 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
Oct 30, 2025



Multimodal reasoning requires iterative coordination between language and vision, yet it remains unclear what constitutes a meaningful interleaved chain of thought. We posit that text and image thoughts should function as complementary, rather than isomorphic, modalities that mutually advance reasoning. Guided by this principle, we build ThinkMorph, a unified model fine-tuned on 24K high-quality interleaved reasoning traces spanning tasks with varying visual engagement. ThinkMorph learns to generate progressive text-image reasoning steps that concretely manipulate visual content while maintaining coherent verbal logic. It delivers large gains on vision-centric benchmarks (averaging 34.7% over the base model) and generalizes to out-of-domain tasks, matching or surpassing larger and proprietary VLMs. Beyond performance, ThinkMorph exhibits emergent multimodal intelligence, including unseen visual manipulation skills, adaptive switching between reasoning modes, and better test-time scaling through diversified multimodal thoughts.These findings suggest promising directions for characterizing the emergent capabilities of unified models for multimodal reasoning.
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Oct 27, 2025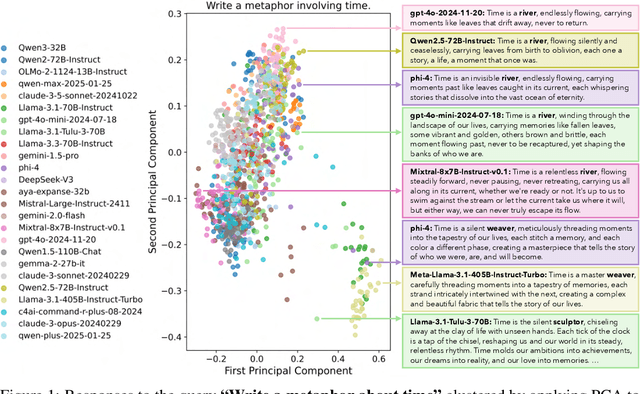
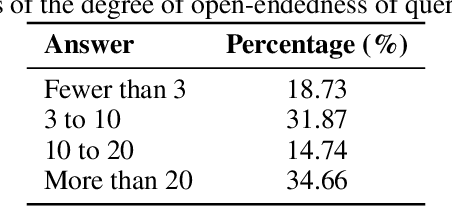
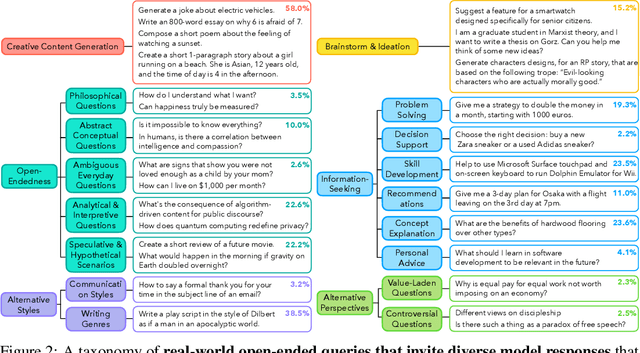
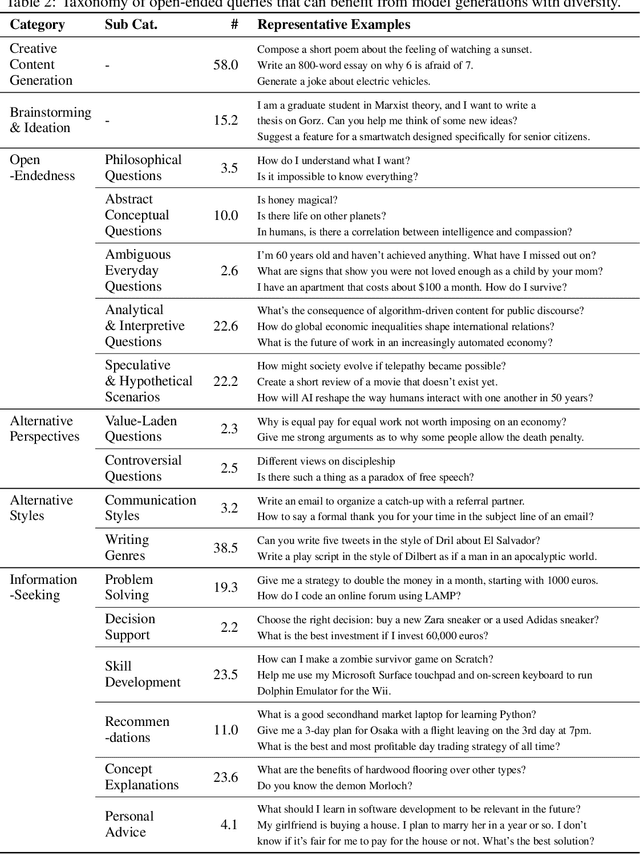
Language models (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.
ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Oct 21, 2025

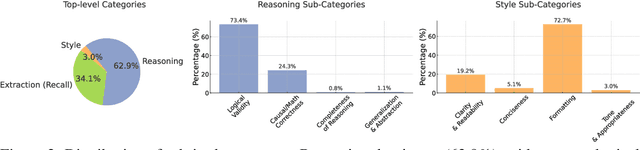
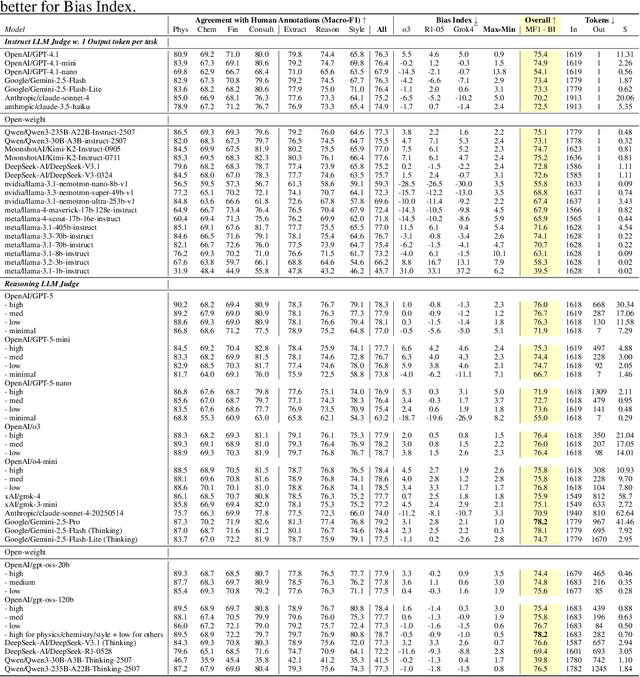
Evaluating progress in large language models (LLMs) is often constrained by the challenge of verifying responses, limiting assessments to tasks like mathematics, programming, and short-form question-answering. However, many real-world applications require evaluating LLMs in processing professional documents, synthesizing information, and generating comprehensive reports in response to user queries. We introduce ProfBench: a set of over 7000 response-criterion pairs as evaluated by human-experts with professional knowledge across Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA. We build robust and affordable LLM-Judges to evaluate ProfBench rubrics, by mitigating self-enhancement bias and reducing the cost of evaluation by 2-3 orders of magnitude, to make it fair and accessible to the broader community. Our findings reveal that ProfBench poses significant challenges even for state-of-the-art LLMs, with top-performing models like GPT-5-high achieving only 65.9\% overall performance. Furthermore, we identify notable performance disparities between proprietary and open-weight models and provide insights into the role that extended thinking plays in addressing complex, professional-domain tasks. Data: https://huggingface.co/datasets/nvidia/ProfBench and Code: https://github.com/NVlabs/ProfBench
Opt-ICL at LeWiDi-2025: Maximizing In-Context Signal from Rater Examples via Meta-Learning
Oct 08, 2025Many natural language processing (NLP) tasks involve subjectivity, ambiguity, or legitimate disagreement between annotators. In this paper, we outline our system for modeling human variation. Our system leverages language models' (LLMs) in-context learning abilities, along with a two-step meta-learning training procedure for 1) post-training on many datasets requiring in-context learning and 2) specializing the model via in-context meta-learning to the particular data distribution of interest. We also evaluate the performance of our system submission to the Learning With Disagreements (LeWiDi) competition, where it was the overall winner on both tasks. Additionally, we perform an ablation study to measure the importance of each system component. We find that including rater examples in-context is crucial for our system's performance, dataset-specific fine-tuning is helpful on the larger datasets, post-training on other in-context datasets is helpful on one of the competition datasets, and that performance improves with model scale.
From Supervision to Exploration: What Does Protein Language Model Learn During Reinforcement Learning?
Oct 02, 2025Protein language models (PLMs) have advanced computational protein science through large-scale pretraining and scalable architectures. In parallel, reinforcement learning (RL) has broadened exploration and enabled precise multi-objective optimization in protein design. Yet whether RL can push PLMs beyond their pretraining priors to uncover latent sequence-structure-function rules remains unclear. We address this by pairing RL with PLMs across four domains: antimicrobial peptide design, kinase variant optimization, antibody engineering, and inverse folding. Using diverse RL algorithms and model classes, we ask if RL improves sampling efficiency and, more importantly, if it reveals capabilities not captured by supervised learning. Across benchmarks, RL consistently boosts success rates and sample efficiency. Performance follows a three-factor interaction: task headroom, reward fidelity, and policy capacity jointly determine gains. When rewards are accurate and informative, policies have sufficient capacity, and tasks leave room beyond supervised baselines, improvements scale; when rewards are noisy or capacity is constrained, gains saturate despite exploration. This view yields practical guidance for RL in protein design: prioritize reward modeling and calibration before scaling policy size, match algorithm and regularization strength to task difficulty, and allocate capacity where marginal gains are largest. Implementation is available at https://github.com/chq1155/RL-PLM.
Learning Human-Perceived Fakeness in AI-Generated Videos via Multimodal LLMs
Sep 26, 2025Can humans identify AI-generated (fake) videos and provide grounded reasons? While video generation models have advanced rapidly, a critical dimension -- whether humans can detect deepfake traces within a generated video, i.e., spatiotemporal grounded visual artifacts that reveal a video as machine generated -- has been largely overlooked. We introduce DeeptraceReward, the first fine-grained, spatially- and temporally- aware benchmark that annotates human-perceived fake traces for video generation reward. The dataset comprises 4.3K detailed annotations across 3.3K high-quality generated videos. Each annotation provides a natural-language explanation, pinpoints a bounding-box region containing the perceived trace, and marks precise onset and offset timestamps. We consolidate these annotations into 9 major categories of deepfake traces that lead humans to identify a video as AI-generated, and train multimodal language models (LMs) as reward models to mimic human judgments and localizations. On DeeptraceReward, our 7B reward model outperforms GPT-5 by 34.7% on average across fake clue identification, grounding, and explanation. Interestingly, we observe a consistent difficulty gradient: binary fake v.s. real classification is substantially easier than fine-grained deepfake trace detection; within the latter, performance degrades from natural language explanations (easiest), to spatial grounding, to temporal labeling (hardest). By foregrounding human-perceived deepfake traces, DeeptraceReward provides a rigorous testbed and training signal for socially aware and trustworthy video generation.
Bias in Gender Bias Benchmarks: How Spurious Features Distort Evaluation
Sep 09, 2025



Gender bias in vision-language foundation models (VLMs) raises concerns about their safe deployment and is typically evaluated using benchmarks with gender annotations on real-world images. However, as these benchmarks often contain spurious correlations between gender and non-gender features, such as objects and backgrounds, we identify a critical oversight in gender bias evaluation: Do spurious features distort gender bias evaluation? To address this question, we systematically perturb non-gender features across four widely used benchmarks (COCO-gender, FACET, MIAP, and PHASE) and various VLMs to quantify their impact on bias evaluation. Our findings reveal that even minimal perturbations, such as masking just 10% of objects or weakly blurring backgrounds, can dramatically alter bias scores, shifting metrics by up to 175% in generative VLMs and 43% in CLIP variants. This suggests that current bias evaluations often reflect model responses to spurious features rather than gender bias, undermining their reliability. Since creating spurious feature-free benchmarks is fundamentally challenging, we recommend reporting bias metrics alongside feature-sensitivity measurements to enable a more reliable bias assessment.
UQ: Assessing Language Models on Unsolved Questions
Aug 25, 2025Benchmarks shape progress in AI research. A useful benchmark should be both difficult and realistic: questions should challenge frontier models while also reflecting real-world usage. Yet, current paradigms face a difficulty-realism tension: exam-style benchmarks are often made artificially difficult with limited real-world value, while benchmarks based on real user interaction often skew toward easy, high-frequency problems. In this work, we explore a radically different paradigm: assessing models on unsolved questions. Rather than a static benchmark scored once, we curate unsolved questions and evaluate models asynchronously over time with validator-assisted screening and community verification. We introduce UQ, a testbed of 500 challenging, diverse questions sourced from Stack Exchange, spanning topics from CS theory and math to sci-fi and history, probing capabilities including reasoning, factuality, and browsing. UQ is difficult and realistic by construction: unsolved questions are often hard and naturally arise when humans seek answers, thus solving them yields direct real-world value. Our contributions are threefold: (1) UQ-Dataset and its collection pipeline combining rule-based filters, LLM judges, and human review to ensure question quality (e.g., well-defined and difficult); (2) UQ-Validators, compound validation strategies that leverage the generator-validator gap to provide evaluation signals and pre-screen candidate solutions for human review; and (3) UQ-Platform, an open platform where experts collectively verify questions and solutions. The top model passes UQ-validation on only 15% of questions, and preliminary human verification has already identified correct answers among those that passed. UQ charts a path for evaluating frontier models on real-world, open-ended challenges, where success pushes the frontier of human knowledge. We release UQ at https://uq.stanford.edu.
Zero-shot Multimodal Document Retrieval via Cross-modal Question Generation
Aug 23, 2025Rapid advances in Multimodal Large Language Models (MLLMs) have expanded information retrieval beyond purely textual inputs, enabling retrieval from complex real world documents that combine text and visuals. However, most documents are private either owned by individuals or confined within corporate silos and current retrievers struggle when faced with unseen domains or languages. To address this gap, we introduce PREMIR, a simple yet effective framework that leverages the broad knowledge of an MLLM to generate cross modal pre questions (preQs) before retrieval. Unlike earlier multimodal retrievers that compare embeddings in a single vector space, PREMIR leverages preQs from multiple complementary modalities to expand the scope of matching to the token level. Experiments show that PREMIR achieves state of the art performance on out of distribution benchmarks, including closed domain and multilingual settings, outperforming strong baselines across all retrieval metrics. We confirm the contribution of each component through in depth ablation studies, and qualitative analyses of the generated preQs further highlight the model's robustness in real world settings.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.