 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Lifelong Understanding: A Dataset and Agentic Baseline
Mar 05, 2026While datasets for video understanding have scaled to hour-long durations, they typically consist of densely concatenated clips that differ from natural, unscripted daily life. To bridge this gap, we introduce MM-Lifelong, a dataset designed for Multimodal Lifelong Understanding. Comprising 181.1 hours of footage, it is structured across Day, Week, and Month scales to capture varying temporal densities. Extensive evaluations reveal two critical failure modes in current paradigms: end-to-end MLLMs suffer from a Working Memory Bottleneck due to context saturation, while representative agentic baselines experience Global Localization Collapse when navigating sparse, month-long timelines. To address this, we propose the Recursive Multimodal Agent (ReMA), which employs dynamic memory management to iteratively update a recursive belief state, significantly outperforming existing methods. Finally, we establish dataset splits designed to isolate temporal and domain biases, providing a rigorous foundation for future research in supervised learning and out-of-distribution generalization.
EgoLoc: A Generalizable Solution for Temporal Interaction Localization in Egocentric Videos
Aug 17, 2025Analyzing hand-object interaction in egocentric vision facilitates VR/AR applications and human-robot policy transfer. Existing research has mostly focused on modeling the behavior paradigm of interactive actions (i.e., ``how to interact''). However, the more challenging and fine-grained problem of capturing the critical moments of contact and separation between the hand and the target object (i.e., ``when to interact'') is still underexplored, which is crucial for immersive interactive experiences in mixed reality and robotic motion planning. Therefore, we formulate this problem as temporal interaction localization (TIL). Some recent works extract semantic masks as TIL references, but suffer from inaccurate object grounding and cluttered scenarios. Although current temporal action localization (TAL) methods perform well in detecting verb-noun action segments, they rely on category annotations during training and exhibit limited precision in localizing hand-object contact/separation moments. To address these issues, we propose a novel zero-shot approach dubbed EgoLoc to localize hand-object contact and separation timestamps in egocentric videos. EgoLoc introduces hand-dynamics-guided sampling to generate high-quality visual prompts. It exploits the vision-language model to identify contact/separation attributes, localize specific timestamps, and provide closed-loop feedback for further refinement. EgoLoc eliminates the need for object masks and verb-noun taxonomies, leading to generalizable zero-shot implementation. Comprehensive experiments on the public dataset and our novel benchmarks demonstrate that EgoLoc achieves plausible TIL for egocentric videos. It is also validated to effectively facilitate multiple downstream applications in egocentric vision and robotic manipulation tasks. Code and relevant data will be released at https://github.com/IRMVLab/EgoLoc.
VideoLLM: Modeling Video Sequence with Large Language Models
May 23, 2023



With the exponential growth of video data, there is an urgent need for automated technology to analyze and comprehend video content. However, existing video understanding models are often task-specific and lack a comprehensive capability of handling diverse tasks. The success of large language models (LLMs) like GPT has demonstrated their impressive abilities in sequence causal reasoning. Building upon this insight, we propose a novel framework called VideoLLM that leverages the sequence reasoning capabilities of pre-trained LLMs from natural language processing (NLP) for video sequence understanding. VideoLLM incorporates a carefully designed Modality Encoder and Semantic Translator, which convert inputs from various modalities into a unified token sequence. This token sequence is then fed into a decoder-only LLM. Subsequently, with the aid of a simple task head, our VideoLLM yields an effective unified framework for different kinds of video understanding tasks. To evaluate the efficacy of VideoLLM, we conduct extensive experiments using multiple LLMs and fine-tuning methods. We evaluate our VideoLLM on eight tasks sourced from four different datasets. The experimental results demonstrate that the understanding and reasoning capabilities of LLMs can be effectively transferred to video understanding tasks. We release the code at https://github.com/cg1177/VideoLLM.
MRSN: Multi-Relation Support Network for Video Action Detection
Apr 24, 2023



Action detection is a challenging video understanding task, requiring modeling spatio-temporal and interaction relations. Current methods usually model actor-actor and actor-context relations separately, ignoring their complementarity and mutual support. To solve this problem, we propose a novel network called Multi-Relation Support Network (MRSN). In MRSN, Actor-Context Relation Encoder (ACRE) and Actor-Actor Relation Encoder (AARE) model the actor-context and actor-actor relation separately. Then Relation Support Encoder (RSE) computes the supports between the two relations and performs relation-level interactions. Finally, Relation Consensus Module (RCM) enhances two relations with the long-term relations from the Long-term Relation Bank (LRB) and yields a consensus. Our experiments demonstrate that modeling relations separately and performing relation-level interactions can achieve and outperformer state-of-the-art results on two challenging video datasets: AVA and UCF101-24.
InternVideo-Ego4D: A Pack of Champion Solutions to Ego4D Challenges
Nov 17, 2022



In this report, we present our champion solutions to five tracks at Ego4D challenge. We leverage our developed InternVideo, a video foundation model, for five Ego4D tasks, including Moment Queries, Natural Language Queries, Future Hand Prediction, State Change Object Detection, and Short-term Object Interaction Anticipation. InternVideo-Ego4D is an effective paradigm to adapt the strong foundation model to the downstream ego-centric video understanding tasks with simple head designs. In these five tasks, the performance of InternVideo-Ego4D comprehensively surpasses the baseline methods and the champions of CVPR2022, demonstrating the powerful representation ability of InternVideo as a video foundation model. Our code will be released at https://github.com/OpenGVLab/ego4d-eccv2022-solutions
Exploring Detection-based Method For Speaker Diarization @ Ego4D Audio-only Diarization Challenge 2022
Nov 16, 2022
We provide the technical report for Ego4D audio-only diarization challenge in ECCV 2022. Speaker diarization takes the audio streams as input and outputs the homogeneous segments according to the speaker's identity. It aims to solve the problem of "Who spoke when." In this paper, we explore a Detection-based method to tackle the audio-only speaker diarization task. Our method first extracts audio features by audio backbone and then feeds the feature to a detection-generate network to get the speaker proposals. Finally, after postprocessing, we can get the diarization results. The validation dataset validates this method, and our method achieves 53.85 DER on the test dataset. These results rank 3rd on the leaderboard of Ego4D audio-only diarization challenge 2022.
Exploring State Change Capture of Heterogeneous Backbones @ Ego4D Hands and Objects Challenge 2022
Nov 16, 2022



Capturing the state changes of interacting objects is a key technology for understanding human-object interactions. This technical report describes our method using heterogeneous backbones for the Ego4D Object State Change Classification and PNR Temporal Localization Challenge. In the challenge, we used the heterogeneous video understanding backbones, namely CSN with 3D convolution as operator and VideoMAE with Transformer as operator. Our method achieves an accuracy of 0.796 on OSCC while achieving an absolute temporal localization error of 0.516 on PNR. These excellent results rank 1st on the leaderboard of Ego4D OSCC & PNR-TL Challenge 2022.
Uncertainty-based Network for Few-shot Image Classification
May 17, 2022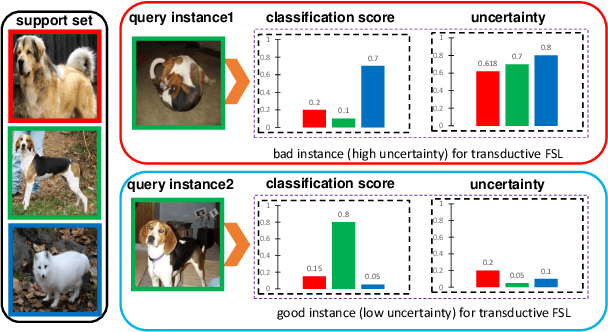
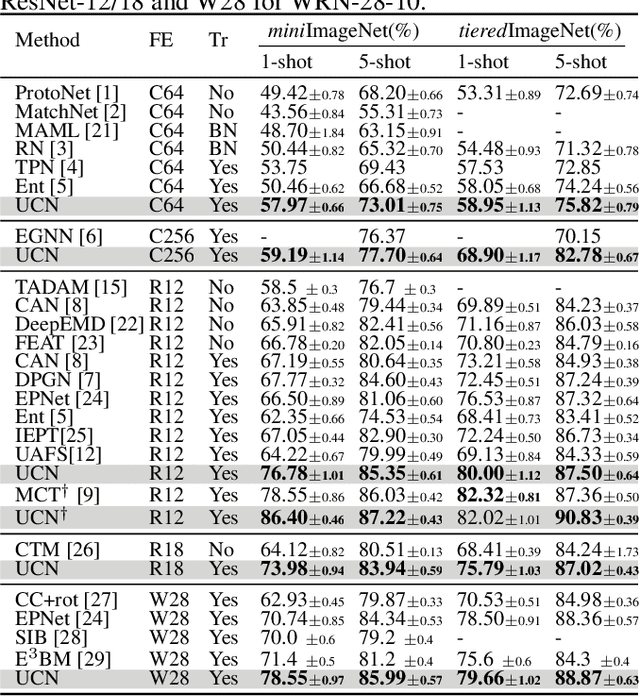
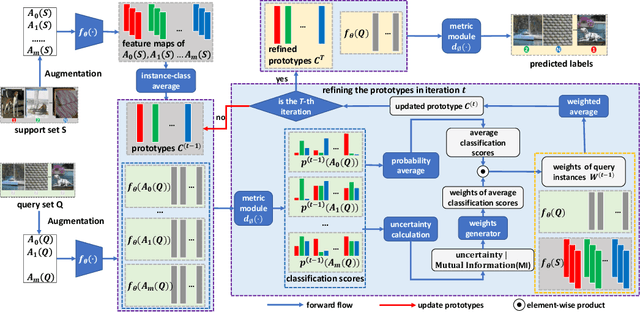
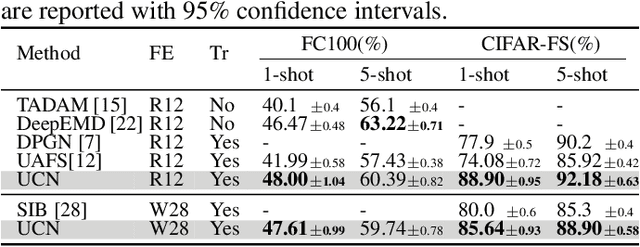
The transductive inference is an effective technique in the few-shot learning task, where query sets update prototypes to improve themselves. However, these methods optimize the model by considering only the classification scores of the query instances as confidence while ignoring the uncertainty of these classification scores. In this paper, we propose a novel method called Uncertainty-Based Network, which models the uncertainty of classification results with the help of mutual information. Specifically, we first data augment and classify the query instance and calculate the mutual information of these classification scores. Then, mutual information is used as uncertainty to assign weights to classification scores, and the iterative update strategy based on classification scores and uncertainties assigns the optimal weights to query instances in prototype optimization. Extensive results on four benchmarks show that Uncertainty-Based Network achieves comparable performance in classification accuracy compared to state-of-the-art method.
BasicTAD: an Astounding RGB-Only Baseline for Temporal Action Detection
May 05, 2022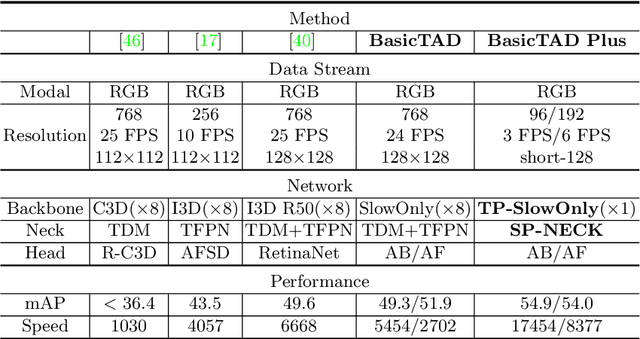
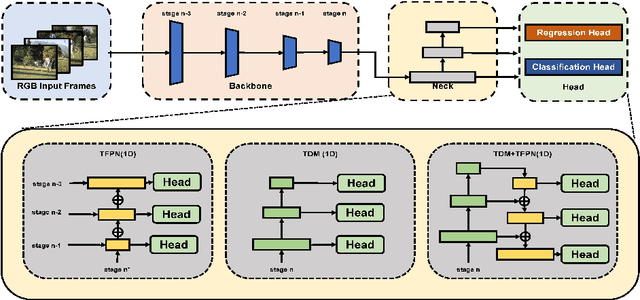
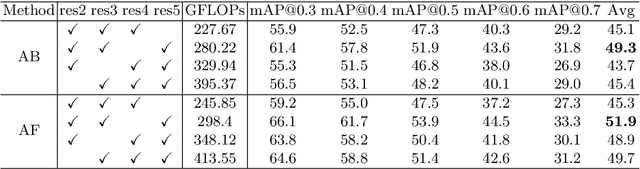
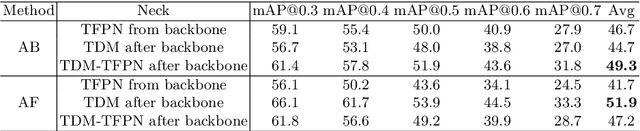
Temporal action detection (TAD) is extensively studied in the video understanding community by following the object detection pipelines in images. However, complex designs are not uncommon in TAD, such as two-stream feature extraction, multi-stage training, complex temporal modeling, and global context fusion. In this paper, we do not aim to introduce any novel technique for TAD. Instead, we study a simple, straightforward, yet must-known baseline given the current status of complex design and low efficiency in TAD. In our simple baseline (BasicTAD), we decompose the TAD pipeline into several essential components: data sampling, backbone design, neck construction, and detection head. We empirically investigate the existing techniques in each component for this baseline and, more importantly, perform end-to-end training over the entire pipeline thanks to the simplicity in design. Our BasicTAD yields an astounding RGB-Only baseline very close to the state-of-the-art methods with two-stream inputs. In addition, we further improve the BasicTAD by preserving more temporal and spatial information in network representation (termed as BasicTAD Plus). Empirical results demonstrate that our BasicTAD Plus is very efficient and significantly outperforms the previous methods on the datasets of THUMOS14 and FineAction. Our approach can serve as a strong baseline for TAD. The code will be released at https://github.com/MCG-NJU/BasicTAD.
DCAN: Improving Temporal Action Detection via Dual Context Aggregation
Dec 07, 2021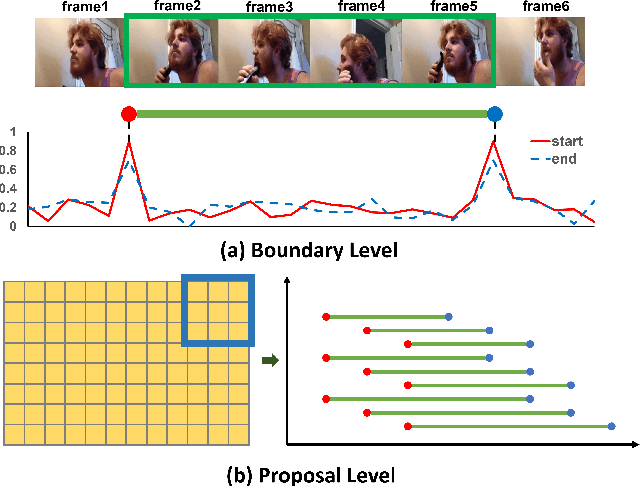
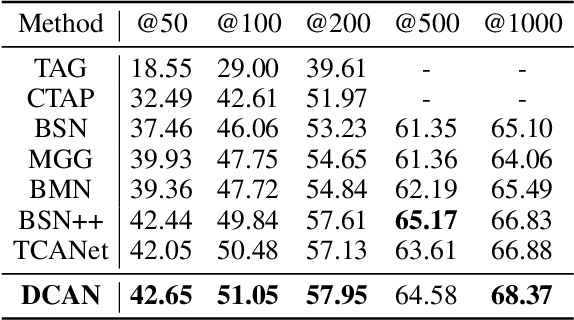
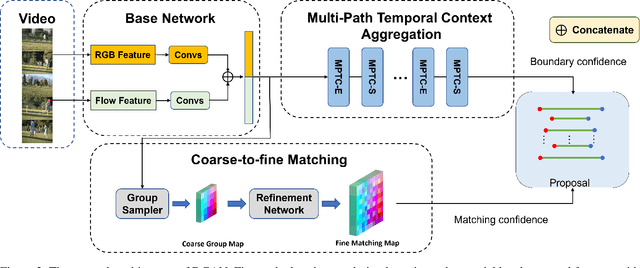
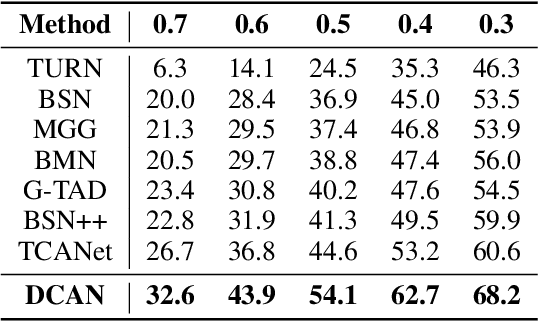
Temporal action detection aims to locate the boundaries of action in the video. The current method based on boundary matching enumerates and calculates all possible boundary matchings to generate proposals. However, these methods neglect the long-range context aggregation in boundary prediction. At the same time, due to the similar semantics of adjacent matchings, local semantic aggregation of densely-generated matchings cannot improve semantic richness and discrimination. In this paper, we propose the end-to-end proposal generation method named Dual Context Aggregation Network (DCAN) to aggregate context on two levels, namely, boundary level and proposal level, for generating high-quality action proposals, thereby improving the performance of temporal action detection. Specifically, we design the Multi-Path Temporal Context Aggregation (MTCA) to achieve smooth context aggregation on boundary level and precise evaluation of boundaries. For matching evaluation, Coarse-to-fine Matching (CFM) is designed to aggregate context on the proposal level and refine the matching map from coarse to fine. We conduct extensive experiments on ActivityNet v1.3 and THUMOS-14. DCAN obtains an average mAP of 35.39% on ActivityNet v1.3 and reaches mAP 54.14% at IoU@0.5 on THUMOS-14, which demonstrates DCAN can generate high-quality proposals and achieve state-of-the-art performance. We release the code at https://github.com/cg1177/DCAN.