 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoINR: Cross-View Geometry Consistent Stereo Super Resolution with Implicit Neural Representation
May 07, 2025Stereo image super-resolution (SSR) aims to enhance high-resolution details by leveraging information from stereo image pairs. However, existing stereo super-resolution (SSR) upsampling methods (e.g., pixel shuffle) often overlook cross-view geometric consistency and are limited to fixed-scale upsampling. The key issue is that previous upsampling methods use convolution to independently process deep features of different views, lacking cross-view and non-local information perception, making it difficult to select beneficial information from multi-view scenes adaptively. In this work, we propose Stereo Implicit Neural Representation (StereoINR), which innovatively models stereo image pairs as continuous implicit representations. This continuous representation breaks through the scale limitations, providing a unified solution for arbitrary-scale stereo super-resolution reconstruction of left-right views. Furthermore, by incorporating spatial warping and cross-attention mechanisms, StereoINR enables effective cross-view information fusion and achieves significant improvements in pixel-level geometric consistency. Extensive experiments across multiple datasets show that StereoINR outperforms out-of-training-distribution scale upsampling and matches state-of-the-art SSR methods within training-distribution scales.
RISE: Radius of Influence based Subgraph Extraction for 3D Molecular Graph Explanation
May 04, 20253D Geometric Graph Neural Networks (GNNs) have emerged as transformative tools for modeling molecular data. Despite their predictive power, these models often suffer from limited interpretability, raising concerns for scientific applications that require reliable and transparent insights. While existing methods have primarily focused on explaining molecular substructures in 2D GNNs, the transition to 3D GNNs introduces unique challenges, such as handling the implicit dense edge structures created by a cut-off radius. To tackle this, we introduce a novel explanation method specifically designed for 3D GNNs, which localizes the explanation to the immediate neighborhood of each node within the 3D space. Each node is assigned an radius of influence, defining the localized region within which message passing captures spatial and structural interactions crucial for the model's predictions. This method leverages the spatial and geometric characteristics inherent in 3D graphs. By constraining the subgraph to a localized radius of influence, the approach not only enhances interpretability but also aligns with the physical and structural dependencies typical of 3D graph applications, such as molecular learning.
A Rusty Link in the AI Supply Chain: Detecting Evil Configurations in Model Repositories
May 02, 2025

Recent advancements in large language models (LLMs) have spurred the development of diverse AI applications from code generation and video editing to text generation; however, AI supply chains such as Hugging Face, which host pretrained models and their associated configuration files contributed by the public, face significant security challenges; in particular, configuration files originally intended to set up models by specifying parameters and initial settings can be exploited to execute unauthorized code, yet research has largely overlooked their security compared to that of the models themselves; in this work, we present the first comprehensive study of malicious configurations on Hugging Face, identifying three attack scenarios (file, website, and repository operations) that expose inherent risks; to address these threats, we introduce CONFIGSCAN, an LLM-based tool that analyzes configuration files in the context of their associated runtime code and critical libraries, effectively detecting suspicious elements with low false positive rates and high accuracy; our extensive evaluation uncovers thousands of suspicious repositories and configuration files, underscoring the urgent need for enhanced security validation in AI model hosting platforms.
GenTorrent: Scaling Large Language Model Serving with An Overley Network
Apr 30, 2025While significant progress has been made in research and development on open-source and cost-efficient large-language models (LLMs), serving scalability remains a critical challenge, particularly for small organizations and individuals seeking to deploy and test their LLM innovations. Inspired by peer-to-peer networks that leverage decentralized overlay nodes to increase throughput and availability, we propose GenTorrent, an LLM serving overlay that harnesses computing resources from decentralized contributors. We identify four key research problems inherent to enabling such a decentralized infrastructure: 1) overlay network organization; 2) LLM communication privacy; 3) overlay forwarding for resource efficiency; and 4) verification of serving quality. This work presents the first systematic study of these fundamental problems in the context of decentralized LLM serving. Evaluation results from a prototype implemented on a set of decentralized nodes demonstrate that GenTorrent achieves a latency reduction of over 50% compared to the baseline design without overlay forwarding. Furthermore, the security features introduce minimal overhead to serving latency and throughput. We believe this work pioneers a new direction for democratizing and scaling future AI serving capabilities.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
asKAN: Active Subspace embedded Kolmogorov-Arnold Network
Apr 09, 2025



The Kolmogorov-Arnold Network (KAN) has emerged as a promising neural network architecture for small-scale AI+Science applications. However, it suffers from inflexibility in modeling ridge functions, which is widely used in representing the relationships in physical systems. This study investigates this inflexibility through the lens of the Kolmogorov-Arnold theorem, which starts the representation of multivariate functions from constructing the univariate components rather than combining the independent variables. Our analysis reveals that incorporating linear combinations of independent variables can substantially simplify the network architecture in representing the ridge functions. Inspired by this finding, we propose active subspace embedded KAN (asKAN), a hierarchical framework that synergizes KAN's function representation with active subspace methodology. The architecture strategically embeds active subspace detection between KANs, where the active subspace method is used to identify the primary ridge directions and the independent variables are adaptively projected onto these critical dimensions. The proposed asKAN is implemented in an iterative way without increasing the number of neurons in the original KAN. The proposed method is validated through function fitting, solving the Poisson equation, and reconstructing sound field. Compared with KAN, asKAN significantly reduces the error using the same network architecture. The results suggest that asKAN enhances the capability of KAN in fitting and solving equations in the form of ridge functions.
Leveraging Robust Optimization for LLM Alignment under Distribution Shifts
Apr 08, 2025Large language models (LLMs) increasingly rely on preference alignment methods to steer outputs toward human values, yet these methods are often constrained by the scarcity of high-quality human-annotated data. To tackle this, recent approaches have turned to synthetic data generated by LLMs as a scalable alternative. However, synthetic data can introduce distribution shifts, compromising the nuanced human preferences that are essential for desirable outputs. In this paper, we propose a novel distribution-aware optimization framework that improves preference alignment in the presence of such shifts. Our approach first estimates the likelihood ratios between the target and training distributions leveraging a learned classifier, then it minimizes the worst-case loss over data regions that reflect the target human-preferred distribution. By explicitly prioritizing the target distribution during optimization, our method mitigates the adverse effects of distributional variation and enhances the generation of responses that faithfully reflect human values.
MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs
Apr 01, 2025

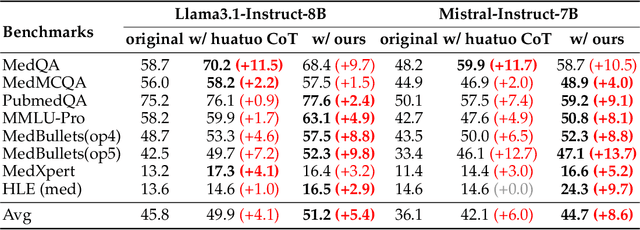
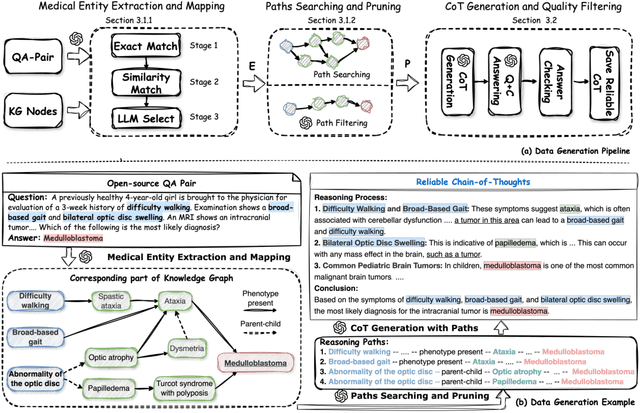
Medical tasks such as diagnosis and treatment planning require precise and complex reasoning, particularly in life-critical domains. Unlike mathematical reasoning, medical reasoning demands meticulous, verifiable thought processes to ensure reliability and accuracy. However, there is a notable lack of datasets that provide transparent, step-by-step reasoning to validate and enhance the medical reasoning ability of AI models. To bridge this gap, we introduce MedReason, a large-scale high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in large language models (LLMs). We utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or ``thinking paths'', which trace connections from question elements to answers via relevant KG entities. Each path is validated for consistency with clinical logic and evidence-based medicine. Our pipeline generates detailed reasoning for various medical questions from 7 medical datasets, resulting in a dataset of 32,682 question-answer pairs, each with detailed, step-by-step explanations. Experiments demonstrate that fine-tuning with our dataset consistently boosts medical problem-solving capabilities, achieving significant gains of up to 7.7% for DeepSeek-Ditill-8B. Our top-performing model, MedReason-8B, outperforms the Huatuo-o1-8B, a state-of-the-art medical reasoning model, by up to 4.2% on the clinical benchmark MedBullets. We also engage medical professionals from diverse specialties to assess our dataset's quality, ensuring MedReason offers accurate and coherent medical reasoning. Our data, models, and code will be publicly available.
Effective Cloud Removal for Remote Sensing Images by an Improved Mean-Reverting Denoising Model with Elucidated Design Space
Mar 31, 2025



Cloud removal (CR) remains a challenging task in remote sensing image processing. Although diffusion models (DM) exhibit strong generative capabilities, their direct applications to CR are suboptimal, as they generate cloudless images from random noise, ignoring inherent information in cloudy inputs. To overcome this drawback, we develop a new CR model EMRDM based on mean-reverting diffusion models (MRDMs) to establish a direct diffusion process between cloudy and cloudless images. Compared to current MRDMs, EMRDM offers a modular framework with updatable modules and an elucidated design space, based on a reformulated forward process and a new ordinary differential equation (ODE)-based backward process. Leveraging our framework, we redesign key MRDM modules to boost CR performance, including restructuring the denoiser via a preconditioning technique, reorganizing the training process, and improving the sampling process by introducing deterministic and stochastic samplers. To achieve multi-temporal CR, we further develop a denoising network for simultaneously denoising sequential images. Experiments on mono-temporal and multi-temporal datasets demonstrate the superior performance of EMRDM. Our code is available at https://github.com/Ly403/EMRDM.
PP-DocLayout: A Unified Document Layout Detection Model to Accelerate Large-Scale Data Construction
Mar 21, 2025



Document layout analysis is a critical preprocessing step in document intelligence, enabling the detection and localization of structural elements such as titles, text blocks, tables, and formulas. Despite its importance, existing layout detection models face significant challenges in generalizing across diverse document types, handling complex layouts, and achieving real-time performance for large-scale data processing. To address these limitations, we present PP-DocLayout, which achieves high precision and efficiency in recognizing 23 types of layout regions across diverse document formats. To meet different needs, we offer three models of varying scales. PP-DocLayout-L is a high-precision model based on the RT-DETR-L detector, achieving 90.4% mAP@0.5 and an end-to-end inference time of 13.4 ms per page on a T4 GPU. PP-DocLayout-M is a balanced model, offering 75.2% mAP@0.5 with an inference time of 12.7 ms per page on a T4 GPU. PP-DocLayout-S is a high-efficiency model designed for resource-constrained environments and real-time applications, with an inference time of 8.1 ms per page on a T4 GPU and 14.5 ms on a CPU. This work not only advances the state of the art in document layout analysis but also provides a robust solution for constructing high-quality training data, enabling advancements in document intelligence and multimodal AI systems. Code and models are available at https://github.com/PaddlePaddle/PaddleX .