 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniBYD: A Unified Framework for Learning Robotic Manipulation Across Embodiments Beyond Imitation of Human Demonstrations
Dec 12, 2025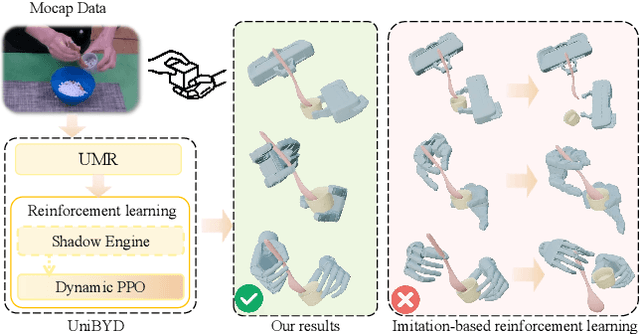
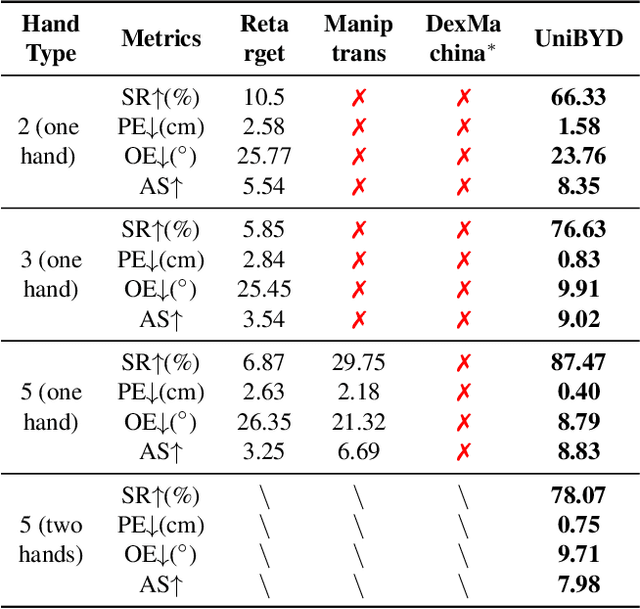
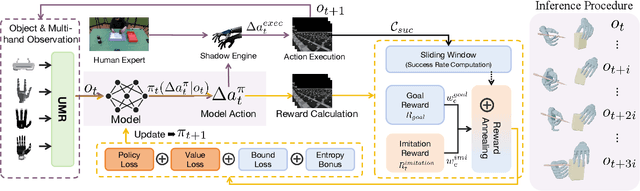
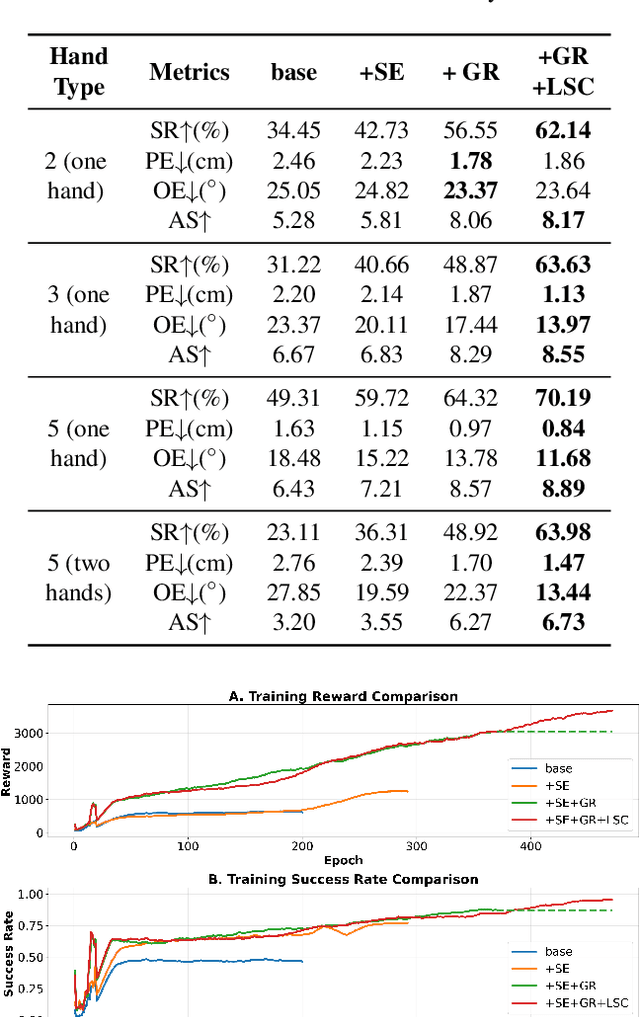
In embodied intelligence, the embodiment gap between robotic and human hands brings significant challenges for learning from human demonstrations. Although some studies have attempted to bridge this gap using reinforcement learning, they remain confined to merely reproducing human manipulation, resulting in limited task performance. In this paper, we propose UniBYD, a unified framework that uses a dynamic reinforcement learning algorithm to discover manipulation policies aligned with the robot's physical characteristics. To enable consistent modeling across diverse robotic hand morphologies, UniBYD incorporates a unified morphological representation (UMR). Building on UMR, we design a dynamic PPO with an annealed reward schedule, enabling reinforcement learning to transition from imitation of human demonstrations to explore policies adapted to diverse robotic morphologies better, thereby going beyond mere imitation of human hands. To address the frequent failures of learning human priors in the early training stage, we design a hybrid Markov-based shadow engine that enables reinforcement learning to imitate human manipulations in a fine-grained manner. To evaluate UniBYD comprehensively, we propose UniManip, the first benchmark encompassing robotic manipulation tasks spanning multiple hand morphologies. Experiments demonstrate a 67.90% improvement in success rate over the current state-of-the-art. Upon acceptance of the paper, we will release our code and benchmark at https://github.com/zhanheng-creator/UniBYD.
See Once, Then Act: Vision-Language-Action Model with Task Learning from One-Shot Video Demonstrations
Dec 08, 2025Developing robust and general-purpose manipulation policies represents a fundamental objective in robotics research. While Vision-Language-Action (VLA) models have demonstrated promising capabilities for end-to-end robot control, existing approaches still exhibit limited generalization to tasks beyond their training distributions. In contrast, humans possess remarkable proficiency in acquiring novel skills by simply observing others performing them once. Inspired by this capability, we propose ViVLA, a generalist robotic manipulation policy that achieves efficient task learning from a single expert demonstration video at test time. Our approach jointly processes an expert demonstration video alongside the robot's visual observations to predict both the demonstrated action sequences and subsequent robot actions, effectively distilling fine-grained manipulation knowledge from expert behavior and transferring it seamlessly to the agent. To enhance the performance of ViVLA, we develop a scalable expert-agent pair data generation pipeline capable of synthesizing paired trajectories from easily accessible human videos, further augmented by curated pairs from publicly available datasets. This pipeline produces a total of 892,911 expert-agent samples for training ViVLA. Experimental results demonstrate that our ViVLA is able to acquire novel manipulation skills from only a single expert demonstration video at test time. Our approach achieves over 30% improvement on unseen LIBERO tasks and maintains above 35% gains with cross-embodiment videos. Real-world experiments demonstrate effective learning from human videos, yielding more than 38% improvement on unseen tasks.
Multi-Text Guided Few-Shot Semantic Segmentation
Nov 19, 2025Recent CLIP-based few-shot semantic segmentation methods introduce class-level textual priors to assist segmentation by typically using a single prompt (e.g., a photo of class). However, these approaches often result in incomplete activation of target regions, as a single textual description cannot fully capture the semantic diversity of complex categories. Moreover, they lack explicit cross-modal interaction and are vulnerable to noisy support features, further degrading visual prior quality. To address these issues, we propose the Multi-Text Guided Few-Shot Semantic Segmentation Network (MTGNet), a dual-branch framework that enhances segmentation performance by fusing diverse textual prompts to refine textual priors and guide the cross-modal optimization of visual priors. Specifically, we design a Multi-Textual Prior Refinement (MTPR) module that suppresses interference and aggregates complementary semantic cues to enhance foreground activation and expand semantic coverage for structurally complex objects. We introduce a Text Anchor Feature Fusion (TAFF) module, which leverages multi-text embeddings as semantic anchors to facilitate the transfer of discriminative local prototypes from support images to query images, thereby improving semantic consistency and alleviating intra-class variations. Furthermore, a Foreground Confidence-Weighted Attention (FCWA) module is presented to enhance visual prior robustness by leveraging internal self-similarity within support foreground features. It adaptively down-weights inconsistent regions and effectively suppresses interference in the query segmentation process. Extensive experiments on standard FSS benchmarks validate the effectiveness of MTGNet. In the 1-shot setting, it achieves 76.8% mIoU on PASCAL-5i and 57.4% on COCO-20i, with notable improvements in folds exhibiting high intra-class variations.
Melodia: Training-Free Music Editing Guided by Attention Probing in Diffusion Models
Nov 18, 2025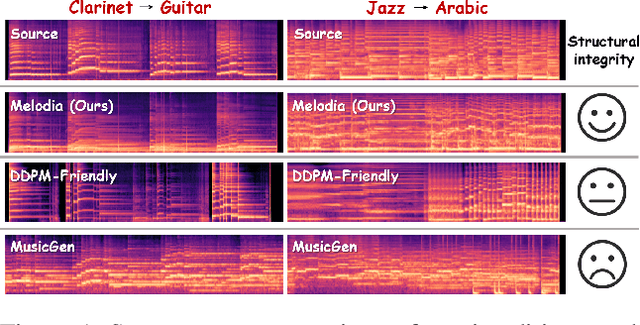
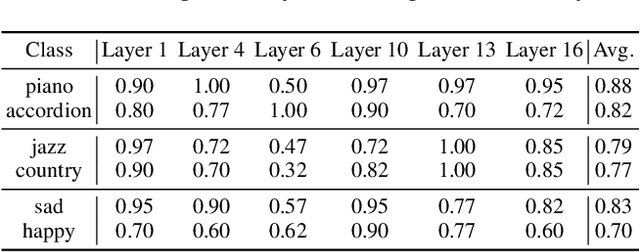
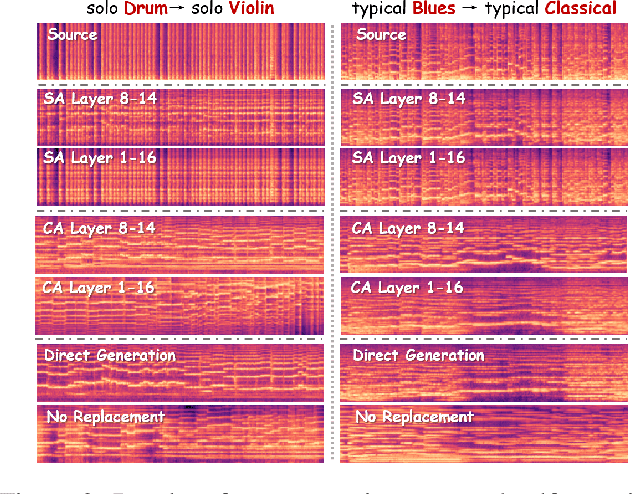
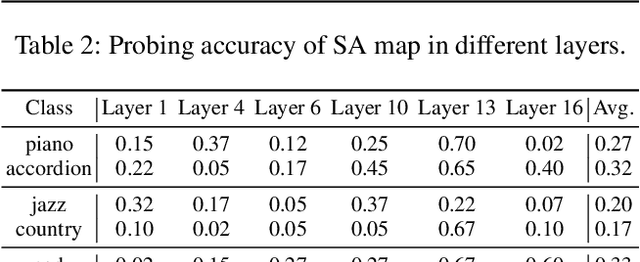
Text-to-music generation technology is progressing rapidly, creating new opportunities for musical composition and editing. However, existing music editing methods often fail to preserve the source music's temporal structure, including melody and rhythm, when altering particular attributes like instrument, genre, and mood. To address this challenge, this paper conducts an in-depth probing analysis on attention maps within AudioLDM 2, a diffusion-based model commonly used as the backbone for existing music editing methods. We reveal a key finding: cross-attention maps encompass details regarding distinct musical characteristics, and interventions on these maps frequently result in ineffective modifications. In contrast, self-attention maps are essential for preserving the temporal structure of the source music during its conversion into the target music. Building upon this understanding, we present Melodia, a training-free technique that selectively manipulates self-attention maps in particular layers during the denoising process and leverages an attention repository to store source music information, achieving accurate modification of musical characteristics while preserving the original structure without requiring textual descriptions of the source music. Additionally, we propose two novel metrics to better evaluate music editing methods. Both objective and subjective experiments demonstrate that our approach achieves superior results in terms of textual adherence and structural integrity across various datasets. This research enhances comprehension of internal mechanisms within music generation models and provides improved control for music creation.
PCA++: How Uniformity Induces Robustness to Background Noise in Contrastive Learning
Nov 15, 2025High-dimensional data often contain low-dimensional signals obscured by structured background noise, which limits the effectiveness of standard PCA. Motivated by contrastive learning, we address the problem of recovering shared signal subspaces from positive pairs, paired observations sharing the same signal but differing in background. Our baseline, PCA+, uses alignment-only contrastive learning and succeeds when background variation is mild, but fails under strong noise or high-dimensional regimes. To address this, we introduce PCA++, a hard uniformity-constrained contrastive PCA that enforces identity covariance on projected features. PCA++ has a closed-form solution via a generalized eigenproblem, remains stable in high dimensions, and provably regularizes against background interference. We provide exact high-dimensional asymptotics in both fixed-aspect-ratio and growing-spike regimes, showing uniformity's role in robust signal recovery. Empirically, PCA++ outperforms standard PCA and alignment-only PCA+ on simulations, corrupted-MNIST, and single-cell transcriptomics, reliably recovering condition-invariant structure. More broadly, we clarify uniformity's role in contrastive learning, showing that explicit feature dispersion defends against structured noise and enhances robustness.
Beyond Uniform Deletion: A Data Value-Weighted Framework for Certified Machine Unlearning
Nov 10, 2025As the right to be forgotten becomes legislated worldwide, machine unlearning mechanisms have emerged to efficiently update models for data deletion and enhance user privacy protection. However, existing machine unlearning algorithms frequently neglect the fact that different data points may contribute unequally to model performance (i.e., heterogeneous data values). Treat them equally in machine unlearning procedure can potentially degrading the performance of updated models. To address this limitation, we propose Data Value-Weighted Unlearning (DVWU), a general unlearning framework that accounts for data value heterogeneity into the unlearning process. Specifically, we design a weighting strategy based on data values, which are then integrated into the unlearning procedure to enable differentiated unlearning for data points with varying utility to the model. The DVWU framework can be broadly adapted to various existing machine unlearning methods. We use the one-step Newton update as an example for implementation, developing both output and objective perturbation algorithms to achieve certified unlearning. Experiments on both synthetic and real-world datasets demonstrate that our methods achieve superior predictive performance and robustness compared to conventional unlearning approaches. We further show the extensibility of our framework on gradient ascent method by incorporating the proposed weighting strategy into the gradient terms, highlighting the adaptability of DVWU for broader gradient-based deep unlearning methods.
Breaking the Modality Barrier: Generative Modeling for Accurate Molecule Retrieval from Mass Spectra
Nov 09, 2025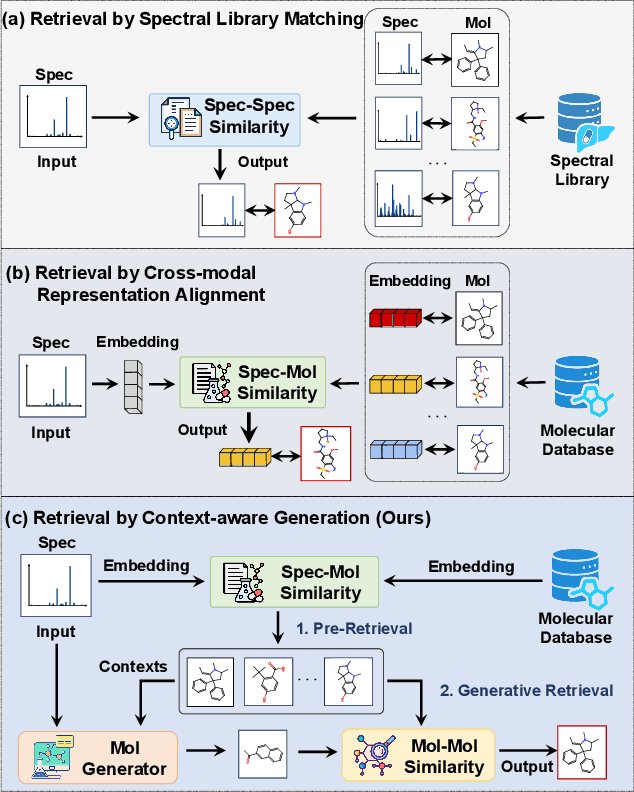



Retrieving molecular structures from tandem mass spectra is a crucial step in rapid compound identification. Existing retrieval methods, such as traditional mass spectral library matching, suffer from limited spectral library coverage, while recent cross-modal representation learning frameworks often encounter modality misalignment, resulting in suboptimal retrieval accuracy and generalization. To address these limitations, we propose GLMR, a Generative Language Model-based Retrieval framework that mitigates the cross-modal misalignment through a two-stage process. In the pre-retrieval stage, a contrastive learning-based model identifies top candidate molecules as contextual priors for the input mass spectrum. In the generative retrieval stage, these candidate molecules are integrated with the input mass spectrum to guide a generative model in producing refined molecular structures, which are then used to re-rank the candidates based on molecular similarity. Experiments on both MassSpecGym and the proposed MassRET-20k dataset demonstrate that GLMR significantly outperforms existing methods, achieving over 40% improvement in top-1 accuracy and exhibiting strong generalizability.
CoMo: Compositional Motion Customization for Text-to-Video Generation
Oct 27, 2025While recent text-to-video models excel at generating diverse scenes, they struggle with precise motion control, particularly for complex, multi-subject motions. Although methods for single-motion customization have been developed to address this gap, they fail in compositional scenarios due to two primary challenges: motion-appearance entanglement and ineffective multi-motion blending. This paper introduces CoMo, a novel framework for $\textbf{compositional motion customization}$ in text-to-video generation, enabling the synthesis of multiple, distinct motions within a single video. CoMo addresses these issues through a two-phase approach. First, in the single-motion learning phase, a static-dynamic decoupled tuning paradigm disentangles motion from appearance to learn a motion-specific module. Second, in the multi-motion composition phase, a plug-and-play divide-and-merge strategy composes these learned motions without additional training by spatially isolating their influence during the denoising process. To facilitate research in this new domain, we also introduce a new benchmark and a novel evaluation metric designed to assess multi-motion fidelity and blending. Extensive experiments demonstrate that CoMo achieves state-of-the-art performance, significantly advancing the capabilities of controllable video generation. Our project page is at https://como6.github.io/.
Moving Beyond Diffusion: Hierarchy-to-Hierarchy Autoregression for fMRI-to-Image Reconstruction
Oct 25, 2025Reconstructing visual stimuli from fMRI signals is a central challenge bridging machine learning and neuroscience. Recent diffusion-based methods typically map fMRI activity to a single high-level embedding, using it as fixed guidance throughout the entire generation process. However, this fixed guidance collapses hierarchical neural information and is misaligned with the stage-dependent demands of image reconstruction. In response, we propose MindHier, a coarse-to-fine fMRI-to-image reconstruction framework built on scale-wise autoregressive modeling. MindHier introduces three components: a Hierarchical fMRI Encoder to extract multi-level neural embeddings, a Hierarchy-to-Hierarchy Alignment scheme to enforce layer-wise correspondence with CLIP features, and a Scale-Aware Coarse-to-Fine Neural Guidance strategy to inject these embeddings into autoregression at matching scales. These designs make MindHier an efficient and cognitively-aligned alternative to diffusion-based methods by enabling a hierarchical reconstruction process that synthesizes global semantics before refining local details, akin to human visual perception. Extensive experiments on the NSD dataset show that MindHier achieves superior semantic fidelity, 4.67x faster inference, and more deterministic results than the diffusion-based baselines.
Dynamic Experts Search: Enhancing Reasoning in Mixture-of-Experts LLMs at Test Time
Sep 26, 2025



Test-Time Scaling (TTS) enhances the reasoning ability of large language models (LLMs) by allocating additional computation during inference. However, existing approaches primarily rely on output-level sampling while overlooking the role of model architecture. In mainstream Mixture-of-Experts (MoE) LLMs, we observe that varying the number of activated experts yields complementary solution sets with stable accuracy, revealing a new and underexplored source of diversity. Motivated by this observation, we propose Dynamic Experts Search (DES), a TTS strategy that elevates expert activation into a controllable dimension of the search space. DES integrates two key components: (1) Dynamic MoE, which enables direct control of expert counts during inference to generate diverse reasoning trajectories without additional cost; and (2) Expert Configuration Inheritance, which preserves consistent expert counts within a reasoning path while varying them across runs, thereby balancing stability and diversity throughout the search. Extensive experiments across MoE architectures, verifiers and reasoning benchmarks (i.e., math, code and knowledge) demonstrate that DES reliably outperforms TTS baselines, enhancing accuracy and stability without additional cost. These results highlight DES as a practical and scalable form of architecture-aware TTS, illustrating how structural flexibility in modern LLMs can advance reasoning.