 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyphonia: Zero-Shot Timbre Transfer in Polyphonic Music with Acoustic-Informed Attention Calibration
May 11, 2026The advancement of diffusion-based text-to-music generation has opened new avenues for zero-shot music editing. However, existing methods fail to achieve stem-specific timbre transfer, which requires altering specific stems while strictly preserving the background accompaniment. This limitation severely hinders practical application, since real-world production necessitates precise manipulation of components within dense mixtures. Our key finding is that, while vanilla cross-attention captures semantic features of stems, it lacks the spectral resolution to strictly localize targets in dense mixtures, leading to boundary leakage. To resolve this dilemma, we propose Polyphonia, a zero-shot editing framework with Acoustic-Informed Attention Calibration. Rather than relying solely on diffuse semantic attention, Polyphonia leverages a probabilistic acoustic prior to establish coarse boundaries, enabling non-target stems preserved precise semantic synthesis. For evaluation, we propose PolyEvalPrompts, a standardized prompt set with 1,170 timbre transfer tasks in polyphonic music. Specifically, Polyphonia achieves an increase of 15.5% in target alignment compared to baselines, while maintaining competitive music fidelity and non-target integrity.
iTAG: Inverse Design for Natural Text Generation with Accurate Causal Graph Annotations
Apr 08, 2026A fundamental obstacle to causal discovery from text is the lack of causally annotated text data for use as ground truth, due to high annotation costs. This motivates an important task of generating text with causal graph annotations. Early template-based generation methods sacrifice text naturalness in exchange for high causal graph annotation accuracy. Recent Large Language Model (LLM)-dependent methods directly generate natural text from target graphs through LLMs, but do not guarantee causal graph annotation accuracy. Therefore, we propose iTAG, which performs real-world concept assignment to nodes before converting causal graphs into text in existing LLM-dependent methods. iTAG frames this process as an inverse problem with the causal graph as the target, iteratively examining and refining concept selection through Chain-of-Thought (CoT) reasoning so that the induced relations between concepts are as consistent as possible with the target causal relationships described by the causal graph. iTAG demonstrates both extremely high annotation accuracy and naturalness across extensive tests, and the results of testing text-based causal discovery algorithms with the generated data show high statistical correlation with real-world data. This suggests that iTAG-generated data can serve as a practical surrogate for scalable benchmarking of text-based causal discovery algorithms.
Anchored Cyclic Generation: A Novel Paradigm for Long-Sequence Symbolic Music Generation
Apr 07, 2026Generating long sequences with structural coherence remains a fundamental challenge for autoregressive models across sequential generation tasks. In symbolic music generation, this challenge is particularly pronounced, as existing methods are constrained by the inherent severe error accumulation problem of autoregressive models, leading to poor performance in music quality and structural integrity. In this paper, we propose the Anchored Cyclic Generation (ACG) paradigm, which relies on anchor features from already identified music to guide subsequent generation during the autoregressive process, effectively mitigating error accumulation in autoregressive methods. Based on the ACG paradigm, we further propose the Hierarchical Anchored Cyclic Generation (Hi-ACG) framework, which employs a systematic global-to-local generation strategy and is highly compatible with our specifically designed piano token, an efficient musical representation. The experimental results demonstrate that compared to traditional autoregressive models, the ACG paradigm achieves reduces cosine distance by an average of 34.7% between predicted feature vectors and ground-truth semantic vectors. In long-sequence symbolic music generation tasks, the Hi-ACG framework significantly outperforms existing mainstream methods in both subjective and objective evaluations. Furthermore, the framework exhibits excellent task generalization capabilities, achieving superior performance in related tasks such as music completion.
Pianoroll-Event: A Novel Score Representation for Symbolic Music
Jan 26, 2026Symbolic music representation is a fundamental challenge in computational musicology. While grid-based representations effectively preserve pitch-time spatial correspondence, their inherent data sparsity leads to low encoding efficiency. Discrete-event representations achieve compact encoding but fail to adequately capture structural invariance and spatial locality. To address these complementary limitations, we propose Pianoroll-Event, a novel encoding scheme that describes pianoroll representations through events, combining structural properties with encoding efficiency while maintaining temporal dependencies and local spatial patterns. Specifically, we design four complementary event types: Frame Events for temporal boundaries, Gap Events for sparse regions, Pattern Events for note patterns, and Musical Structure Events for musical metadata. Pianoroll-Event strikes an effective balance between sequence length and vocabulary size, improving encoding efficiency by 1.36\times to 7.16\times over representative discrete sequence methods. Experiments across multiple autoregressive architectures show models using our representation consistently outperform baselines in both quantitative and human evaluations.
Melodia: Training-Free Music Editing Guided by Attention Probing in Diffusion Models
Nov 18, 2025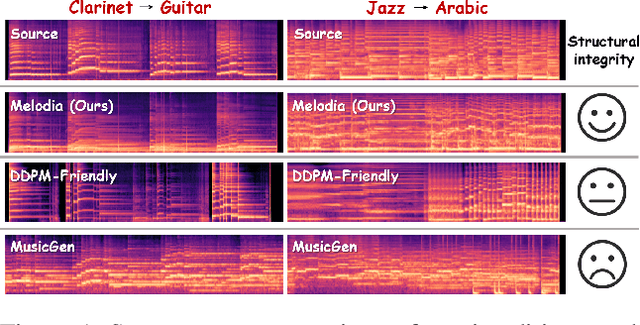
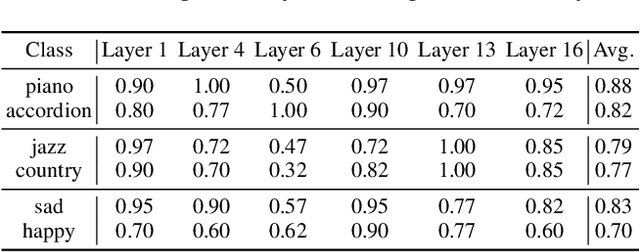
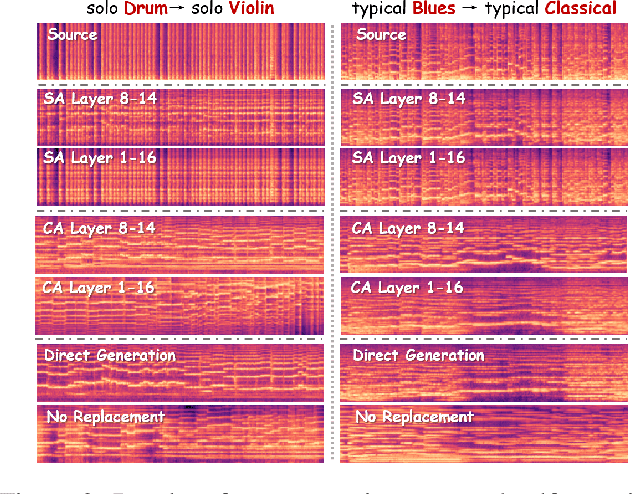
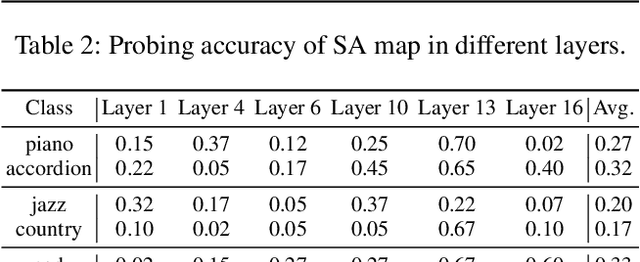
Text-to-music generation technology is progressing rapidly, creating new opportunities for musical composition and editing. However, existing music editing methods often fail to preserve the source music's temporal structure, including melody and rhythm, when altering particular attributes like instrument, genre, and mood. To address this challenge, this paper conducts an in-depth probing analysis on attention maps within AudioLDM 2, a diffusion-based model commonly used as the backbone for existing music editing methods. We reveal a key finding: cross-attention maps encompass details regarding distinct musical characteristics, and interventions on these maps frequently result in ineffective modifications. In contrast, self-attention maps are essential for preserving the temporal structure of the source music during its conversion into the target music. Building upon this understanding, we present Melodia, a training-free technique that selectively manipulates self-attention maps in particular layers during the denoising process and leverages an attention repository to store source music information, achieving accurate modification of musical characteristics while preserving the original structure without requiring textual descriptions of the source music. Additionally, we propose two novel metrics to better evaluate music editing methods. Both objective and subjective experiments demonstrate that our approach achieves superior results in terms of textual adherence and structural integrity across various datasets. This research enhances comprehension of internal mechanisms within music generation models and provides improved control for music creation.