 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMooER: LLM-based Speech Recognition and Translation Models from Moore Threads
Aug 09, 2024In this paper, we present MooER, a LLM-based large-scale automatic speech recognition (ASR) / automatic speech translation (AST) model of Moore Threads. A 5000h pseudo labeled dataset containing open source and self collected speech data is used for training. We achieve performance comparable to other open source models trained with up to hundreds of thousands of hours of labeled speech data. Meanwhile, experiments conducted on Covost2 Zh2en testset suggest that our model outperforms other open source Speech LLMs. A BLEU score of 25.2 can be obtained. The main contributions of this paper are summarized as follows. First, this paper presents a training strategy for encoders and LLMs on speech related tasks (including ASR and AST) using a small size of pseudo labeled data without any extra manual annotation and selection. Second, we release our ASR and AST models and plan to open-source our training code and strategy in the near future. Moreover, a model trained on 8wh scale training data is planned to be released later on.
Token-level Speaker Change Detection Using Speaker Difference and Speech Content via Continuous Integrate-and-fire
Nov 17, 2022In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to segment the audio and then transcribe each segmentation. These two stages are addressed separately by speaker change detection (SCD) and automatic speech recognition (ASR). Most previous SCD systems rely solely on speaker information and ignore the importance of speech content. In this paper, we propose a novel SCD system that considers both cues of speaker difference and speech content. These two cues are converted into token-level representations by the continuous integrate-and-fire (CIF) mechanism and then combined for detecting speaker changes on the token acoustic boundaries. We evaluate the performance of our approach on a public real-recorded meeting dataset, AISHELL-4. The experiment results show that our method outperforms a competitive frame-level baseline system by 2.45% equal coverage-purity (ECP). In addition, we demonstrate the importance of speech content and speaker difference to the SCD task, and the advantages of conducting SCD on the token acoustic boundaries compared with conducting SCD frame by frame.
Improving End-to-End Contextual Speech Recognition with Fine-grained Contextual Knowledge Selection
Jan 30, 2022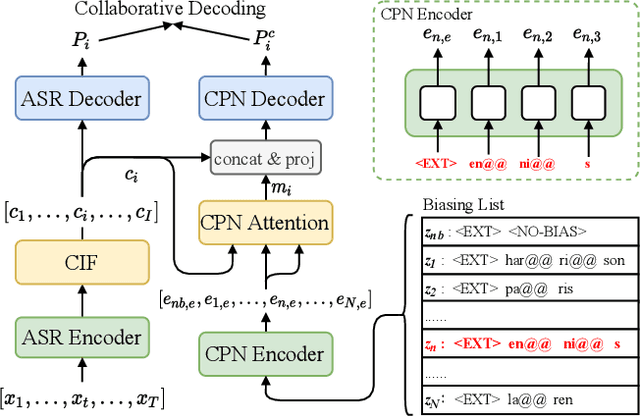
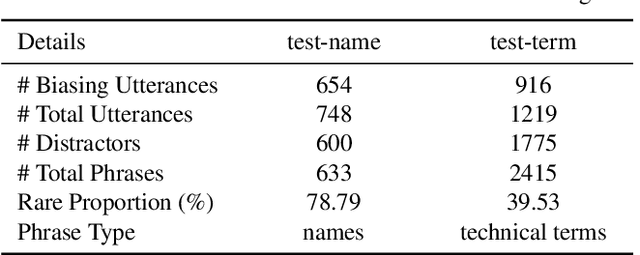
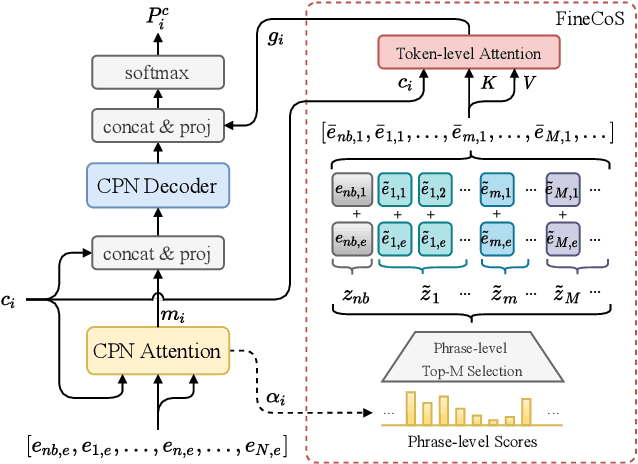
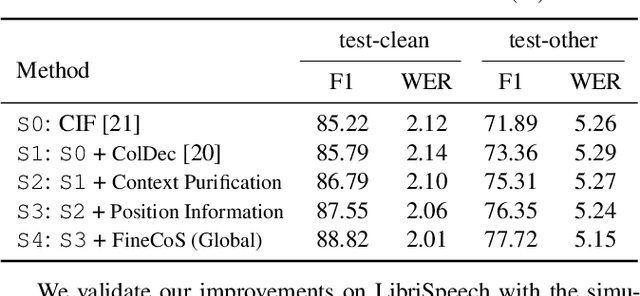
Nowadays, most methods in end-to-end contextual speech recognition bias the recognition process towards contextual knowledge. Since all-neural contextual biasing methods rely on phrase-level contextual modeling and attention-based relevance modeling, they may encounter confusion between similar context-specific phrases, which hurts predictions at the token level. In this work, we focus on mitigating confusion problems with fine-grained contextual knowledge selection (FineCoS). In FineCoS, we introduce fine-grained knowledge to reduce the uncertainty of token predictions. Specifically, we first apply phrase selection to narrow the range of phrase candidates, and then conduct token attention on the tokens in the selected phrase candidates. Moreover, we re-normalize the attention weights of most relevant phrases in inference to obtain more focused phrase-level contextual representations, and inject position information to better discriminate phrases or tokens. On LibriSpeech and an in-house 160,000-hour dataset, we explore the proposed methods based on a controllable all-neural biasing method, collaborative decoding (ColDec). The proposed methods provide at most 6.1% relative word error rate reduction on LibriSpeech and 16.4% relative character error rate reduction on the in-house dataset over ColDec.