 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Fixed-Filter Active Noise Control (PFANC) Using Convolutional Recurrent Neural Networks for Dynamic Noises
Jun 06, 2026The existing Generative Fixed-Filter Active Noise Control (GFANC) method generates a suitable control filter based on the current noise frame. This reactive design aims to estimate a control filter that is optimal for the present frame rather than the upcoming one. Consequently, it suffers from an inherent tracking lag and lacks the predictive capability to handle rapidly varying noises. To address this limitation, we propose the Predictive Fixed-Filter Active Noise Control (PFANC) method with a proactive control paradigm in this paper. In the PFANC method, multiple consecutive noise frames are processed by a Convolutional Recurrent Neural Network (CRNN) to predict the next-frame control filter. By utilizing temporal correlations across noise frames to anticipate the control filter in advance, the PFANC method can effectively track dynamic noise changes. Furthermore, the theoretical analysis based on a high-order Markov chain shows that incorporating multiple noise frames enhances the prediction of the control filter. Numerical simulations with linear and logarithmic chirp signals, as well as real-world dynamic noises, validate the effectiveness of the PFANC method and its superiority over GFANC and its variations. The PFANC method also exhibits good transferability across different acoustic paths.
Polyphonia: Zero-Shot Timbre Transfer in Polyphonic Music with Acoustic-Informed Attention Calibration
May 11, 2026The advancement of diffusion-based text-to-music generation has opened new avenues for zero-shot music editing. However, existing methods fail to achieve stem-specific timbre transfer, which requires altering specific stems while strictly preserving the background accompaniment. This limitation severely hinders practical application, since real-world production necessitates precise manipulation of components within dense mixtures. Our key finding is that, while vanilla cross-attention captures semantic features of stems, it lacks the spectral resolution to strictly localize targets in dense mixtures, leading to boundary leakage. To resolve this dilemma, we propose Polyphonia, a zero-shot editing framework with Acoustic-Informed Attention Calibration. Rather than relying solely on diffuse semantic attention, Polyphonia leverages a probabilistic acoustic prior to establish coarse boundaries, enabling non-target stems preserved precise semantic synthesis. For evaluation, we propose PolyEvalPrompts, a standardized prompt set with 1,170 timbre transfer tasks in polyphonic music. Specifically, Polyphonia achieves an increase of 15.5% in target alignment compared to baselines, while maintaining competitive music fidelity and non-target integrity.
Distributed Multichannel Active Noise Control with Asynchronous Communication
Jan 22, 2026Distributed multichannel active noise control (DMCANC) offers effective noise reduction across large spatial areas by distributing the computational load of centralized control to multiple low-cost nodes. Conventional DMCANC methods, however, typically assume synchronous communication and require frequent data exchange, resulting in high communication overhead. To enhance efficiency and adaptability, this work proposes an asynchronous communication strategy where each node executes a weight-constrained filtered-x LMS (WCFxLMS) algorithm and independently requests communication only when its local noise reduction performance degrades. Upon request, other nodes transmit the weight difference between their local control filter and the center point in WCFxLMS, which are then integrated to update both the control filter and the center point. This design enables nodes to operate asynchronously while preserving cooperative behavior. Simulation results demonstrate that the proposed asynchronous communication DMCANC (ACDMCANC) system maintains effective noise reduction with significantly reduced communication load, offering improved scalability for heterogeneous networks.
Directional Selective Fixed-Filter Active Noise Control Based on a Convolutional Neural Network in Reverberant Environments
Jan 11, 2026Selective fixed-filter active noise control (SFANC) is a novel approach capable of mitigating noise with varying frequency characteristics. It offers faster response and greater computational efficiency compared to traditional adaptive algorithms. However, spatial factors, particularly the influence of the noise source location, are often overlooked. Some existing studies have explored the impact of the direction-of-arrival (DoA) of the noise source on ANC performance, but they are mostly limited to free-field conditions and do not consider the more complex indoor reverberant environments. To address this gap, this paper proposes a learning-based directional SFANC method that incorporates the DoA of the noise source in reverberant environments. In this framework, multiple reference signals are processed by a convolutional neural network (CNN) to estimate the azimuth and elevation angles of the noise source, as well as to identify the most appropriate control filter for effective noise cancellation. Compared to traditional adaptive algorithms, the proposed approach achieves superior noise reduction with shorter response times, even in the presence of reverberations.
Melodia: Training-Free Music Editing Guided by Attention Probing in Diffusion Models
Nov 18, 2025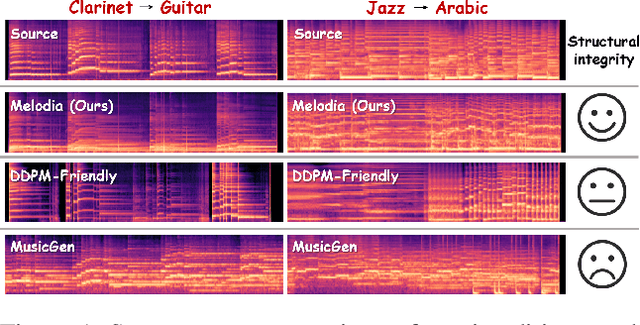
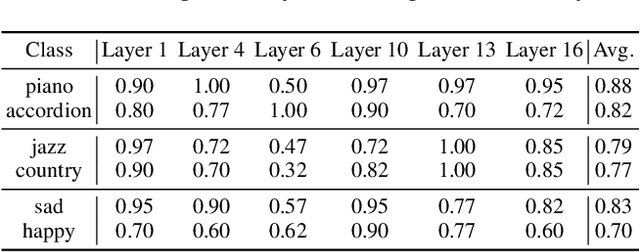
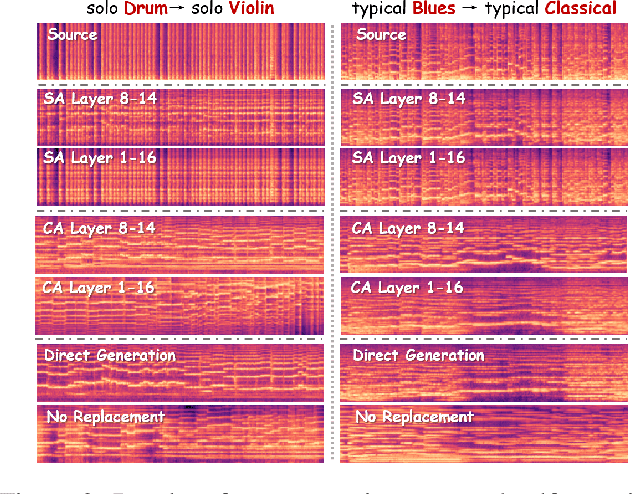
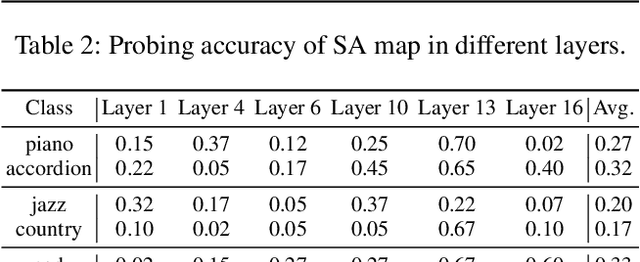
Text-to-music generation technology is progressing rapidly, creating new opportunities for musical composition and editing. However, existing music editing methods often fail to preserve the source music's temporal structure, including melody and rhythm, when altering particular attributes like instrument, genre, and mood. To address this challenge, this paper conducts an in-depth probing analysis on attention maps within AudioLDM 2, a diffusion-based model commonly used as the backbone for existing music editing methods. We reveal a key finding: cross-attention maps encompass details regarding distinct musical characteristics, and interventions on these maps frequently result in ineffective modifications. In contrast, self-attention maps are essential for preserving the temporal structure of the source music during its conversion into the target music. Building upon this understanding, we present Melodia, a training-free technique that selectively manipulates self-attention maps in particular layers during the denoising process and leverages an attention repository to store source music information, achieving accurate modification of musical characteristics while preserving the original structure without requiring textual descriptions of the source music. Additionally, we propose two novel metrics to better evaluate music editing methods. Both objective and subjective experiments demonstrate that our approach achieves superior results in terms of textual adherence and structural integrity across various datasets. This research enhances comprehension of internal mechanisms within music generation models and provides improved control for music creation.
DOA Estimation with Lightweight Network on LLM-Aided Simulated Acoustic Scenes
Nov 11, 2025Direction-of-Arrival (DOA) estimation is critical in spatial audio and acoustic signal processing, with wide-ranging applications in real-world. Most existing DOA models are trained on synthetic data by convolving clean speech with room impulse responses (RIRs), which limits their generalizability due to constrained acoustic diversity. In this paper, we revisit DOA estimation using a recently introduced dataset constructed with the assistance of large language models (LLMs), which provides more realistic and diverse spatial audio scenes. We benchmark several representative neural-based DOA methods on this dataset and propose LightDOA, a lightweight DOA estimation model based on depthwise separable convolutions, specifically designed for mutil-channel input in varying environments. Experimental results show that LightDOA achieves satisfactory accuracy and robustness across various acoustic scenes while maintaining low computational complexity. This study not only highlights the potential of spatial audio synthesized with the assistance of LLMs in advancing robust and efficient DOA estimation research, but also highlights LightDOA as efficient solution for resource-constrained applications.
OpenGuardrails: An Open-Source Context-Aware AI Guardrails Platform
Oct 22, 2025



As large language models (LLMs) become increasingly integrated into real-world applications, safeguarding them against unsafe, malicious, or privacy-violating content is critically important. We present OpenGuardrails, the first open-source project to provide both a context-aware safety and manipulation detection model and a deployable platform for comprehensive AI guardrails. OpenGuardrails protects against content-safety risks, model-manipulation attacks (e.g., prompt injection, jailbreaking, code-interpreter abuse, and the generation/execution of malicious code), and data leakage. Content-safety and model-manipulation detection are implemented by a unified large model, while data-leakage identification and redaction are performed by a separate lightweight NER pipeline (e.g., Presidio-style models or regex-based detectors). The system can be deployed as a security gateway or an API-based service, with enterprise-grade, fully private deployment options. OpenGuardrails achieves state-of-the-art (SOTA) performance on safety benchmarks, excelling in both prompt and response classification across English, Chinese, and multilingual tasks. All models are released under the Apache 2.0 license for public use.
AIComposer: Any Style and Content Image Composition via Feature Integration
Jul 28, 2025Image composition has advanced significantly with large-scale pre-trained T2I diffusion models. Despite progress in same-domain composition, cross-domain composition remains under-explored. The main challenges are the stochastic nature of diffusion models and the style gap between input images, leading to failures and artifacts. Additionally, heavy reliance on text prompts limits practical applications. This paper presents the first cross-domain image composition method that does not require text prompts, allowing natural stylization and seamless compositions. Our method is efficient and robust, preserving the diffusion prior, as it involves minor steps for backward inversion and forward denoising without training the diffuser. Our method also uses a simple multilayer perceptron network to integrate CLIP features from foreground and background, manipulating diffusion with a local cross-attention strategy. It effectively preserves foreground content while enabling stable stylization without a pre-stylization network. Finally, we create a benchmark dataset with diverse contents and styles for fair evaluation, addressing the lack of testing datasets for cross-domain image composition. Our method outperforms state-of-the-art techniques in both qualitative and quantitative evaluations, significantly improving the LPIPS score by 30.5% and the CSD metric by 18.1%. We believe our method will advance future research and applications. Code and benchmark at https://github.com/sherlhw/AIComposer.
Composited-Nested-Learning with Data Augmentation for Nested Named Entity Recognition
Jun 18, 2024



Nested Named Entity Recognition (NNER) focuses on addressing overlapped entity recognition. Compared to Flat Named Entity Recognition (FNER), annotated resources are scarce in the corpus for NNER. Data augmentation is an effective approach to address the insufficient annotated corpus. However, there is a significant lack of exploration in data augmentation methods for NNER. Due to the presence of nested entities in NNER, existing data augmentation methods cannot be directly applied to NNER tasks. Therefore, in this work, we focus on data augmentation for NNER and resort to more expressive structures, Composited-Nested-Label Classification (CNLC) in which constituents are combined by nested-word and nested-label, to model nested entities. The dataset is augmented using the Composited-Nested-Learning (CNL). In addition, we propose the Confidence Filtering Mechanism (CFM) for a more efficient selection of generated data. Experimental results demonstrate that this approach results in improvements in ACE2004 and ACE2005 and alleviates the impact of sample imbalance.
Traffic congestion anomaly detection and prediction using deep learning
Jun 23, 2020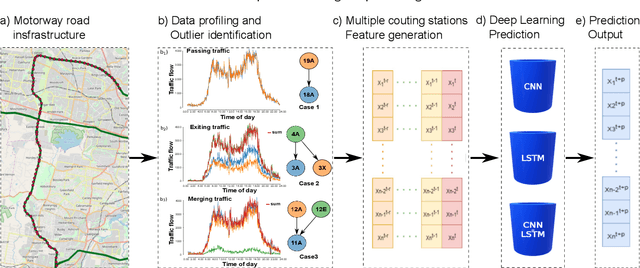

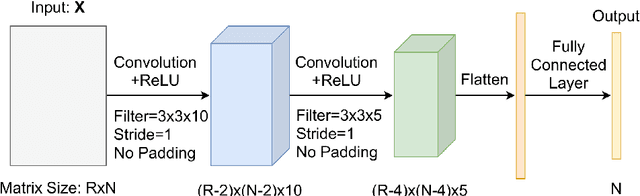
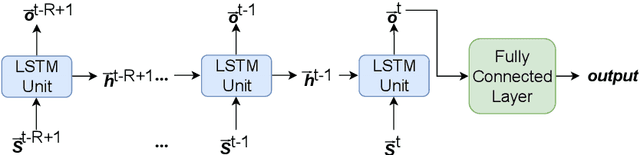
Congestion prediction represents a major priority for traffic management centres around the world to ensure timely incident response handling. The increasing amounts of generated traffic data have been used to train machine learning predictors for traffic, however, this is a challenging task due to inter-dependencies of traffic flow both in time and space. Recently, deep learning techniques have shown significant prediction improvements over traditional models, however, open questions remain around their applicability, accuracy and parameter tuning. This paper brings two contributions in terms of: 1) applying an outlier detection an anomaly adjustment method based on incoming and historical data streams, and 2) proposing an advanced deep learning framework for simultaneously predicting the traffic flow, speed and occupancy on a large number of monitoring stations along a highly circulated motorway in Sydney, Australia, including exit and entry loop count stations, and over varying training and prediction time horizons. The spatial and temporal features extracted from the 36.34 million data points are used in various deep learning architectures that exploit their spatial structure (convolutional neuronal networks), their temporal dynamics (recurrent neuronal networks), or both through a hybrid spatio-temporal modelling (CNN-LSTM). We show that our deep learning models consistently outperform traditional methods, and we conduct a comparative analysis of the optimal time horizon of historical data required to predict traffic flow at different time points in the future. Lastly, we prove that the anomaly adjustment method brings significant improvements to using deep learning in both time and space.