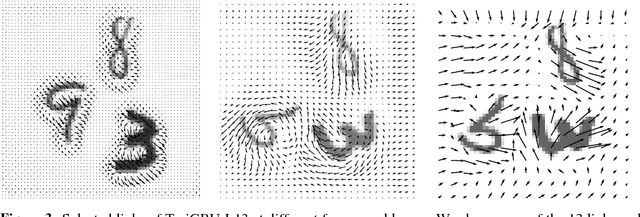
With the goal of making high-resolution forecasts of regional rainfall, precipitation nowcasting has become an important and fundamental technology underlying various public services ranging from rainstorm warnings to flight safety. Recently, the Convolutional LSTM (ConvLSTM) model has been shown to outperform traditional optical flow based methods for precipitation nowcasting, suggesting that deep learning models have a huge potential for solving the problem. However, the convolutional recurrence structure in ConvLSTM-based models is location-invariant while natural motion and transformation (e.g., rotation) are location-variant in general. Furthermore, since deep-learning-based precipitation nowcasting is a newly emerging area, clear evaluation protocols have not yet been established. To address these problems, we propose both a new model and a benchmark for precipitation nowcasting. Specifically, we go beyond ConvLSTM and propose the Trajectory GRU (TrajGRU) model that can actively learn the location-variant structure for recurrent connections. Besides, we provide a benchmark that includes a real-world large-scale dataset from the Hong Kong Observatory, a new training loss, and a comprehensive evaluation protocol to facilitate future research and gauge the state of the art.