 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXAONE 4.5 Technical Report
Apr 09, 2026This technical report introduces EXAONE 4.5, the first open-weight vision language model released by LG AI Research. EXAONE 4.5 is architected by integrating a dedicated visual encoder into the existing EXAONE 4.0 framework, enabling native multimodal pretraining over both visual and textual modalities. The model is trained on large-scale data with careful curation, particularly emphasizing document-centric corpora that align with LG's strategic application domains. This targeted data design enables substantial performance gains in document understanding and related tasks, while also delivering broad improvements across general language capabilities. EXAONE 4.5 extends context length up to 256K tokens, facilitating long-context reasoning and enterprise-scale use cases. Comparative evaluations demonstrate that EXAONE 4.5 achieves competitive performance in general benchmarks while outperforming state-of-the-art models of similar scale in document understanding and Korean contextual reasoning. As part of LG's ongoing effort toward practical industrial deployment, EXAONE 4.5 is designed to be continuously extended with additional domains and application scenarios to advance AI for a better life.
BenchPreS: A Benchmark for Context-Aware Personalized Preference Selectivity of Persistent-Memory LLMs
Mar 17, 2026Large language models (LLMs) increasingly store user preferences in persistent memory to support personalization across interactions. However, in third-party communication settings governed by social and institutional norms, some user preferences may be inappropriate to apply. We introduce BenchPreS, which evaluates whether memory-based user preferences are appropriately applied or suppressed across communication contexts. Using two complementary metrics, Misapplication Rate (MR) and Appropriate Application Rate (AAR), we find even frontier LLMs struggle to apply preferences in a context-sensitive manner. Models with stronger preference adherence exhibit higher rates of over-application, and neither reasoning capability nor prompt-based defenses fully resolve this issue. These results suggest current LLMs treat personalized preferences as globally enforceable rules rather than as context-dependent normative signals.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
Verifying the Verifiers: Unveiling Pitfalls and Potentials in Fact Verifiers
Jun 16, 2025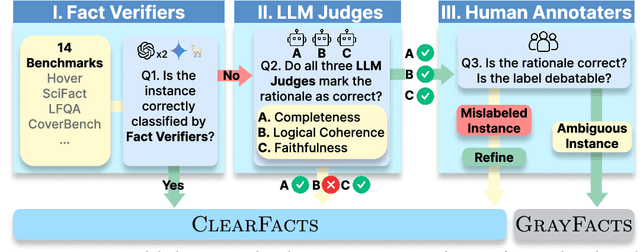

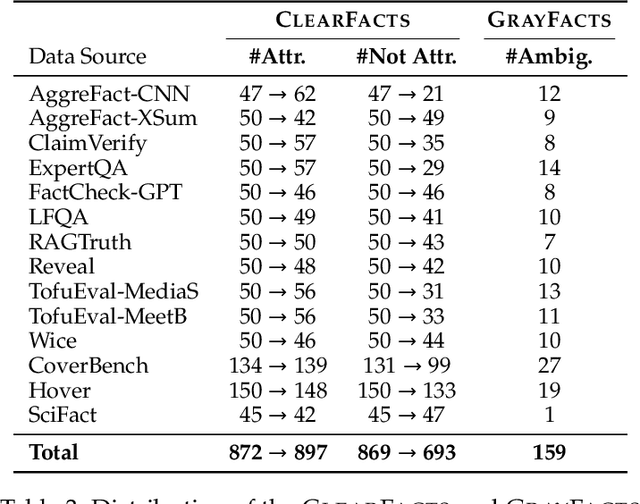
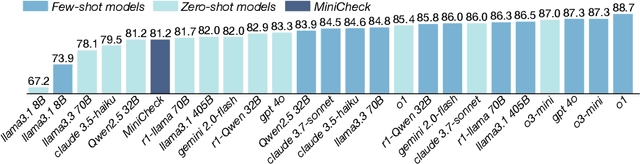
Fact verification is essential for ensuring the reliability of LLM applications. In this study, we evaluate 12 pre-trained LLMs and one specialized fact-verifier, including frontier LLMs and open-weight reasoning LLMs, using a collection of examples from 14 fact-checking benchmarks. We share three findings intended to guide future development of more robust fact verifiers. First, we highlight the importance of addressing annotation errors and ambiguity in datasets, demonstrating that approximately 16\% of ambiguous or incorrectly labeled data substantially influences model rankings. Neglecting this issue may result in misleading conclusions during comparative evaluations, and we suggest using a systematic pipeline utilizing LLM-as-a-judge to help identify these issues at scale. Second, we discover that frontier LLMs with few-shot in-context examples, often overlooked in previous works, achieve top-tier performance. We therefore recommend future studies include comparisons with these simple yet highly effective baselines. Lastly, despite their effectiveness, frontier LLMs incur substantial costs, motivating the development of small, fine-tuned fact verifiers. We show that these small models still have room for improvement, particularly on instances that require complex reasoning. Encouragingly, we demonstrate that augmenting training with synthetic multi-hop reasoning data significantly enhances their capabilities in such instances. We release our code, model, and dataset at https://github.com/just1nseo/verifying-the-verifiers
Layout-and-Retouch: A Dual-stage Framework for Improving Diversity in Personalized Image Generation
Jul 13, 2024



Personalized text-to-image (P-T2I) generation aims to create new, text-guided images featuring the personalized subject with a few reference images. However, balancing the trade-off relationship between prompt fidelity and identity preservation remains a critical challenge. To address the issue, we propose a novel P-T2I method called Layout-and-Retouch, consisting of two stages: 1) layout generation and 2) retouch. In the first stage, our step-blended inference utilizes the inherent sample diversity of vanilla T2I models to produce diversified layout images, while also enhancing prompt fidelity. In the second stage, multi-source attention swapping integrates the context image from the first stage with the reference image, leveraging the structure from the context image and extracting visual features from the reference image. This achieves high prompt fidelity while preserving identity characteristics. Through our extensive experiments, we demonstrate that our method generates a wide variety of images with diverse layouts while maintaining the unique identity features of the personalized objects, even with challenging text prompts. This versatility highlights the potential of our framework to handle complex conditions, significantly enhancing the diversity and applicability of personalized image synthesis.