 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARM: Advantage Reward Modeling for Long-Horizon Manipulation
Apr 03, 2026Long-horizon robotic manipulation remains challenging for reinforcement learning (RL) because sparse rewards provide limited guidance for credit assignment. Practical policy improvement thus relies on richer intermediate supervision, such as dense progress rewards, which are costly to obtain and ill-suited to non-monotonic behaviors such as backtracking and recovery. To address this, we propose Advantage Reward Modeling (ARM), a framework that shifts from hard-to-quantify absolute progress to estimating relative advantage. We introduce a cost-effective tri-state labeling strategy -- Progressive, Regressive, and Stagnant -- that reduces human cognitive overhead while ensuring high cross-annotator consistency. By training on these intuitive signals, ARM enables automated progress annotation for both complete demonstrations and fragmented DAgger-style data. Integrating ARM into an offline RL pipeline allows for adaptive action-reward reweighting, effectively filtering suboptimal samples. Our approach achieves a 99.4% success rate on a challenging long-horizon towel-folding task, demonstrating improved stability and data efficiency over current VLA baselines with near-zero human intervention during policy training.
See Once, Then Act: Vision-Language-Action Model with Task Learning from One-Shot Video Demonstrations
Dec 08, 2025Developing robust and general-purpose manipulation policies represents a fundamental objective in robotics research. While Vision-Language-Action (VLA) models have demonstrated promising capabilities for end-to-end robot control, existing approaches still exhibit limited generalization to tasks beyond their training distributions. In contrast, humans possess remarkable proficiency in acquiring novel skills by simply observing others performing them once. Inspired by this capability, we propose ViVLA, a generalist robotic manipulation policy that achieves efficient task learning from a single expert demonstration video at test time. Our approach jointly processes an expert demonstration video alongside the robot's visual observations to predict both the demonstrated action sequences and subsequent robot actions, effectively distilling fine-grained manipulation knowledge from expert behavior and transferring it seamlessly to the agent. To enhance the performance of ViVLA, we develop a scalable expert-agent pair data generation pipeline capable of synthesizing paired trajectories from easily accessible human videos, further augmented by curated pairs from publicly available datasets. This pipeline produces a total of 892,911 expert-agent samples for training ViVLA. Experimental results demonstrate that our ViVLA is able to acquire novel manipulation skills from only a single expert demonstration video at test time. Our approach achieves over 30% improvement on unseen LIBERO tasks and maintains above 35% gains with cross-embodiment videos. Real-world experiments demonstrate effective learning from human videos, yielding more than 38% improvement on unseen tasks.
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Oct 08, 2024



We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{https://gr2-manipulation.github.io}.
ClickSeg: 3D Instance Segmentation with Click-Level Weak Annotations
Jul 19, 2023



3D instance segmentation methods often require fully-annotated dense labels for training, which are costly to obtain. In this paper, we present ClickSeg, a novel click-level weakly supervised 3D instance segmentation method that requires one point per instance annotation merely. Such a problem is very challenging due to the extremely limited labels, which has rarely been solved before. We first develop a baseline weakly-supervised training method, which generates pseudo labels for unlabeled data by the model itself. To utilize the property of click-level annotation setting, we further propose a new training framework. Instead of directly using the model inference way, i.e., mean-shift clustering, to generate the pseudo labels, we propose to use k-means with fixed initial seeds: the annotated points. New similarity metrics are further designed for clustering. Experiments on ScanNetV2 and S3DIS datasets show that the proposed ClickSeg surpasses the previous best weakly supervised instance segmentation result by a large margin (e.g., +9.4% mAP on ScanNetV2). Using 0.02% supervision signals merely, ClickSeg achieves $\sim$90% of the accuracy of the fully-supervised counterpart. Meanwhile, it also achieves state-of-the-art semantic segmentation results among weakly supervised methods that use the same annotation settings.
Navigating to Objects in Unseen Environments by Distance Prediction
Feb 08, 2022
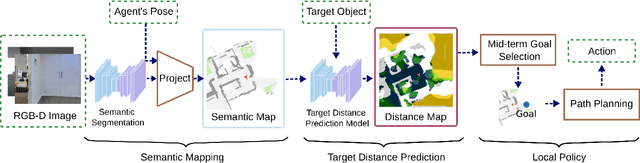
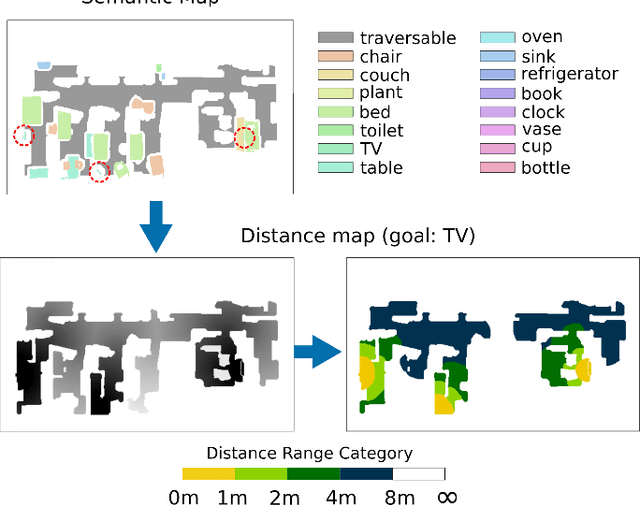
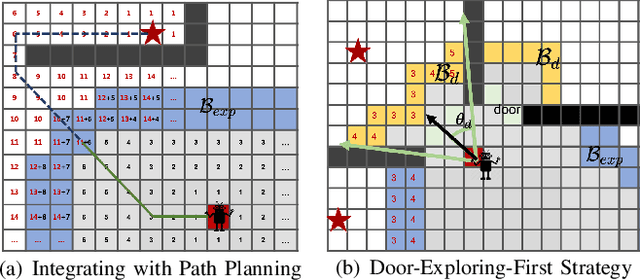
Object Goal Navigation (ObjectNav) task is to navigate an agent to an object instance in unseen environments. The traditional navigation paradigm plans the shortest path on a pre-built map. Inspired by this, we propose an object goal navigation framework, which could directly perform path planning based on an estimated distance map. Specifically, our model takes a birds-eye-view semantic map as input, and estimates the distance from the map cells to the target object based on the learned prior knowledge. With the estimated distance map, the agent could explore the environment and navigate to the target objects based on either human-designed or learned navigation policy. Empirical results in visually realistic simulation environments show that the proposed method outperforms a wide range of baselines on success rate and efficiency.